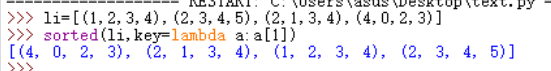一:常见的内置函数
1、查看内置函数 dir(__builtins__)

2、abs 绝对值
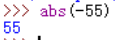
3、len 长度 输入一个
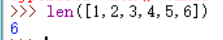
4、min 最小值 输入一个可迭代对象
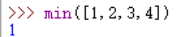
5、max 最大值 输入一个可迭代对象
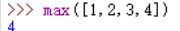
6、sorted 排序 按ASCLL码排序

7、reversed 反转

8、sum 求和
默认从0开始加和,可自定义从某个数字开始加。

9、bin 转化为2进制

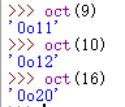
10、oct 转化为8进制
11、hex 转化为16进制

12、ord 转化为ASCLL码

13、chr 转化为字符

二、补充几个内置函数
1、enumerate() 返回一个枚举对象 传参时放一个可迭代参数,返回一个枚举对象,输入list(enumerate())
enumerate([1,2,3]) #返回一个枚举对象 输出结果:

list(enumerate([1,2,3])) 输出结果:

前面返回的是索引,后面返回的列表里的值
可以自定义初始索引

可以转化为字典

在输入集合的时候,就是按输入顺序来,伪索引

2、filter 过滤器
用来筛选,类似漏斗,传参时前面放入function or None ,后面放入可迭代对象,结果返回一个过滤对象,需要通过list dict 等转化为结果
filter(lambda x:x>1,[1,2,3]) #条件为x>1 ,筛选出x>1的对象 返回一个过滤对象 输出[2,3] filter(None,[1,2,3]) #筛选条件为空,筛选出所有对象 输出[1,2,3] 总结: 给定一个过滤的函数或None当参数,过滤对象是一个可迭代对象
3、map 全体加工
对于每个对象进行函数加工,返回一个map对象,前面放入一个function,后面放入一个可迭代对象*iterable(将可迭代对象解包)
map(lambda x:x+!,[1,2,3,4]) 输出:[2,3,4,5] map(lambda x:x>1,[1,2,3,4]) 输出:[False,True,True,True]
4、zip 匹配
将一个个可迭代对象一一配对,返回一个zip对象,可输入多个可迭代对象
zip([1,2,3],['a','b','c']) 输出:[(1,'a'),(2,'b'),(3,'c')] zip([1,2,3]) #也是一一配对,不过是假装你有对象 输出:[(1,),(2,),(3,)]
二、函数内变量的作用域
1、变量类型
全局变量:变量在函数外部定义,该变量的作用域是全局
局部变量:变量在函数内部定义,该变量的作用域是局部
x=1 #全局变量
def fun():
y=2 #局部变量
print(x,y)
2、global
试用情况:1、当在函数内部需要改变全局变量时,需要声明global
2、函数内的局部变量需要在函数外调用到时,需要声明global
x=1
def fun():
y=2
global x #需要修改时,将外面的x进入到里面来
global y #函数里面的y想要到外面去,需要声明自己是个全局变量
x+=1
print(x,y)
备注:需要调用y时,需要先调用fun()
3、nonlocal
声明局部变量,适用情况:当里层局部需要改变外层局部时,需要调用nonlocal函数
def fun1():
q=1
print('局部变量',q) 输出局部外层q
fun2():
w=33
nonlocal q #局部内层想要改变局部外层q,必须声明q
q+=1
print('局部里层',w)#输出局部里层w
print('局部里层',q) #输出的是改变了的q
fun2() #由于这是内嵌函数,需要执行的话必须调用
输出结果:局部变量 1
局部里层 33
局部里层 2
三、闭包(嵌套函数)
def fun1(a):
print(a)
def fun2(b):
print(a,b)
return fun2 #调用不执行
输入:fun1(1)
输出:1
函数体(。。。。)
以上就是闭包操作
输入:fun(1)(2)
输出:1
1 2
def fun1(a):
print(a)
def fun2():
print(a,11)
return fun2()
输入:fun1(1)
输出:1
1 11
四、回调函数
def fun1():
print('第一个函数')
def fun2(a):
a() #参数后面加了一个括号,把上一个函数体当成参数,在调用fun2是输入fun1,便是调用fun1函数
print('第二个函数')
输入:fun2(fun1)
输出:第一个函数
第二个函数
运行过程:先调用第一个函数,输出第一个函数的内容,然后在输出第二个函数
五、递归函数
核心:递归推导式,递归条件终止
例题:已知第一个人10岁,然后每个人一次比前面一个人大两岁,问第五个人的岁数
def age(n)
if n==1:
return 10 #放入初始年龄
else:
return age(n-1)+2 #第几个人一次比前面一个人大2,就是前一个人age(n-1),然后在继续调用函数,直至n等于1时,加上所有的年龄差,也就可以取出第n个人的年龄
输入:age(5)
输出:18
阶乘:
例如阶乘5,就是5*4*3*2*1,最后一个人必定是1
def jieCheng(a):
if a==1:
return 1
else:
return jieCheng(a-1)*a
输入:jieChen(5)
输出:120
六、作业
1、定义一个函数,输入一个序列(序列元素是同种类型),判断序列是顺序还是逆序,顺序输出UP,逆序输出DOWN,否则输出None
思路:先确定这个序列的顺序和逆序,然后用原序列跟顺序、继续比较即可
def panDuan(*arg):
arg=list(arg)
if arg==sorted(arg):
print('UP')
elif arg==sorted(arg,reverse=True):
print('DOWN')
else:
print('Done')
2、写一个函数,对列表li = [9,8,3,2,6,4,5,7,1],进行从小到大的排序。最后返回li
思路1:简单的调用sort函数即可
def paiXu(*arg):
arg=sorted(arg)
retrun arg
思路2:运用冒泡,每个索引跟其他所有相比较
def paiXu(*arg):
arg=list(arg)
for i in range(len(arg)):
for j in range(len(arg)):
if arg[i]<arg[j]:
arg[i],arg[j]=arg[j],arg[i]
print(arg)
return(arg)
3、li=[(1,2,3,4),(2,3,4,5),(2,1,3,4),(4,0,2,3)] 根据每个元组第二各元素来排序
sorted(li,key=lambda a:a[1])#自定义lambda函数,输入a输出a[1](就是每个元素内第二个索引值)
结果: