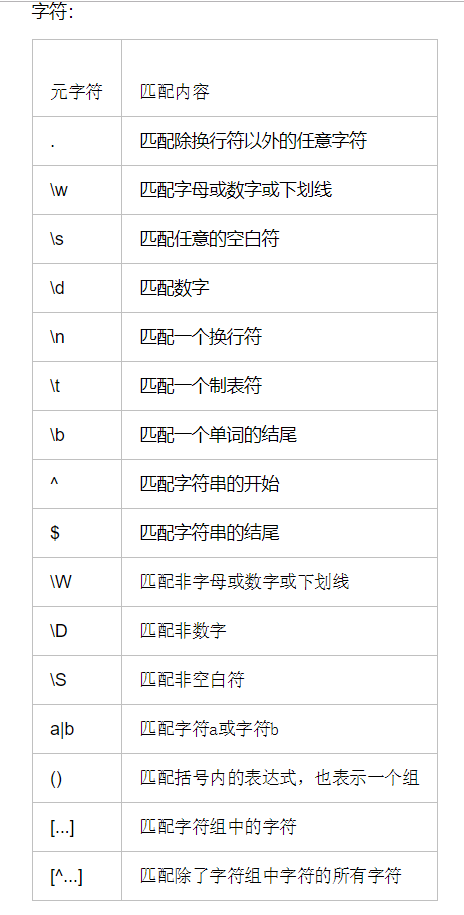
一.正则
1.字符组
[a-zA-Z0-9]字符组中的 [^a] 除了字符组的
2.
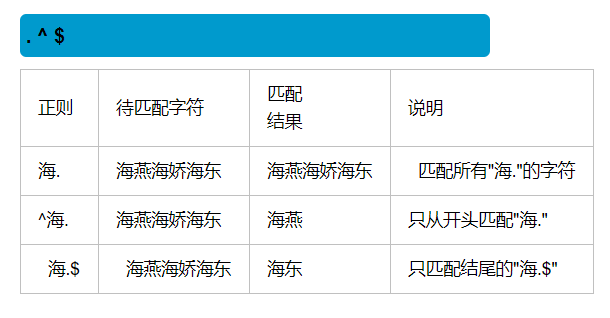
3.
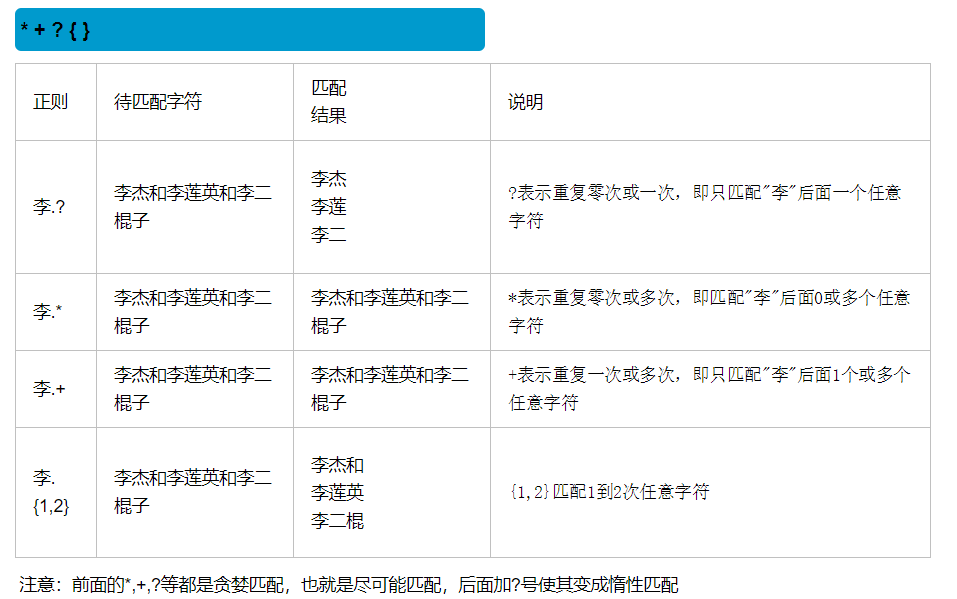
4.
