数据的描述性统计
一篇笔记,至少我还在努力
目录:
数据的集中趋势:
- 众数,中位数,平均数,分位数,极差
- 算术平均数,加权平均数,几何平均数
数据的离中趋势:
- 数值型数据:方差,标准差,极差,平均差
- 顺序数据:四分位差
- 分类数据:异众比率
相对离散程度:
- 离散系数
分布的形状:
- 偏态系数,峰态系数
描述性统计是借助图表或者总结性的数值来描述数据的统计手段
(所有代码基于python)
1.数据的集中趋势:
众数:一组数据中出现频次最多的值
1 mode(data)
中位数:将数据排序之后位于居中位置的数据
median(data)
平均数:所有的数据之和除以数据的个数
mean(data)
分位数:即分位点,是指将一个随机变量的概率分布范围分为几个等份的数值点,常用的有中位数(即二分位数)、四分位数、百分位数等
#将data按df1 和 df2 分组 pd grouped=data.groupby(['df1','df2']) #用quantile计算第40%的分位数 grouped['gmv'].quantile(0.4)
#numpy
s1 = array(data['df3'])
np.percentile(s1,0.4)极差:又称范围误差或全距(Range),以R表示,是用来表示统计资料中的变异量数(measures of variation),其最大值与最小值之间的差距,即最大值减最小值后所得之数据
ptp(data)
算术平均数:是一组数据的代数和除以数据的项数所得的平均数
几何平均数:是N个数据的连乘积的开N次方根,(x1*x2*x3*...*xn)^(1/n)。且一组数的几何平均数恒不大于算术平均数! (x1*x2*x3*...*xn)^(1/n)≤(x1+x2+x3+...+xn)/n
加权平均数:把原始数据按照合理的比例来计算(权是比例份额)
如:若 n个数中,x1出现f1次,x2出现f2次,…,xk出现fk次,那么(x1f1 + x2f2 + ... xkfk)/ (f1 + f2 + ... + fk) 叫做x1,x2,…,xk的加权平均数。f1,f2,…,fk是x1,x2,…,xk的权.
2.数据的离中趋势:
数值型数据:
方差:是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是各个数据分别与其平均数之差的平方的和的平均数。研究方差即偏离程度有着重要意义。
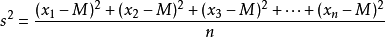 或
或 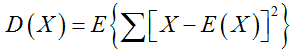
var(data)
标准差:总体各单位标准值与其平均数离差平方的算术平均数的平方根。方差与我们要处理的数据的量纲是不一致的,虽然能很好的描述数据与均值的偏离程度,但是处理结果是不符合我们的直观思维的。
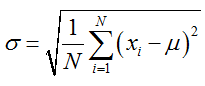
std(data)
平均差:是表示各个变量值之间差异程度的数值之一。指各个变量值同平均数的离差绝对值的算术平均数。
平均差异大,表明各标志值与算术平均数的差异程度越大,该算术平均数的代表性就越小;平均差越小,表明各标志值与算术平均数的差异程度越小,该算术平均数的代表性就越大。因离差和为零,离差的平均数不能将离差和除以离差的个数求得,而必须将离差取绝对数来消除正负号。平均差是反应各标志值与算术平均数之间的平均差异。
均方差:
均方误差是反映估计量与被估计量之间差异程度的一种度量,换句话说,参数估计值与参数真值之差的平方的期望值。MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度
协方差:
协方差用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。 如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
顺序数据:
四分位差:是上四分位数(Q3,即位于75%)与下四分位数(Q1,即位于25%)的差。
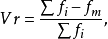 其中
其中
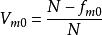 其中,
其中, ![]() 表示异众比率,
表示异众比率, ![]() 表示众数次数,N表示总体单位总数(即总体次数)
表示众数次数,N表示总体单位总数(即总体次数)
3、相对离散程度:
离散系数:又称变异系数。离散系数是测度数据离散程度的相对统计 量,主要是用于比较不同样本数据的离散程度。离散系数大,说明数据的离散程度也大;离散系数小,说明数据的离散程度也小。
离散系数是衡量资料中各观测值离散程度的一个统计量。当进行两个或多个资料离散程度的比较时,如果度量单位与平均数相同,可以直接利用标准差来比较。如果单位和(或)平均数不同时,比较其离散程度就不能采用标准差,而需采用标准差与平均数的比值(相对值)来比较。
![]() 表示总体离散系数和样本离散系数
表示总体离散系数和样本离散系数
在概率论和统计学中,离散系数(coefficient of variation),是概率分布离散程度的一个归一化量度,其定义为标准差 ![]() 与平均值
与平均值 ![]() 之比
之比
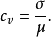 离散系数(coefficient of variation)只在平均值不为零时有定义,而且一般适用于平均值大于零的情况。变异系数也被称为标准离差率或单位风险。
离散系数(coefficient of variation)只在平均值不为零时有定义,而且一般适用于平均值大于零的情况。变异系数也被称为标准离差率或单位风险。
4、分布形状:
偏态系数:又称偏差系数,说明随机系列分配不对称程度的统计参数,用Cs表示。和Cv只能反映频率密度分配曲线的平均情况和离散程度,而不能反映其对称(即偏态)情况,所以必须再引入一个参数,即偏差系数Cso。偏态系数绝对值越大,偏斜越严重。
偏态系数以平均值与中位数之差对标准差之比率来衡量偏斜的程度,用SK表示偏斜系数:偏态系数小于0,因为平均数在众数之左,是一种左偏的分布,又称为负偏。偏态系数大于0,因为均值在众数之右,是一种右偏的分布,又称为正偏。
简单偏态系数: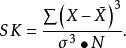
加权偏态系数: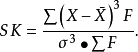
左右不对称即为偏态 。口诀一:看长尾在哪边就是往哪偏。口诀二:峰左移,右偏态;峰右移,左偏态
偏态系数绝对值值越大,偏斜程度越厉害。SK< 0 左偏SK> 0 右偏。SK以mean、mode之差与σ的比例来计算的,因此mean>mode,也就是右偏的时候,SK>0
峰态系数:
用来反映频数分布曲线顶端尖峭或扁平程度的指标。有时两组数据的算术平均数、标准差和偏态系数都相同,但他们分布曲线顶端的高耸程度却不同
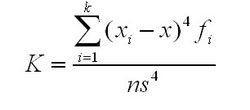 峰度系数可以为负数
峰度系数可以为负数
正态分布的峰度K=3,均匀分布的峰度K=1.8。kurtosis=K-3 称为超值峰度。kurtosis>0,尖峰态(leptokurtic),数据集比较分散,极端数值较多。kurtosis<0,低峰态(platykurtic),数据集比较集中,两侧的数据比较少
个人笔记。。。