一、介绍
一个分布式协调服务框架;
一个精简的文件系统,每个节点大小最好不大于1MB;
众多hadoop组件依赖于此,比如hdfs,kafka,hbase,storm等;
旨在,分布式应用中,提供一个可靠的、可拓展的、分布式的、可配置的协调机制来管理整个集群的状态;
主要角色有:leader、follower、observer。
二、简单使用配置
安装很简单。一个tar包解压即可。
启动所需的配置文件为:zk安装目录/conf/zoo.cfg(需将安装包中原zoo_sample.cfg改名为zoo.cfg)
配置文件中,需指定dataDir,这个参数可以自定义,其意义为存放zk集群环境配置信息的。
clientport为客户端连接zk端口,默认为2181
此外,分布式集群zk,需增加配置,指定 集群中每一个节点的ip。
集群中每一个节点的ip。
因为我用的是3.4.7版本,集群中本机ip必须指定为0.0.0.0。
此外,还需要在指定的dataDir的数据目录下,创建一个myid文件,此中只需要写本zk的id。
我这里的集群是3台zk。每台配置基本都是如此,其他都是默认配置。
启动命令:./zkServer.sh start ----->>>观察zk状态:./zkServer.sh status可以观察当前zk服务状态,启动会显示zk的角色。
启动zk客户端可以进行一些简单对于zk的操作:./zkCli.sh
三、基本运行原理
1、zk结构

1)zk有一个根节点------>>>"/";
2)每个节点都叫znode节点;
3)每个znode都会有自己的子节点;
4)每个子节点的路径都是唯一的;
5)不可用zk节点存储海量数据,第一与其使用场景不符合,第二zk对节点的存储基于内存,容易撑爆内存,且多台zk存储的属于都一致;
6)zk持久化目录就在于传说中的,配置文件中指定的dataDir目录;
7)zk回为每一个操作,除读之外的,分配一个全局递增的事务id;
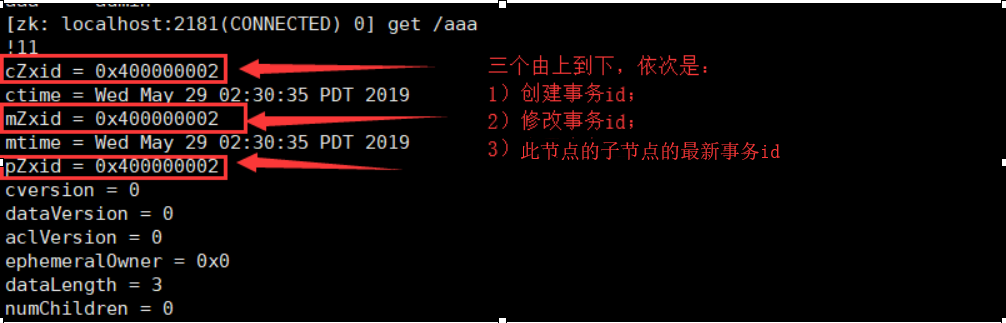
8)zk可以创建临时顺序节点,基于此,主节点服务器可以对应一个临时节点,备用服务器监控此临时节点,当主节点挂了时,此备用节点也会消失,从而备用节点可以顶上,从而zk可以管理集群中节点的服务状态。
2、zk选举
zk本身是支持HA的,在集群中会存在一个leader,其他都是follower,leader和follower之间会存在心跳访问,当leader挂了之后,zk集群接下一步的操作为重新选举新的leader;
1)如果并非leader挂了的情况,而是新启动zk集群,那么zk集群会先从本地指定的dataDir中恢复本节点数据,找到本方最大的事务id,即是最新的事务,此阶段为数据恢复阶段;
2)选举过程,集群中的每台zk都会向彼此提交选举协议,希望成为leader;
选举协议中包含本节点最新的事务id,自己在集群中的id,逻辑时钟值(确保是在同一轮选举中);
这时候zk节点会多出一个状态为looking状态;
3)PK原则,先比较事务id,谁的事务id最大谁是leader;
如果zxid比较不出,那就比选举id,此时需满足过半性原则,01、02、03为02,01、03、02为03,02、03,01为03,03、02、01为03
简单总结,进行id比较,从先向后启动顺序比较,谁满足了一半同意,谁就是leader。
zk的选举机制可以保证崩溃恢复,当leader挂了之后,如果集群数量满足过半性,那么就会从剩下的follower中选出薪的leader。
3、zk分布式一致性算法
先了解分布式一致性算法有哪些:
2PC算法-------->>>二阶段提交算法:
阶段一:leader向follower询问是否可以进行事务提交操作,follower进行预执行,如果都成功,先不提交,返回成功ack给leader;
阶段二:若所有follower都是成功ack,那么leader通知所有follower进行事务提交操作,事务完成;
若有follower有返回失败ack或者超时响应,leader通知所有follower进行回滚操作,follower给leader返回回滚ack。事务失败。
优点是简单,方便实现。
缺点是同步阻塞,leader在1阶段后一致在等待,造成时间浪费;
leader会存在单点问题,事务中leader挂了的话,那么整个事务将无法继续运行。
ZK使用的是改进后Paxos算法,也是改进后的二阶段提交算法:ZAB协议:
1)进行消息原子广播,保证数据一致性;
2)崩溃恢复,解决了2PC算法的单点问题。
简单说明ZAB协议:
1)zk通过原子(消息)广播的方式进行通信;
2)zk有一个单一的leader接收并处理所有client的事务请求,然后将数据状态的更新,通过广播的方式通知到所有的follower或者Observer中;
3)每一个事务请求都有一个全局唯一的id,此id为zxid,递增;
4)通过消息的广播的方式,每个follower接收到事务请求后,处理事务后,返回ack,只要follower收到半数以上的成功ack事务即成功。
但说到这里,并未解决leader的单点问题,并且只是半数ack即确认事务成功,虽然提高了效率,但是事务一致性可疑;
所以,zk更加详细的ZAB协议应该为:
1)leader将所有的事务分配一个递增的全局事务id;
2)leader在进行原子广播事务操作时,为每一个follower单独创建一个propersal(提案)队列,队列遵循fifo的策略,将事务操作放入,然后原子广播出去;
3)follower也有一个先入先出的事务队列,收到事务操作后,将事务操作写入事务日志中,然后反馈给leader,ack,leader收到半数以上的follower的ack后,会再次发出原子广播指挥所有的follower进行事务提交操作;
这个时候,假如有的follower没有返回ack,但是收到了commit指令,那么将直接执行完事务后提交事务;
如果这个follower挂掉了,那么当他重启时会进入数据恢复阶段,与follower进行数据一致性的同步,由这一点可见过半性原则的重要性;
当leader挂了之后,进入到崩溃恢复阶段;
1)整个zk集群假如仍有半数以上活着,先进行leader的选举操作;
2)如果所有的follower事务id都是一致的,从来没有接受过之前的事务操作,那么此事务就当没执行过,飘到外星宇宙去了(因为leader极端的在一瞬间进行原子广播时,失去了所有的follower);
3)那么根据zk的选举原则,新leader的事务id一定是最新的,对于刚才的事务,要不已经提交,要不未进行提交操作,对于未进行提交操作的,新的leader复制继续完成此事务,进行事务操作;
4)zk集群进入广播模式,新来的节点进行数据恢复。当原leader恢复了之后,会废掉自己的porpersal,从而成为follower。
参考:https://www.jianshu.com/p/400a44edee88