9.3 并发编程:多线程
9.3.1 线程基础知识
什么是线程?
CPU调度的最小单元,执行单位
什么多线程:
同一时刻开启多个线程并发(并行)的执行
线程vs进程
进程:主要任务是划分空间,加载资源,静态的
线程:执行代码,执行能力,动态的
线程是依赖于进程,一个进程可以包含多个线程,但是一定有一个主线程,线程才是CPU执行的最小单元.
开启多进程开销非常大,
开启线程开销非常小,
进程是线程的10-100倍
开启多进程的速度慢
开启多线程的速度快
进程之间数据不能直接共享,通过队列可以实现共享
同一个进程下的线程之间的数据可以共享
多线程的应用场景
并发:一个CPU来回切换(线程之间的切换),多进程并发,多线程并发
多进程并发:开启多个进程,每个进程里面的主线程执行任务
多线程并发:开启一个进程,此进程里面多个线程执行任务
什么时候用多进程,什么时候用多线程?
一个程序:三个不同任务(多线程)
以后工作中遇到并发:多线程居多.
9.3.2 开启线程的两种方式
from threading import Thread
def task():
print('开启线程')
if __name__ == '__main__':
t = Thread(target=task)
t.start()
print('主线程')
class MyThread(Thread):
def run(self):
print('开启线程')
if __name__ == '__main__':
t = MyThread()
t.start()
print('主线程')9.3.3 线程与进程之间的对比
- 速度的对比 -- 线程绝对要比进程快
from threading import Thread
from multiprocessing import Process
def task():
print('running')
if __name__ == '__main__':
t = Thread(target=task)
t.start()
print('主线程')
'''
打印结果:
running
主线程
'''
p = Process(target=task)
p.start()
print('主进程')
'''
打印结果:
主进程
running
'''
- 对比主/子pid -- 主线程和子线程pid相同
from threading import Thread
import os
def task():
print(f'子线程{os.getpid()}')
if __name__ == '__main__':
t = Thread(target=task)
t.start()
print(f'主线程{os.getpid()}')
# 打印结果
子线程 10532
主线程 10532- 线程之间共享数据
from threading import Thread
num = 1000
def task():
global num
num = 1
if __name__ == '__main__':
t = Thread(target=task)
t.start()
print(num) 打印结果: num = 19.3.4 线程的方法
from threading import Thread
import time
def task():
print('running')
if __name__ == '__main__':
t = Thread(target=task)
t.start()
# time.sleep(1)
print(t.is_alive()) # 判断子线程是否存活
t.setName('Agoni') # 设置线程名字
print(t.getName()) # 获取线程名字
print('主线程')
# threading模块方法
import threading
print(threading.current_thread()) # 获取线程对象
print(threading.current_thread().name) # 获取线程名字 MainThread
print(threading.active_count()) # 获取活跃的线程数量
print(threading.enumerate()) # 返回一个列表,放置所有的线程对象9.3.5 守护线程
第一种情况
from threading import Thread
import time
def task(name):
print(f'{name} is running')
time.sleep(1) #阻塞1秒,主线程就执行完了,作为守护线程,也要立刻结束,下面的代码不执行
print(f'{name} is over') # 没有执行
if __name__ == '__main__':
t = Thread(target=task,args=('Agoni',))
t.daemon = True
t.start()
print('主线程')
# 打印结果
Agoni is running
主线程第二种情况
from threading import Thread
import time
def foo(): # 守护线程
print(123)
time.sleep(1)
print("end123")
def bar(): # 子线程
print(456)
time.sleep(2)
print("end456")
if __name__ == '__main__':
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.daemon = True
t1.start()
t2.start() # 子线程,守护线程几乎同时进行
print("---main---")
# 打印结果
123
456
---main---
end123
end456思考:主线程已经打印结束,为什么守护线程继续执行?
守护线程:子线程守护主线程,主线程结束,子线程立刻结束.
主线程什么时候结束?
多线程是同一个空间,同一个进程,进程代表空间,资源,是静态的,主线程是进程空间存活在内存中的必要条件,守护线程必须要等主线程结束之后才结束,而主线程必须要等所有的非守护线程结束才能结束,所以守护进程必须等所有的非守护进程以及主线程结束之后才能结束.
