一,collections模块:
在python中原有的内置数据类型(dict、list、set、tuple等)的基础上,该模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.Counter(计数器):
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。
from collections import Counter
d = Counter('abcdeabcdabcaba') print(d) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
2.deque(双端队列): 为了高效实现插入和删除操作的双向列表,适合用于队列和栈
from collections import deque q = deque(['a', 'b', 'c']) q.append('x') q.appendleft('y') print(q) #deque(['y', 'a', 'b', 'c', 'x'])
3.defaultdict: 带有默认值的字典
from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] dict1 = defaultdict(list) for value in values: if value>66: dict1['k1'].append(value) else: dict1['k2'].append(value)
4.namedtuple(具名元组): 生成可以使用名字来访问元素内容的tuple
from collections import namedtuple Point = namedtuple('Point', ['x', 'y']) p = Point(1, 2) #Point(x=1,y= 2)
5.OrderedDict: 有序字典
d = dict([('a', 1), ('b', 2), ('c', 3)]) d # dict的Key是无序的 {'a': 1, 'c': 3, 'b': 2} #调用OrderedDict后 from collections import OrderedDict d2 = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) d2 # OrderedDict的Key是有序的 {'a': 1,'b': 2, 'c': 3}
二,时间模块
时间的三种格式:
1.time.time 时间戳。从1970年一直开始计算秒数
2.格式化的时间
time.strftime('%Y-%m-%d %H:%M:%S')
time.strftime('%Y-%m-%d %X')
格式符号有以下:

%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
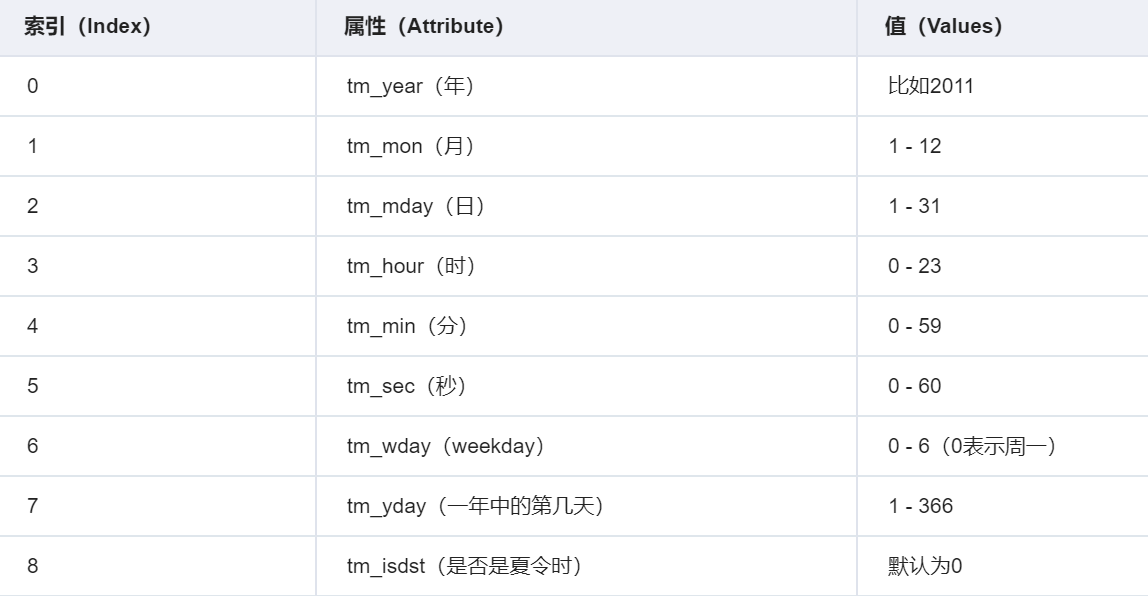
3.元组(struct_time) :struct_time元组共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
三,random模块
该模块的功能体现在随机取值的这种情况下用的较多。
import random #随机小数 random.random() # 大于0且小于1之间的小数 0.7664338663654585 random.uniform(1,3) #大于1小于3的小数 1.6270147180533838 #随机整数 random.randint(1,5) # 大于等于1且小于等于5之间的整数 random.randrange(1,10,2) # 大于等于1且小于10之间的奇数 #随机选择一个返回 random.choice([1,'23',[4,5]]) # #1或者23或者[4,5] #随机选择多个返回,返回的个数为函数的第二个参数 random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合 [[4, 5], '23'] #打乱列表顺序 item=[1,3,5,7,9] random.shuffle(item) # 打乱次序 print(item) #[5, 1, 3, 7, 9] random.shuffle(item) print(item) #[5, 9, 7, 1, 3]
练习题:随机生成大小写字母加数字任意位数的验证码
import random def code(n=5): res = ' ' for i in range(n): upper = chr(random.randint(65,90)) #取大写字母 lower = chr(random.randint(97,122)) #取小写字母 number = str(random.randint(0,9)) #取数字 res += random.choice([upper,lower,number]) return res
四,os 模块
os模块是与操作系统交互的一个接口
其用法有以下:
os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.system("bash command") 运行shell命令,直接显示 os.popen("bash command).read() 运行shell命令,获取执行结果 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.path os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小
stat 结构:
st_mode: inode 保护模式 st_ino: inode 节点号。 st_dev: inode 驻留的设备。 st_nlink: inode 的链接数。 st_uid: 所有者的用户ID。 st_gid: 所有者的组ID。 st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 st_atime: 上次访问的时间。 st_mtime: 最后一次修改的时间。 st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间。
五,sys模块
是与python解释器交互的一个接口。
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
六,序列化模块
序列化与反序列化:把python中的基本数据类型序列化为字符串类型,而这个字符串类型在其他语言中也能被反序列化成相对能识别的数据类型。
序列化的目的:
1.方便传递与传送
2.方便储存
3.使得程序更具有维护性
序列化又分两个模块:
1.json模块
loads 反序列化
dumps 序列化
import json dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = json.dumps(dic) #序列化:将一个字典转换成一个字符串 print(type(str_dic),str_dic) #<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"} #注意,json转换完的字符串类型的字典中的字符串是由""表示的 dic2 = json.loads(str_dic) #反序列化:将一个字符串格式的字典转换成一个字典 #注意,要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示 print(type(dic2),dic2) #<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}] str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型 print(type(str_dic),str_dic) #<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}] list_dic2 = json.loads(str_dic) print(type(list_dic2),list_dic2) #<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]
load 反序列化
dump 序列化import json f = open('json_file','w') dic = {'k1':'v1','k2':'v2','k3':'v3'} json.dump(dic,f) #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件 f.close() f = open('json_file') dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回 f.close() print(type(dic2),dic2) load和dump
2.pickle
用于python特有的类型 和 python的数据类型间进行转换
pickle模块也提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
import pickle dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = pickle.dumps(dic) print(str_dic) #一串二进制内容 dic2 = pickle.loads(str_dic) print(dic2) #字典 import time struct_time = time.localtime(1000000000) print(struct_time) f = open('pickle_file','wb') pickle.dump(struct_time,f) f.close() f = open('pickle_file','rb') struct_time2 = pickle.load(f) print(struct_time2.tm_year)