文章目录
一、下载安装包及解压
- 解压文件
tar -zxvf kafka_2.11-1.0.0.tgz -C /export/servers/
- 删除之前的安装记录
cd /export/servers/
rm -rf /export/servers/kafka
rm -rf /export/logs/kafka/
rm -rf /export/data/kafka
- 重命名
mv kafka_2.11-1.0.0 kafka
二、修改配置文件
进入/export/servers/kafka/config
修改配置文件 vim server.properties

• Broker.id每个broker在集群中的唯一标识,正整数。当该服务器的ip地址发生变更,但broker.id未变,则不会影响consumers的消费情况

• listeners:kafka的监听地址与端口
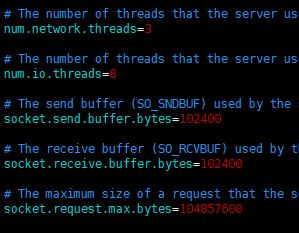
• num.network.threads:kafka用于处理网络请求的线程数
• num.io.threads:kafka用于处理磁盘io的线程数
• socket.send.buffer.bytes:发送数据的缓冲区
• socket.receive.buffer.bytes:接收数据的缓冲区
• socket.request.max.bytes:允许接收的最大数据包的大小(防止数据包过大导致OOM)
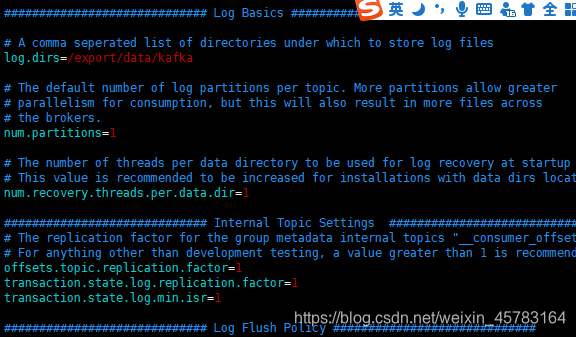

• log.dirs:kakfa用于保存数据的目录,所有的消息都会存储在该目录当中。可以通过逗号来指定多个路径,kafka会根据最少被使用的原则选择目录分配新的partition。需要说明的是,kafka在分配partition的时候选择的原则不是按照磁盘空间大小来定的,而是根据分配的partition的个数多少而定
• num.partitions:设置新创建的topic的默认分区数
• number.recovery.threads.per.data.dir:用于恢复每个数据目录时启动的线程数
• log.retention.hours:配置kafka中消息保存的时间,还支持log.retention.minutes和log.retention.ms。如果多个同时设置会选择时间最短的配置,默认为7天。
• log.retention.check.interval.ms:用于检测数据过期的周期
• log.segment.bytes:配置partition中每个segment数据文件的大小。默认为1GB。超出该大小后,会自动创建一个新的segment文件。
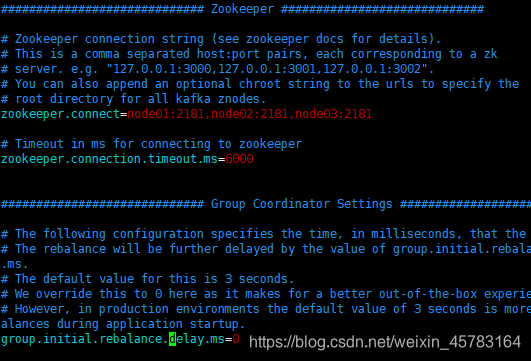
• zookeeper.connect:指定连接的zk的地址,zk中存储了broker的元数据信息。可以通过逗号来设置多个值。格式为:hostname:port/path。hostname为zk的主机名或ip,port为zk监听的端口。/path表示kafka的元数据存储到zk上的目录,如果不设置,默认为根目录
• zookeeper.connection.timeout:kafka连接zk的超时时间
• group.initial.rebalance.delay.ms:在实际环境当中,当将多个consumer加入到一个空的consumer group中时,每加入一个consumer就会触发一次对partition消费的重平衡,如果加入100个,就得重平衡100次,这个过程就会变得非常耗时。通过设置该参数,可以延迟重平衡的时间,比如有100个consumer会在10s内全部加入到一个consumer group中,就可以将该值设置为10s,10s之后,只需要做一次重平衡即可。默认为0则代表不开启该特性。
代码:
#broker.id 标识了kafka集群中一个唯一broker。
broker.id=0
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
#存放生产者生产的数据 数据一般以topic的方式存放
#创建一个数据存放目录 /export/data/kafka --- mkdir -p /export/data/kafka
log.dirs=/export/data/kafka
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zk的信息
zookeeper.connect=node01:2181,node02:2181,node03:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
三、把配置文件发给其他两个节点
- 把修改好的配置文件,分发到node02,node03上面
scp -r /export/servers/kafka/ node02:/export/servers/
scp -r /export/servers/kafka/ node03:/export/servers/
- 修改另外两台broker.id
a. 修改node02上的broker.id
vi /export/servers/kafka/config/server.properties
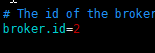
b. 修改node03上的broker.id
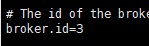
vi /export/servers/kafka/config/server.properties
四、验证环境(三台都执行)
- jdk环境

