1.正则表达式
什么是正则?
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法.或者说正则就是用来描述一类事物的规则.
在python中我们运用正则就是用来筛选字符串中的特定的内容的
正则的应用场景
1.爬虫
2.数据分析
正则表达式的符号
(1)字符
| 元字符 | 匹配内容 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \s | 匹配任意空白符 |
| \d | 匹配数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \b | 匹配一个单词的结尾 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a|b | 匹配字符a或者字符b |
| () | 匹配括号内的表达式,也表示一个组 |
| [...] | 匹配字符组中的字符 |
| [^...] | 匹配除了字符组中字符的所有其他字符 |
注意:
^和$符号表示的是字符串的开头和结尾,当他们用在一起时会精准限制匹配的内容,他们中间写什么,匹配的字符串就是什么
abc|ab,这种abc或者ab的形式,长的一定要写在前面,不然短的会把长的全部取走
^符号的两种使用场景:
^写在外面,表示限制字符串的开头,后面跟什么,字符串的开头就必须是什么
^写在[^...]的格式,表示出了括号内^跟的字符,其他都要
分组:当多个正则符号需要重复多次时或者当做一个整体进行其他操作,可以以分组的形式
分组的语法就是()
(2)常用字符组形式
字符组:[字符组],括号里多个字符的形式
在同一个位置出现多个字符组成的字符组,正则表达式用[]表示
字符分为很多类,比如数字、字母、标点等等
| [0-9] | 表示0-9所有的数字 |
| [a-z] | 表示所有的小写字母 |
| [A-Z] | 表示所有的大写字母 |
| [0-9a-zA-Z] | 表示所有的数字和字母 |
(3)量词
| 量词 | 用法说明 |
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
量词必须跟在正则符号后面,并且只能限制紧挨他的那个正则符号
(4)转义符\
在正则表达式中,有很多有特殊意义的元字符,如\n和\s等,如果我们想输出正常的\n而不是换行符,我们就要使用转义符\,对\n的\进行转义,变成'\\'.
但是当我们需要输出\\n时,我们必须使用两个转义符\\\\n来转义,这样就显得很麻烦了,这时候我们就需要用到r这个转义符,只需输出r'\\n'就可以了
| 转义符 | 待转义字符 | 正则 |
| \ | \n | \\n |
| \\ | \\n | \\\\n |
| r | \\n | r'\\n' |
(5)贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
| <.*> | <script>...<script> | '<script>...<script>' | 默认为贪婪模式,会匹配尽可能多的字符 |
| <.*?> | <script>...<script> | '<script>','<script>' | 加上?后默认为非贪婪模式,会匹配尽可能少的字符 |
几个常用的非贪婪匹配
*?重复任意次,但尽可能少重复
+?重复1次或者更多次,但尽可能少重复
??重复0次或1次,但尽可能少重复
{n,m}?重复n到m次,但尽可能少重复
{n,}?重复n次以上,但尽可能少重复
.*?的用法
.是任意字符
*是取0到无限大
?是非贪婪模式
两个组合在一起就是尽量少的取任意字符,一般不会单独写
一般都是.*?x,在x之前取任意长度的字符,直到x出现
2.re模块
re模块和正则表达式之间的关系
正则表达式不是python独有的,它是一门独立的技术,所有的编程语言都可以使用正则,但是如果想在python中使用,必须依赖于re模块
re模块下的常用方法
import re res = re.findall('z','sxc zzj zzp') # 返回所有满足条件的结果,放在列表里 print(res) # 返回的结果是['z', 'z', 'z', 'z'] res1 = re.search('z','sxc zzj zzp') # 查找模式,只需要找到第一个就返回 print(res1) # 返回匹配信息的对象 print(res1.group()) # 调用group()可以查看返回值,结果 z res2 = re.search('a','sxc zzj zzp') print(res2) # 当查找一个不存在的字符会返回None res3 = re.match('s','sxc zzj zzp') # 和search一样,但是在开始处匹配 print(res3.group()) # 返回结果 s res4 = re.split('[23]','2a1b2c3d4') # 先按'2'切得到一串字符,再按3切得到最终返回结果 print(res4) # 返回结果['', 'a1b', 'c', 'd4'] res5 = re.sub('\d','haha','1-2-3-4-5-') # 将字符串的数字全部换成haha print(res5) # 返回结果haha-haha-haha-haha-haha- res6 = re.sub('\d','haha','1-2-3-4-5-',3) # 可以加数字,指定替换几个字符 print(res6) # 返回结果haha-haha-haha-4-5- res7 = re.subn('\d','zz','1-2-3-4-5',3) # 替换的结果和替换的次数以元组的形式返回 print(res7) # 返回结果('zz-zz-zz-4-5', 3) obj = re.compile('\d{5}') # 将正则表达式编译成一个正则表达式对象,规则要匹配3个数字 res8 = obj.search('s123456xc') #正则表达式对象调用search,参数为待匹配的字符串 print(res8.group()) # 返回结果12345 res9 = re.finditer('\d','1s2s5f6t') # finditer返回一个存放匹配结果的迭代器 print(res9) # 生成一个迭代器 print(next(res9).group()) # 调用取值,返回1 print(next(res9).group()) # 调用取值,返回2 print(next(res9).group()) # 调用取值,返回5 print(next(res9).group()) # 调用取值,返回6 print(next(res9).group()) # 调用取值,超过范围报错StopIteration
findall的优先级查询
import re res = re.findall('www.(baidu|oldboy).com','www.oldboy.com')# 需要返回的是www.oldboy.com print(res) # 返回的结果是oldboy,这是因为findall会优先返回组里的内容 res1 = re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')# 需要返回的是www.oldboy.com print(res1) # 使用?:取消其优先级权限,返回的结果是www.oldboy.com
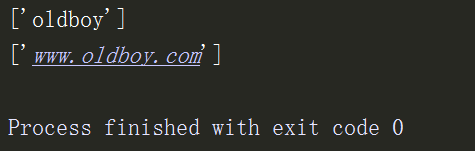
spilt的优先级查询
import re res = re.split('\d','sxc1zzj2zzp3') # 优先按照数字来切 print(res) # 结果:['sxc', 'zzj', 'zzp', ''] res1 = re.split('(\d)','sxc1zzj2zzp3') # 加了括号会保存数字 print(res1) # 结果['sxc', '1', 'zzj', '2', 'zzp', '3', '']

在匹配部分加()结果是完全不同的,没有()的没有保留匹配的项,保留()的保留了匹配的项,这在某些需要保留匹配的项是非常重要的