Kafka介绍
官网:http://kafka.apache.org
Kafka是一款性能非常好的并且支持分布式的消息队列中间件。由于它的高吞吐特性,Kafka通常使用在大数据领域,如日志收集平台。其实Kafka是一个流处理平台,这个概念不太好理解,之所以叫做流,是因为它在工作中就像是一个可以支撑高吞吐量的管道,数据像水一样流进去,然后另外一端再去读取这些数据。我们就可以把Kafka看作是一种特殊的消息队列中间件。
kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。 kafka集群几乎不需要维护任何consumer和producer状态信息,这些信息有zookeeper保存;因此producer和consumer的客户端实现非常轻量级,它们可以随意离开,而不会对集群造成额外的影响。
Kafka与传统消息系统相比,有以下不同:
1)它被设计为一个分布式系统,易于向外扩展; 2)它同时为发布和订阅提供高吞吐量; 3)它支持多订阅者,当失败时能自动平衡消费者; 4)它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
1、Kafka中有几个关键角色和概念
1)Producer
消息生产者,是消息的产生源头,负责生成消息并发送给Kafka。
2)Consumer
消息消费者,是消息的使用方,负责消费Kafka服务器上的消息。
3)Topic
主题,由用户自定义,并配置在Kafka服务器,用于建立生产者和消费者之间的订阅关系,生产者将消息发送到指定的Topic,然后消费者再从该Topic下去取消息。
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
4)Partition
消息分区,一个Topic下面会有多个Partition,每个Partition都是一个有序队列,Partition中的每条消息都会被分配一个有序的id。
partitions的设计目的有多个.最根本原因是kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.
5)Broker
这个其实就是Kafka服务器了,无论是单台Kafka还是集群,被统一叫做Broker,有的资料上把它翻译为代理或经纪人。
6)Group
消费者分组,将同一类的消费者归类到一个组里。在Kafka中,多个消费者共同消费一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个组名。
kafka通过zookeeper管理集群配置,选举leader
2、kafka特点
1)Kafka:内存、磁盘、数据库、支持大量堆积
kafka的最小存储单元是分区,一个topic包含多个分区,kafka创建主题时,这些分区会被分配在多个服务器上,通常一个broker一台服务器。
分区首领会均匀地分布在不同的服务器上,分区副本也会均匀的分布在不同的服务器上,确保负载均衡和高可用性,当新的broker加入集群的时候,部分副本会被移动到新的broker上。
根据配置文件中的目录清单,kafka会把新的分区分配给目录清单里分区数最少的目录。
默认情况下,分区器使用轮询算法把消息均衡地分布在同一个主题的不同分区中,对于发送时指定了key的情况,会根据key的hashcode取模后的值存到对应的分区中。
a)一个broker通常就是一台服务器节点。对于同一个Topic的不同分区,Kafka会尽力将这些分区分布到不同的Broker服务器上,zookeeper保存了broker、主题和分区的元数据信息。分区首领会处理来自客户端的生产请求,kafka分区首领会被分配到不同的broker服务器上,让不同的broker服务器共同分担任务。
b)kafka的消费者组订阅同一个topic,会尽可能地使得每一个消费者分配到相同数量的分区,分摊负载。
Kafka工作流程
1)生产者定期向主题发送消息。
2)Kafka broker将所有消息存储在为该特定主题配置的分区中。它确保消息在分区之间平等共享。如果生产者发送两个消息,并且有两个分区,则Kafka将在第一个分区中存储一个消息,在第二个分区中存储第二个消息。
3)消费者订阅一个特定的主题。
4)一旦消费者订阅了一个主题,Kafka将向消费者提供该主题的当前偏移量,并将偏移量保存在ZooKeeper中。
5)消费者将定期请求Kafka新消息。
6)一旦Kafka收到来自生产者的消息,它会将这些消息转发给消费者。
7)消费者将收到消息并处理它。
8)一旦消息被处理,消费者将向Kafka broker发送确认。
9)一旦Kafka收到确认,它会将偏移量更改为新值,并在ZooKeeper中进行更新。由于ZooKeeper中保留了偏移量,因此即使在服务器出现故障时,消费者也可以正确读取下一条消息。
kafka集群部署:
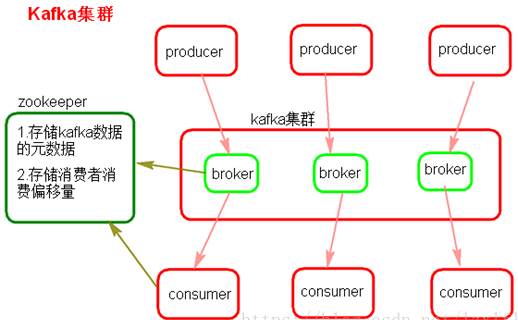
(1)Kafka架构是由producer(消息生产者)、consumer(消息消费者)、borker(kafka集群的server,负责处理消息读、写请求,存储消息,在kafka cluster这一层这里,其实里面是有很多个broker)、topic(消息队列/分类相当于队列,里面有生产者和消费者模型)、zookeeper(元数据信息存在zookeeper中,包括:存储消费偏移量,topic话题信息,partition信息) 这些部分组成。
(2)kafka里面的消息是有topic来组织的,简单的我们可以想象为一个队列,一个队列就是一个topic,然后它把每个topic又分为很多个partition,这个是为了做并行的,在每个partition内部消息强有序,相当于有序的队列,其中每个消息都有个序号offset,比如0到12,从前面读往后面写。一个partition对应一个broker,一个broker可以管多个partition,比如说,topic有6个partition,有两个broker,那每个broker就管3个partition。这个partition可以很简单想象为一个文件,当数据发过来的时候它就往这个partition上面append,追加就行,消息不经过内存缓冲,直接写入文件,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念。