- zookeeper环境
1、解压完zookeeper
2、在/export/servers/zookeeper-3.4.5-cdh5.14.0目录下mkdir zkdatas 和 zklogs

3、/export/servers/zookeeper-3.4.5-cdh5.14.0/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg

4、生成myid
$ echo 1 > /export/service/zookeeper-3.4.5-cdh5.14.0/zkdatas/myid ##在第一台机器执行
$ echo 2 > /export/service/zookeeper-3.4.5-cdh5.14.0/zkdatas/myid ##在第二台机器执行
$ echo 3 > /export/service/zookeeper-3.4.5-cdh5.14.0/zkdatas/myid ##在第三台机器执行

五、启动命令
1,启动zookeeper
启动命令: sh bin/zkServer.sh start
停止命令: sh bin/zkServer.sh stop
查询状态: sh bin/zkServer.sh status
如果没有一键启动脚本,需要在每个节点上面启动
2,启动kafka前需要先启动动zookeeper
启动命令(后台启动):nohup bin/kafka-server-start.sh config/server.properties &
关闭命令 :bin/kafka-server-stop.sh
如果没有一键启动脚本,需要在每个几点上面进行启动
六、启动命令行之后
1、创建一个topic的命令
bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 1 --partitions 1 --topic test
2、创建一个生产者的命令
bin/kafka-console-producer.sh --broker-list kafka01:9092 --topic test
3、创建一个消费者的命令
bin/kafka-console-consumer.sh --zookeeper node01:2181 --from-beginning --topic test
4、删除一个topic
bin/kafka-topics.sh --delete --topic test --zookeeper node01:2181
命令解析:
–create: 指定创建topic动作
–topic:指定新建topic的名称
–zookeeper: 指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
–config:指定当前topic上有效的参数值
–partitions:指定当前创建的kafka分区数量,默认为1个–replication-factor:指定每个分区的复制因子个数,默认1个
5、查看topic的描述信息
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
命令解析:
–describe: 指定是展示详细信息命令
–zookeeper: 指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
–topic:指定需要展示数据的topic名称
六、测试
发送消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
>hello
>helloooooooo
//按`Ctrl+C`终止输入
消费消息
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
hello
helloooooooo
七、出现的问题:
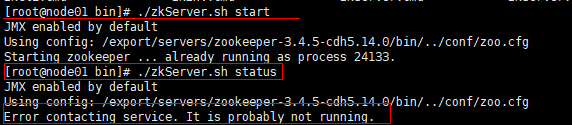
出错了 头疼,我真的弄了好久
报错:Error contacting service. It is probably not running.
这说明并没有启动成功
问题分析:
可以再bin目录下面的zookeeper.out来查看问题
1,打开zkServer.sh 找到status) STAT=echo stat | nc localhost ZOOCFG" | sed -e ‘s/.*=//’) 2> /dev/null| grep Mode
在nc与localhost之间加上 -q 1 (是数字1而不是字母l) 如果已存在则去掉
注:因为我用的zookeeper是3.4.5版本,所以在我的zkServer.sh脚本文件里根本没有这一行,所以没有生效
2,调用sh zkServer.sh status
遇到这个问题。百度,google了后发现有人是修改sh脚本里的一个nc的参数来解决,可在3.4.5的sh文件里并没有找到nc的调用。配置文档里指定的log目录没有创建导致出错,手动增加目录后重启,问题解决。
注:我想不是日志的问题所以这个方法根本就没有试
3,创建数据目录,也就是在你zoo.cfg配置文件里dataDir指定的那个目录下创建myid文件,并且指定id,改id为你zoo.cfg文件中server.1=localhost:2888:3888中的
1.只要在myid头部写入1即可. 注:在我第二次安装的时候,没有将myid文件创建在dataDir指定的那个目录下,也报了该错误。之后在dataDir指定的那个目录下创建myid文件就没有报错。
4 因为防火墙没有关闭。关闭防火墙:
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop #查看防火墙开机启动状态
chkconfig iptables --list #关闭防火墙开机启动
chkconfig iptables off
注意:我的确在开始时候没有关闭防火墙,但是当我关闭防火墙之后也没有解决问题。 5 没有建立主机和ip之间的映射关系。
建立主机和ip之间映射关系的命令为 vim /etc/hosts 在文件的末端加入各个主机和ip地址之间的映射关系就可以了。
注意:只有在建立了映射关系之后,才可以将在同一个网段下的机器利用主机名进行文件传递。问题解决!

