聚类算法和一个改进方法介绍
Saurav是一名数据科学爱好者,目前他在新德里MAIT大学就读,还有一年即将毕业。他擅长使用机器学习和分析的方法来解决复杂的数据问题。
目录
- 概观
- 聚类的类型
- 聚类算法的类型
- K意味着集群
- 分层聚类
- K均值与分层聚类的区别
- 聚类的应用
- 用聚类来改进监督学习算法
1. 概览
聚类算法是完成一个将若干数据点进行临近分组的任务,这个任务使在距离上相互临近的数据点归为一组。简单来说,就是将相似的数据进行归类处理。
先举一个简单的例子来理解,假设你是一家租赁店的负责人,并希望了解你的顾客的喜好,以便于扩大你的业务销量。你能否做到查看每一个客户的详细信息并为他们每个人都制定一套个性化的业务策略?那肯定做不到,因为那样工作量实在是太大了。但是你可以做的是根据他们的购买习惯将所有的顾客聚集成10个小组,并在这10个小组的每个小组中使用单独的策略。这就是我们刚才说的的聚类方法。
那现在我们已经了解了什么是聚类。让我们来看看聚类有哪些类型
2. Types ofClustering
聚类的种类
一般来说,聚类可以分为两组类型:
- 硬聚类:在硬聚类中,每个数据点都完全确定属于一个分组,或者不属于这个分组,没有模糊的中间情况。举例说,向上文的提到的那种情况,将每一个客户都放在10组之中,不会有一个客户同时属于两个分组
- 软聚类:在软聚类中,不是将每个数据点都要放入一个单独的分组中,而是计算该数据点位于这些聚类分组中的概率或可能性。例如,从上述情景中可以描述为:每个顾客被分配一个在10个分组中每一个的概率。
3. Types ofclustering algorithms
聚类算法的类型
由于聚类的任务是主观的,可以用来实现这个目标的方法有很多。每种方法都遵循一套不同的规则来定义数据点之间的“ 相似性”。目前,已知有100多种聚类算法。但很少有算法被广泛使用,我们来看一看它们:
- 连接模型:顾名思义,这些模型是基于这样的概念,即数据空间中,如果定义为彼此距离较近的数据点,那他们的之间的距离比距离较远的数据点更近。这些模型可以采用两种方法。在第一种方法中,他们首先将所有单个数据点归为集合,然后在距离减小时将这些集合聚合。在第二个方法中,所有数据点被分类为单个群集,然后随着距离的增加而进行分区。而且,距离函数的选择是主观的。所以,这些模型是非常容易解释的,但缺乏处理大数据集的可伸缩性。这些模型的例子就是层次聚类算法及其变体。
- 质心模型:这些是迭代聚类算法,其中相似性的概念是通过数据点与聚类质心的接近性得出的。K-Means聚类算法是一种流行的算法,就是属于这一类。最后需要使用的数据集必须事先准备出来,事先得知这些数据集很重要,因为这些模型迭代运行才以找到局部最优值。