守护线程与守护进程的区别


# 举例
from threading import Thread
import time
def foo():
print(123)
time.sleep(2)
print("end123")
def bar():
print(456)
time.sleep(1)
print("end456")
if __name__ == '__main__':
t1=Thread(target=foo)
t2=Thread(target=bar)
t1.daemon = True
t1.start()
t2.start()
print("---main---")
# 打印结果
123
456
---main---
end456
# 与上一个代码比较,守护线程阻塞时间比子线程阻塞时间长,在子现场曾执行完之后,主线程也结束,守护线程也结束.所以未打印 'end123'9.3.6 线程互斥锁
# 如果不加锁,让程序编程串行,要用join
from threading import Thread
import time
x = 100
def task():
global x
temp = x
time.sleep(1)
temp -= 1
x = temp
if __name__ == '__main__':
t_l = []
for i in range(100):
t = Thread(target=task)
t_l.append(t)
t.start()
for i in t_l:
i.join()
print(f'主线程{x}') 打印结果 x = 99
# 为什么得到的x结果为99?
# for循环速度很快,相当于100子线程同时拿到x=100,并赋值给temp,第一个子线程,继续执行代码,此时x=99,第二个线程拿到x=99,但是temp的值还是100,继续执行代码,再给x赋值99,接下来的子线程依次...from threading import Thread
from threading import Lock
x = 100
def task(lock):
lock.acquire()
global x # global x 在lock.acquire()前后结构都一样
temp = x
temp -= 1
x = temp
lock.release()
if __name__ == '__main__':
lock = Lock()
t_l = []
for i in range(100):
t = Thread(target=task,args=(lock,))
t_l.append(t)
t.start()
for i in t_l:
i.join() # 主线程在所有子线程结束后再执行
print(f'主线程{x}') 打印结果 x = 0
# 第一个线程拿到 x = 100 ,接下来的每个线程拿到的都是 x ,并不是x对应的值
# 第一个线程执行完毕后, x = 99
# 第二个进程进去: x = 98,后面依次...9.3.7 死锁和递归锁
什么是死锁现象?
多个线程(进程)竞争资源,如果开启的互斥锁过多,会遇到互相抢锁,等待的情况,程序会夯住.
形成死锁的原因:同时给一个线程(进程)连续加锁多次.
# 死锁现象
from threading import Thread
from threading import Lock
import time
lock_A = Lock()
lock_B = Lock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f'{self.name}拿到A锁')
lock_B.acquire()
print(f'{self.name}拿到B锁')
lock_B.release()
lock_A.release()
# 第一个子线程解A锁后,第二个子线程就会拿到A锁,同时第一个子线程会去f2拿B锁,这时候就会出现一个情况:第二个子线程等B锁,第一个子线程等A锁,程序就会夯住,这就是死锁现象
def f2(self):
lock_B.acquire()
print(f'{self.name}拿到B锁')
time.sleep(1)
lock_A.acquire()
print(f'{self.name}拿到A锁')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()
print('主线程')解决死锁的方法 -- 递归锁 Rlock
递归锁只能是一把锁,锁上有记录,只要acquire一次,锁上就计数1次,release一次计数就减1,只要递归锁计数不为0,其他线程或进程都不能引用此锁.
from threading import Thread
from threading import RLock
import time
lock_A = lock_B = RLock()
class MyThread(Thread):
def run(self):
self.f1()
self.f2()
def f1(self):
lock_A.acquire()
print(f'{self.name}拿到A锁')
lock_B.acquire()
print(f'{self.name}拿到B锁')
lock_B.release()
lock_A.release()
def f2(self):
lock_B.acquire()
print(f'{self.name}拿到B锁')
time.sleep(1)
lock_A.acquire()
print(f'{self.name}拿到A锁')
lock_A.release()
lock_B.release()
if __name__ == '__main__':
for i in range(3):
t = MyThread()
t.start()
print('主线程')9.3.8 信号量
Semaphore:信号量允许多个线程或者进程同时进入
from threading import Thread
from threading import current_thread
from threading import Semaphore
import time
import random
sm = Semaphore(4)
def go_public_wc():
sm.acquire()
print(f'{current_thread().name}正在使用WC')
time.sleep(random.randint(1,3))
sm.release()
if __name__ == '__main__':
for i in range(20):
t = Thread(target=go_public_wc)
t.start()9.3.9 GIL锁
GIL锁:全局解释器锁,是CPython特有的互斥锁,将并发变成串行,同一时刻只能有一个线程进入解释器中,使用共享资源,并且GIL锁是自动加锁和释放锁,目的是管理内部数据,牺牲效率,保证数据安全.