(3)producer自己决定往哪个partition里面去写,这里有一些的策略,譬如如果hash,不用多个partition之间去join数据了。consumer自己维护消费到哪个offset,每个consumer都有对应的group,group内是queue消费模型(各个consumer消费不同的partition,因此一个消息在group内只消费一次),group间是publish-subscribe消费模型,各个group各自独立消费,互不影响,因此一个消息在被每个group消费一次。
kafka的集群安装配置:
1)kafka集群的安装配置依赖zookeeper,搭建kafka集群之前,需先部署好一个可用的zookeeper集群
2)需安装openjdk运行环境
3)同步kafka拷贝到所有集群主机
4)修改配置文件
5)每台服务器的broker.id都不能相同
6)zookeeper.connect集群地址,不用都列出,写一部分即可
部署环境:
操作系统 IP kafka版本
rhel6.5 192.168.1.234 2.1.1
rhel6.5 192.168.1.206 2.1.1
rhel6.5 192.168.1.45 2.1.1
1、创建用户,全部下载kafka
[root@kafka-0001]$useradd wushaoyu [root@kafka-0001]$su - wushaoyu [wushaoyu@kafka-0001]$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.1.1/kafka_2.11-2.1.1.tgz
2、创建消息目录,修改配置文件
[wushaoyu@kafka-0001 ~]$ cd kafka_2.11-2.1.1 [wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ mkdir logs [wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ cd config/ [wushaoyu@kafka-0001 config]$ cat server.properties |egrep -v "^$|^#" broker.id=1 #broker的全局唯一编号不能重复,建议与zookeeper的myid对应
listeners=PLAINTEXT://192.168.1.234:9092 #broker监听ip和端口
advertised.listeners=PLAINTEXT://192.168.1.234:9092
num.network.threads=3 #borker进行网络处理的线程数 num.io.threads=8 #borker进行I/O处理的线程数 socket.send.buffer.bytes=102400 #发送缓冲区大小,即发送消息先发送到缓冲区,当缓冲区满了在一起发出去 socket.receive.buffer.bytes=102400 #接收缓冲区大小,接收消息先放到接收缓冲区,当达到这个数量时同步到磁盘 socket.request.max.bytes=104857600 #向kafka套接字请求的最大字节数量,防止服务器outofmemory,大小最好不要超过java的堆栈大小 log.dirs=/home/wushaoyu/kafka_2.11-2.1.1/logs #消息存放目录,不是日志目录 num.partitions=1 #每个topic的默认分区数 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 #消息过期时间,默认为1周 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=192.168.1.234:2181,192.168.1.206:2181,192.168.1.45:2181 zookeeper.connection.timeout.ms=6000 group.initial.rebalance.delay.ms=0
3、启动kafka
[wushaoyu@kafka-0002 kafka_2.11-2.1.1]$ ./bin/kafka-server-start.sh ./config/server.properties OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c0000000, 1073741824, 0) failed; error='Cannot allocate memory' (errno=12) # # There is insufficient memory for the Java Runtime Environment to continue. # Native memory allocation (mmap) failed to map 1073741824 bytes for committing reserved memory. # An error report file with more information is saved as: # /home/wushaoyu/kafka_2.11-2.1.1/hs_err_pid23272.log