- 分布模型: 这些聚类模型基于一个集群中所有数据点属于相同分布的可能性的概念(例如:正则分布和高斯分布)。这些模型经常会遇到过拟合的问题,那这些模型的一个常用的解决办法是使用最大化多元正态分布期望算法。
- 密度模型: 这些模型在数据空间中搜索数据空间中不同密度数据点的区域。它隔离各种不同的密度区域,并将这些区域内的数据点分配到同一个群集中。密度模型的典型例子是DBSCAN和OPTICS。
现在我将详细介绍两种最流行的聚类算法 - K均值聚类和分层聚类。让看一下吧。
4. K-Means 聚类
K均值是一种迭代聚类算法,旨在找到每次迭代中的局部最大值。该算法有这5个关键步骤:
- 指定所需数量的聚类K:在平面空间的5个数据点中,k值选择为2
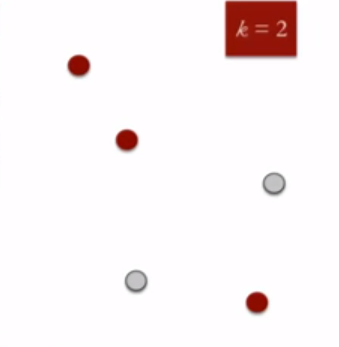{kind=link}
- 将每个数据点随机分配到一个集合中:我们将3个点放在集合一中用红色来表示,将两个数据点放在集合2中用灰色来表示。
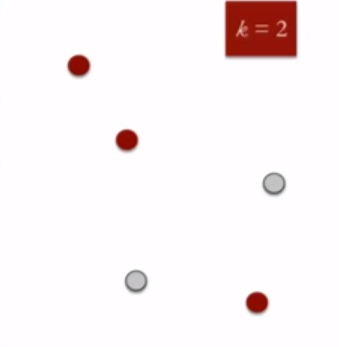{kind=link}
- 计算集合的质心:红色集合中数据点的质心使用红色叉号表示,灰色群组中使用灰色叉号表示。
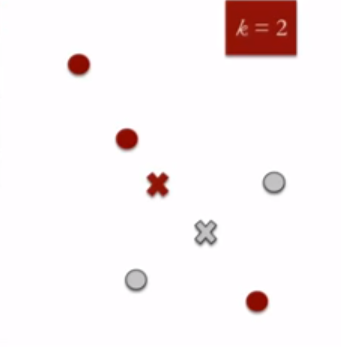{kind=link}
- 将每个点重新分配到最近的集群质心:要注意的是,虽然底部的那个数据点被分配给红色集群,但是是它靠近灰色集群的质心。因此,我们将该数据点分配到灰色群集中
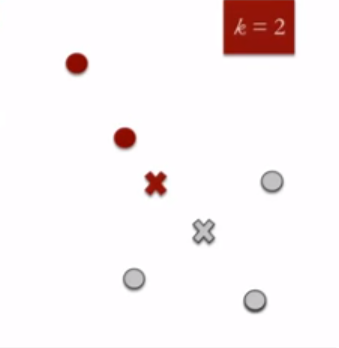{kind=link}
- 重新计算集群质心:现在,重新计算两个集群的质心。
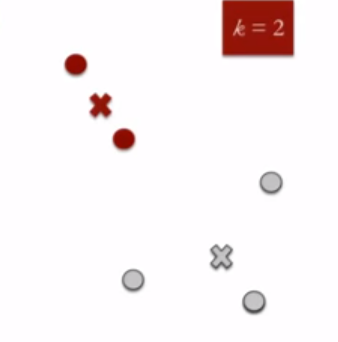{kind=link}
- 重复步骤4和5,直到不能再迭代位置:同样,我们会重复4 次和5 次的步骤,直到我们达到全局最优解。当两个连续重复的两个集合之间不会在更改集合的中心时结束。
5. 分层聚类
顾名思义,分层聚类是一种构建聚类层次结构的算法。该算法从分配给它们自己的一个集群的所有数据点开始。然后将两个最近的集群合并到同一个集群中。最后,当只剩下一个集合时,该算法终止。
可以使用树状图来显示分层聚类的结果。树状图可以表现为:
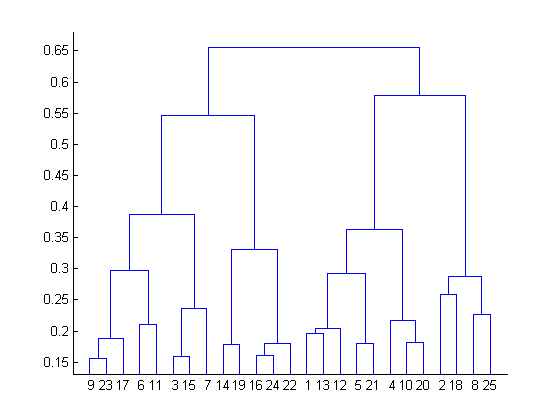{kind=link}
从底部开始,我们从25个数据点开始,每个数据点分配给不同的群集。然后合并两个最接近的群集,直到我们在顶部只有一个群集时结束。树状图中两个集合合并的高度表示数据空间中两个集合之间的距离。
通过观察树状图来描绘不同群体的群集是最好的办法。没有的再比这个更好的方法了,至少在群集问题上是没有了。树状图中的垂直线的水平线之间是不能相交的
在上面的例子中,最好的选择就是将集合分为4个,因为下面的树状图中的红色水平线标出了最大垂直距离AB。.