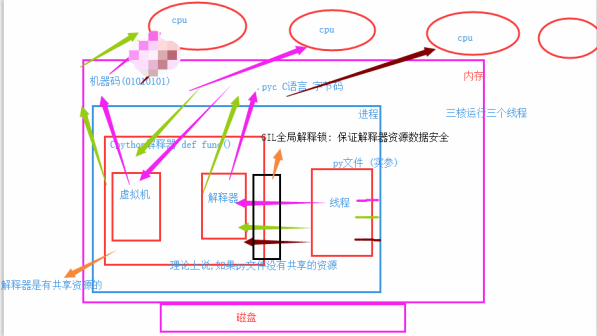
图解:同一个进程的三个线程,先拿到GIL的线程先进入解释器中.先交给CPU运行,如果当前线程遇到IO阻塞就会被挂起,GIL就会释放,然后下一个线程拿到GIL进入解释器.
设置全局解释锁:GIL
- 保证解释器里面的数据安全(当时开发Python语言时只有单核)
- 强行加锁:减轻开发的负担
加GIL全局解释锁带来的问题:
问题一:
- 单进程的多线程不能利用多核.诟病之一
- 多进程的多线程可以利用多核
问题二:
- 感觉上不能并发的执行问题??
讨论:单核处理IO阻塞的多线程,与多核处理IO阻塞的多线程效率差不多
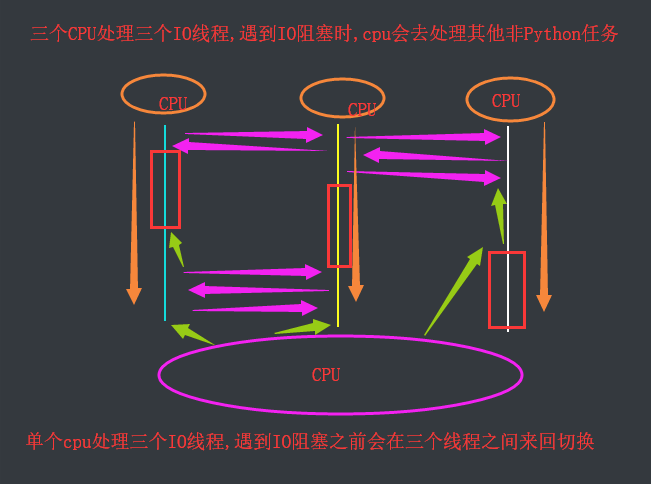
单核处理三个IO线程比多核处理三个IO线程的时间多在切换的时间(差不多)
分析:
四个任务需要处理,处理方式的方案选择:
方案一:开启四个进程
方案二:一个进程,开启四个线程
单核情况下,分析结果
如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜.
如果四个任务是IO密集型,方案一创建进程的开销大,且进程的切换速度远不如线程,方案二胜
多核情况下,分析结果
如果四个任务是计算密集型,多核意味着并行计算,在Python中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜
如果四个任务是IO密集型,再多的核也解决不了IO问题,方案二胜
在多核的前提下:
- 如果任务是IO密集型:多线程并发.
- 如果任务是计算密集型:多进程并发
9.3.10 验证CPython的并发效率
计算密集型: 开启四个进程,四个线程验证
from multiprocessing import Process
from threading import Thread
import time
def task1():
res = 1
for i in range(1,100000000):
res += i
def task2():
res = 1
for i in range(1,100000000):
res += i
def task3():
res = 1
for i in range(1,100000000):
res += i
def task4():
res = 1
for i in range(1,100000000):
res += i
if __name__ == '__main__':
# 四个进程,四个cpu并行效率
start_time = time.time()
p1 = Process(target=task1)
p2 = Process(target=task2)
p3 = Process(target=task3)
p4 = Process(target=task4)
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
print(f'主: {time.time() - start_time}') 10.75461721420288
# 一个进程,四个线程并发效率
start_time = time.time()
p1 = Thread(target=task1)
p2 = Thread(target=task2)
p3 = Thread(target=task3)
p4 = Thread(target=task4)
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
print(f'主: {time.time() - start_time}') 20.939976692199707IO密集型:通过大量的任务验证.