此处出现报错:无法分配足够的内存,因为部署环境为云主机,只有1G内存,所以可添加交换分区解决 查看内存大小 [wushaoyu@kafka-0002 kafka_2.11-2.1.1]$ free -m total used free shared buffers cached Mem: 995 920 75 0 80 641 -/+ buffers/cache: 198 797 Swap: 0 0 0 创建交换分区 [root@kafka-0001 ~]# dd if=/dev/zero of=/tmp/swap bs=1M count=8192 #创建文件,大小为8G 8192+0 records in 8192+0 records out 8589934592 bytes (8.6 GB) copied, 52.9978 s, 162 MB/s [root@kafka-0001 ~]# mkswap /tmp/swap #创建交换分区 mkswap: /tmp/swap: warning: don't erase bootbits sectors on whole disk. Use -f to force. Setting up swapspace version 1, size = 8388604 KiB no label, UUID=84ea82c7-35a3-46be-926a-73dfc7e18548 [root@kafka-0001 ~]# swapon /tmp/swap #启用交换分区 [root@kafka-0001 ~]# free -m total used free shared buffers cached Mem: 995 928 67 0 22 719 -/+ buffers/cache: 186 809 Swap: 8191 0 8191 再次启动 [wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ ./bin/kafka-server-start.sh ./config/server.properties & (默认在前台运行) 或[wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ ./bin/kafka-server-start.sh -daemon ./config/server.properties
Zookeeper+Kafka集群验证及消息发布
将server.1作为生成者,server.3作为消费者
#在server.1上执行
创建一个topic 一个分区,两个副本
[wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ ./bin/kafka-topics.sh --create --zookeeper 192.168.1.234:2181 --partitions 1 --replication-factor 2 --topic mymsg
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Created topic "mymsg".
模拟生产者,发布消息(消息发布者)
[wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ ./bin/kafka-console-producer.sh --broker-list 192.168.1.234:9092 --topic mymsg
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
>hello,world!
>nice to meet you.
>i love you
>
#在server.2上执行
模拟消费者,接收消息(消息接收者)
[wushaoyu@kafka-0002 kafka_2.11-2.1.1]$ ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.234:9092 --topic mymsg --from-beginning
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
hello,world!
nice to meet you.
i love you
#在 producer 里输入消息,consumer 中就会显示出同样的内容,表示消费成功
# --from-beginning表示从开始接收,否则只接收新产生的消息
至此,消息生产和消费没有问题,Kafka集群部署完成。
Kafka常用命令
1)查看topic
[wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ ./bin/kafka-topics.sh --list --zookeeper 192.168.1.234:2181 OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N __consumer_offsets mymsg
2)查看topic msmsg详情
[wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ ./bin/kafka-topics.sh --describe --zookeeper 192.168.1.234:2181 --topic mymsg OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N Topic:mymsg PartitionCount:1 ReplicationFactor:2 Configs: Topic: mymsg Partition: 0 Leader: 1 Replicas: 1,3 Isr: 1,3
3)删除topic
[wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ ./bin/kafka-topics.sh --delete --zookeeper 192.168.1.234:2181 --topic mymsg
4)生产者参数查看
[wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ ./bin/kafka-console-producer.sh
5)生成者参数查看
[wushaoyu@kafka-0001 kafka_2.11-2.1.1]$ ./bin/kafka-console-consumer.sh
kafka参考资料:
http://kafka.apache.org/21/documentation.html
https://www.jianshu.com/p/d3e963ff8b70
https://blog.51cto.com/littledevil/2134694?source=dra
https://www.cnblogs.com/saneri/p/8762168.html