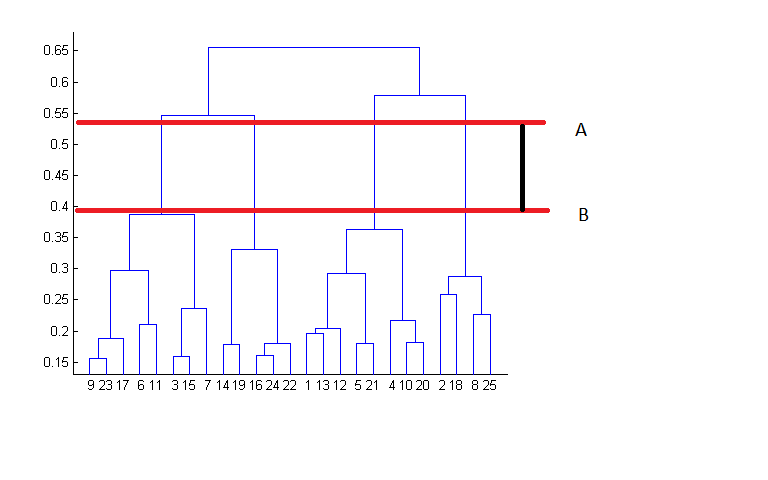{kind=link}
有关层次聚类应该了解的两件重要事情是:
- 该算法已经在上面使用自下而上的方法实现。也可以遵循自上而下的方法,从在同一个集群中分配的所有数据点开始,递归执行拆分,直到每个数据点分配一个单独的集群。
- 是否合并两个集群的决定是基于这些集群的紧密性。下面有多个度量标准来判断两个群集的接近程度:
- 欧几里得距离:|| ab || 2 =√(Σ(a i -b i))
- 平方欧几里得距离:|| ab || 2 2 =Σ((a i -b i)2)
- 曼哈顿距离:|| ab || 1 =Σ| a i -b i |
- 最大距离:|| ab || INFINITY = max i | a i -b i |
- Mahalanobis距离:√((ab)T S -1(-b)){其中,s:协方差矩阵}
6. K均值和分层聚类之间的差异
- 分层聚类不能很好地处理大数据,但K均值聚类可以。这是因为K均值的时间复杂度是线性的,即O(n),而层次聚类的时间复杂度是二次方的,即O(n 2)。
- 在K均值聚类中,由于我们从随机选择聚类开始,多次运行算法产生的结果可能会有所不同,虽然结果这些都可以在分层聚类中重现。
- 当集合的形状为超球形时(如2D中的圆圈,3D中的球体),K均值方法的断定结果比较好
- K均值聚类需要事先给定一个K 值。K值表示为你想要将数据分成的群集数量。但是,通过树状图的分层聚类法,我们可以在层次聚类中动态地找到集合的数量,以用来适合的任意数量的数据点
7.聚类的应用
聚类方法很轻量级。它的应用程序遍布各个领域。一些最流行的聚类应用领域是:
- 推荐引擎
- 市场细分
- 社交网络分析
- 搜索结果分组
- 医学影像
- 图像分割
- 异常检测
8.使用聚类改进监督学习算法
聚类是一种无监督的机器学习方法,但它可以用来提高监督机器学习算法的精确度。那哦我们可以通过将数据点聚类到相似的组中,并将这些聚类标签用作监督机器学习算法中的独立变量吗?让我们来看看吧。
我们使用R语言通过3000个观察数据和100个股票数据预测值来预测集群值是上升还是下降,以用来检查聚类对分类问题模型准确性的影响。该数据集包含从X1到X100的100个独立变量表示每一个股票的概况。每一个X变量应一个结果变量Y,它有两个结果:股票价格上涨表示位1和股票价格下降表示为-1。
数据集可以在这里找到:下载
我们首先尝试使用随机森林法而不使用聚类:
#loading requiredlibraries
library('randomForest')
library('Metrics')
#set random seed
set.seed(101)
#loading dataset
data<-read.csv("train.csv",stringsAsFactors=T)
#checkingdimensions of data
dim(data)
## [1] 3000 101
#specifying outcomevariable as factor
data$Y<-as.factor(data$Y)
#dividing thedataset into train and test
train<-data[1:2000,]
test<-data[2001:3000,]
#applyingrandomForest
model_rf<-randomForest(Y~.,data=train)
preds<-predict(object=model_rf,test[,-101])
table(preds)
## preds
## -1 1
## 453 547
#checking accuracy
auc(preds,test$Y)
## [1] 0.4522703
所以,我们得到的准确度是0.45。现在让我们使用k-means聚类,并重新使用随机森林法创建基于自变量值的五个聚类集合。
#combing test andtrain
all<-rbind(train,test)
#creating 5clusters using K- means clustering
Cluster <-kmeans(all[,-101], 5)
#adding clusters asindependent variable to the dataset.
all$cluster<-as.factor(Cluster$cluster)
#dividing thedataset into train and test
train<-all[1:2000,]
test<-all[2001:3000,]
#applyingrandomforest
model_rf<-randomForest(Y~.,data=train)
preds2<-predict(object=model_rf,test[,-101])
table(preds2)
## preds2
## -1 1
##548 452
auc(preds2,test$Y)
## [1] 0.5345908
在上面的例子中,尽管最终的准确性很差,但是聚类使我们的模型从0.45的精确度略微提高到0.53以上。
这表明聚类确实可以有助于监督机器学习任务。
结束笔记
在本文中,我们讨论了进行聚类分析的各种方法。它可以找到一种无监督学习领域的提升的方法。您还了解了如何使用聚类来提高监督式机器学习算法的准确性。
虽然聚类很容易实现,但您还需要注意一些重要的关键点,例如处理数据中的出现的异常值,并确保每个集合都有足够的数量的数据点。这篇文章详细讨论了聚类的各个方面。
你喜欢看这篇文章吗?请在下面的评论部分分享您的观点。