from multiprocessing import Process
from threading import Thread
import time
def task():
res = 1
time.sleep(1)
if __name__ == '__main__':
#开启200个进程(开销大,速度慢),执行IO任务,耗时 7.989548206329346
start_time = time.time()
l = []
for i in range(200):
p = Process(target=task)
l.append(p)
p.start()
for i in l:
i.join()
print(f'主: {time.time() - start_time}') 7.989548206329346
# 开启2000个线程(开销小,速度快),执行IO任务,耗时 1.023855209350586
start_time = time.time()
l = []
for i in range(200):
p = Thread(target=task)
l.append(p)
p.start()
for i in l:
i.join()
print(f'主: {time.time() - start_time}') 1.023855209350586
# 任务是IO密集型并且任务数量很大,用单进程下的多线程效率高9.3.11 GIL锁和互斥锁的关系
GIL锁.
- 自动上锁解锁
- 保护解释器的数据安全
文件中的互斥锁:
- 手动上锁解锁
- 保护的是文件数据的安全

from threading import Thread
from threading import Lock
import time
lock = Lock()
x = 100
def task():
global x
lock.acquire()
temp = x
time.sleep(1) # 如果此处没有睡1秒的阻塞,就是串行,有阻塞就是并发
temp -= 1
x = temp
lock.release()
if __name__ == '__main__':
t_l = []
for i in range(100):
t = Thread(target=task)
t_l.append(t)
t.start()
for i in t_l:
i.join()
# 线程全部是计算密集型:当程序执行,开启100个线程时,第一个线程先要拿到GIL锁,然后拿到lock锁,释放lock锁,最后释放GIL锁.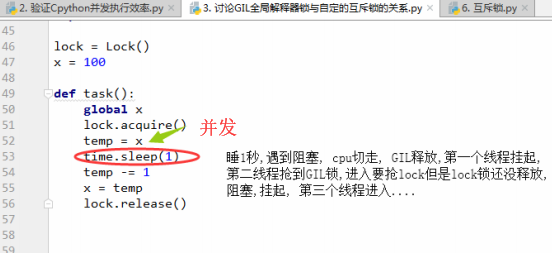
总结:自己加互斥锁,一定要加载处理共享数据的地方,加的范围不要扩大.
9.3.12 进程池与线程池
进程(线程)池:放置进程(线程)的一个容器
池化(Pool)优点:
- 先创建好一定数量的进程或线程,节省时间,提高效率
- 实现资源复用
线程池好,进程池好? 实际指 多线程,多进程的选择:IO密集型和计算密集型
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import ThreadPoolExecutor
import time
import os
import random
def task():
print(f'{os.getpid()}准备接客')
time.sleep(random.randint(1,3))
if __name__ == '__main__':
p = ProcessPoolExecutor(max_workers=5) # 进程池 max_workers 设置进程数量,默认CPU数量
p = ThreadPoolExecutor() # 线程池 默认CPU数量*5
for i in range(20):
p.submit(task) # 给线程池放任务,也可以传参完成一个简单的socket通信, 服务端必须与一个客户端交流完毕并且这个客户端断开连接之后,服务端才能接待下一个客户端.....不合理.
解决方案: 利用多线程
# 服务端
import socket
from threading import Thread
def conmmunication(conn):
while 1:
try:
from_client = conn.recv(1024) # 阻塞
print(f'客户端消息:{from_client.decode("utf-8")}')
to_client = input('>>>').strip()
conn.send(to_client.encode('utf-8'))
except Exception:
break
conn.close()
def customer_service():
server = socket.socket()
server.bind(('127.0.0.1', 8848))
server.listen(5)
while 1:
conn,addr = server.accept()
print(f'{addr}客户:')
p = Thread(target=conmmunication,args=(conn,))
p.start()
server.close()
if __name__ == '__main__':
customer_service()# 客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1',8848))
while 1:
to_server = input('>>>').strip()
client.send(to_server.encode('utf-8'))
from_server = client.recv(1024)
print(f'服务端消息:{from_server.decode("utf-8")}')
client.close()判断:
1.互斥锁的特点:限制被上锁的内容(代码或者其他资源)同一时刻只能被一个进程或线程使用. √
2.GIL锁是对解释器进程上的锁.√
3.GIL锁表示对CPython解释器同一时刻只能有一个进程使用它.×
4.GIL锁表示对CPython解释器同一时刻只能有一个线程使用它.√
5.GIL的存在导致多个Python进程不能同时执行.×
6.单核CPU上不能同时运行多个Python解释器进程.×
7.单核CPU上不能同时运行多个Python线程.×
8.多核CPU上不会出现Python线程数量多于CPU核心数.×
总结:
- GIL锁表示一个CPython解释器进程不论开启了多少个线程,它们不会被分配到不同的CPU上执行,必须串行执行在同一个解释器上.
- 在计算密集性程序中,使用多进程是可以提升效率的.(因为不同的进程可以运行在不同的核心上).此时使用多线程并不能提升效率.
- 在IO密集型的程序中,使用多线程是可以提升效率的.(因为IO密集型的程序往往存在等待时间,此时可以让CPU执行其他线程,进而提升效率).此时使用多进程并不能提升效率.
PS:
1.GIL只是针对解释器所上的互斥锁,即:有几个CPython解释器进程,就有几个GIL.
2.其他解释器可以运行一个进程,但是把其中的多个线程分派到多个核心上执行.
9.3.13 阻塞,非阻塞,同步,异步
程序运行中变现的状态:阻塞,运行,就绪
阻塞:程序遇到IO阻塞,会立刻停止(挂起),CPU马上切换,等到该程序的IO阻塞结束之后,再执行.
非阻塞:程序没有IO,或者遇到IO通过某种手段让CPU去执行其他的任务,尽可能的占用CPU
同步异步,站在发布任务的角度:
- 同步:任务发出去之后,要等待这个任务最终结束之后,给我一个返回值,再发布下个任务
- 异步:所有任务同时发出,就直接发布下一个任务,不需要立刻返回结果. ???
9.3.14 异步+回调机制
以爬虫举例:
浏览器做的事情很简单:浏览器封装头部,发送一个请求 --> www.taobao.com(IP地址)-->服务器获取到请求信息,分析正确 --> 返回一个文件 --> 浏览器将这个问件的代码渲染,就成了看到的页面
文件:
爬虫:利用request模块功能模拟浏览器封装头,给服务器发送一个请求,骗过服务器之后,服务器也给你返回一个文件,爬虫拿到文件,进行数据清洗(筛选),获取到你想要的信息.
爬虫分两步: 1. 爬取服务端的文件(IO阻塞) / 2. 拿到文件,进行数据分析(非IO,IO极少)
# 版本一
from concurrent.futures import ProcessPoolExecutor
import requests
import os
import time
import random
def get(url):
response = requests.get(url)
print(f'{os.getpid()}正在爬取{url}')
time.sleep(random.randint(1,3))
if response.status_code == 200:
return response.text
def parse(text):
'''对爬取回来的字符串的分析'''
print(f'{os.getpid()}分析结果:{len(text)}')
if __name__ == '__main__':
url_list = [
'http://www.taobao.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.baidu.com',
'https://www.cnblogs.com/jin-xin/articles/11232151.html',
'https://www.cnblogs.com/jin-xin/articles/10078845.html',
'http://www.sina.com.cn',
'https://www.sohu.com',
'https://www.youku.com',
]
pool = ProcessPoolExecutor(4)
obj_list = []
for url in url_list:
obj = pool.submit(get,url)
obj_list.append(obj)
pool.shutdown(wait=True)
for obj in obj_list:
parse(obj.result())
'''
串行
obj_list[0].result()
obj_list[1].result()
obj_list[2].result()
obj_list[3].result()
obj_list[4].result()
'''
# 问题出在哪里?
1. 分析结果的过程是串行,效率低.
2. 你将所有的结果全部都爬取成功之后,放在一个列表中,分析.# 版本二
# 异步处理: 获取结果的第二种方式: 完成一个任务返回一个结果,完成一个任务,返回一个结果 并发的返回.
from concurrent.futures import ProcessPoolExecutor
import requests
import os
import time
import random
def get(url):
response = requests.get(url)
print(f'{os.getpid()}正在爬取{url}')
time.sleep(random.randint(1,3))
if response.status_code == 200:
parse(response.text)
def parse(text):
'''对爬取回来的字符串的分析'''
print(f'{os.getpid()}分析结果:{len(text)}')
if __name__ == '__main__':
url_list = [
'http://www.taobao.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.baidu.com',
'https://www.cnblogs.com/jin-xin/articles/11232151.html',
'https://www.cnblogs.com/jin-xin/articles/10078845.html',
'http://www.sina.com.cn',
'https://www.sohu.com',
'https://www.youku.com',
]
pool = ProcessPoolExecutor(4)
for url in url_list:
obj = pool.submit(get,url)
pool.shutdown(wait=True)# 版本三: 版本二几乎完美,但是两个任务有耦合性. 再上一个基础上,对其进程解耦.
# 回调函数
import requests
from concurrent.futures import ProcessPoolExecutor
from multiprocessing import Process
import time
import random
import os
def get(url):
response = requests.get(url)
print(f'{os.getpid()} 正在爬取:{url}')
# time.sleep(random.randint(1,3))
if response.status_code == 200:
return response.text
def parse(obj):
'''
对爬取回来的字符串的分析
简单用len模拟一下.
:param text:
:return:
'''
time.sleep(1)
print(f'{os.getpid()} 分析结果:{len(obj.result())}')
if __name__ == '__main__':
url_list = [
'http://www.taobao.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.JD.com',
'http://www.baidu.com',
'https://www.cnblogs.com/jin-xin/articles/11232151.html',
'https://www.cnblogs.com/jin-xin/articles/10078845.html',
'http://www.sina.com.cn',
'https://www.sohu.com',
'https://www.youku.com',
]
start_time = time.time()
pool = ProcessPoolExecutor(4)
for url in url_list:
obj = pool.submit(get, url)
obj.add_done_callback(parse) # 增加一个回调函数
# 现在的进程完成的还是网络爬取的任务,拿到了返回值之后,结果丢给回调函数add_done_callback,
# 回调函数帮助你分析结果
# 进程继续完成下一个任务.
pool.shutdown(wait=True)
print(f'主: {time.time() - start_time}')回调函数是主进程帮助你实现的, 回调函数帮你进行分析任务. 明确了进程的任务:只有一个网络爬取.分析任务: 回调函数执行了.对函数之间解耦.
极值情况: 如果回调函数是IO任务,那么由于你的回调函数是主进程做的,所以有可能影响效率.
回调不是万能的,如果回调的任务是IO,那么异步 + 回调机制 不好.此时如果你要效率只能牺牲开销,再开一个线程进程池.
如果多个任务,多进程多线程处理的IO任务.
- 剩下的任务 非IO阻塞. 异步 + 回调机制
- 剩下的任务 IO << 多个任务的IO 异步 + 回调机制
- 剩下的任务 IO >= 多个任务的IO 第二种解决方式,或者两个进程线程池.
9.3.15 线程队列
- FIFO -- 先进先出
import queue
q = queue.Queue(3)
q.put(1)
q.put(2)
q.put(3)
print(q.get()) 1
print(q.get()) 2
print(q.get()) 3- LIFO -- 后进先出
import queue
q = queue.LifoQueue(3)
q.put(1)
q.put(2)
q.put(3)
print(q.get()) 3
print(q.get()) 2
print(q.get()) 1- 优先级队列 -- 需要元组的形式,(int,数据) int 代表优先级,数字越低,优先级越高.
import queue
q = queue.PriorityQueue(3)
q.put((5,'重要信息'))
q.put((10,'普通信息'))
q.put((0,'紧急信息'))
print(q.get()) # (0, '紧急信息')
print(q.get()) # (5, '重要信息')
print(q.get()) # (10, '普通信息')9.3.16 事件Event
import time
from threading import Thread
from threading import current_thread
from threading import Event
event = Event() # 默认是False
def task():
print(f'{current_thread().name} 检测服务器是否正常开启....')
time.sleep(3)
event.set() # 改成了True
def task1():
print(f'{current_thread().name} 正在尝试连接服务器')
event.wait() # 轮询检测event是否为True,当其为True,继续下一行代码. 阻塞.
# event.wait(1)
# 设置超时时间,如果1s中以内,event改成True,代码继续执行.
# 设置超时时间,如果超过1s中,event没做改变,代码继续执行.
print(f'{current_thread().name} 连接成功')
if __name__ == '__main__':
t1 = Thread(target=task1,)
t2 = Thread(target=task1,)
t3 = Thread(target=task1,)
t = Thread(target=task)
t.start()
t1.start()
t2.start()
t3.start()