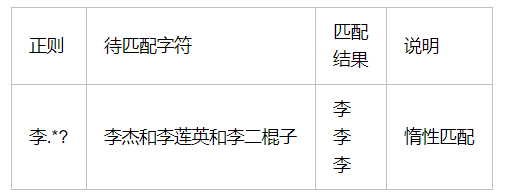


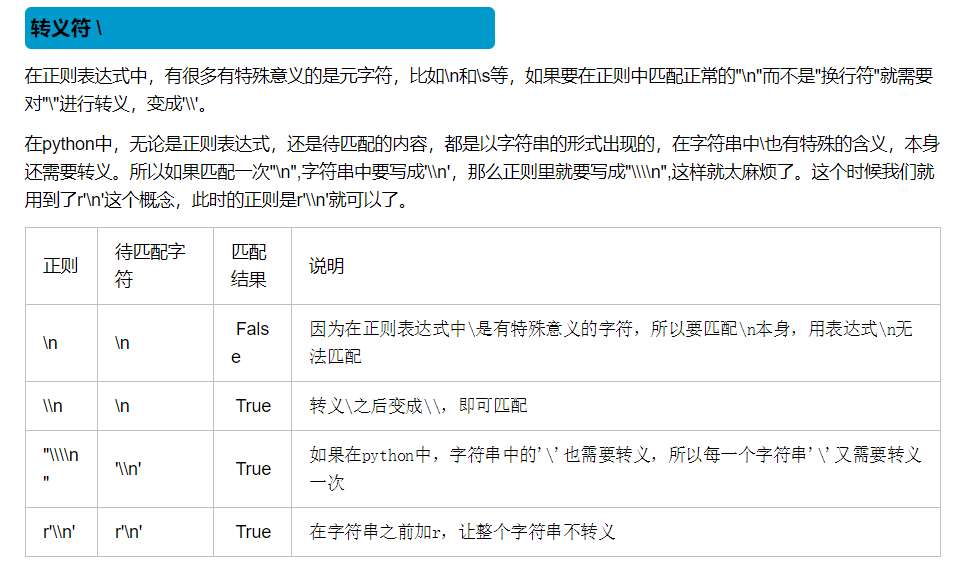
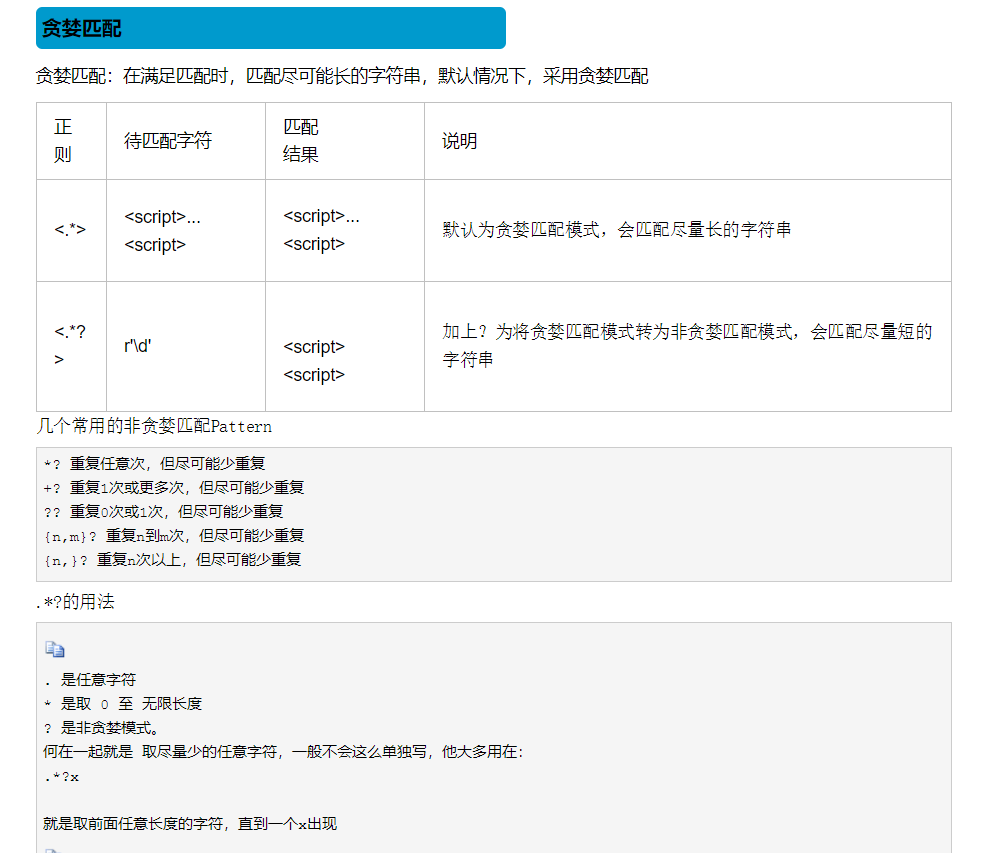
二.re模块
re.S 设置 .的换行 obj=re
1.ret=re.search(正则,content) 找到一个结果就返回
拿到结果 需要.group ret.group()
2.ret=re.match(正则,content) 从头匹配. 如果匹配到了。 就返回
也需要 ret.group()
3.ret=re.findall(正则,content) 匹配到的结果全部放入列表中 ,下级元素以元组存放


import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com']
4.ret=re.finditer(正则,content) 得到一个迭代器,循环迭代器时,取值时,也要 用group
for el in ret:
el.group()
5.re.split(正则,字符串) 用正则中的每个元素分别进行切割
ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : ['eva', 'egon', 'yuan'] ret=re.split("(\d+)","eva3egon4yuan") print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan'] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
6.re.sub(正则,new,字符串) 替换 用新的 替换符合正则的元素
7.re.subn(正则,new,字符串) 替换 用新的 替换符合正则的元素替换。 返回的结果带有次数
8. obj=re.compile(正则) 预加载 正则 lst=obj.findall(content)
obj=re.compile(r"start.*?(?P<自定义名字>.*j)end",re.S)
import re res = re.search("e", "alex and exp") # 搜索. 搜到结果就返回 print(res.group()) res = re.match("\w+", "alex is not a good man") # 从头匹配. 如果匹配到了。 就返回 print(res.group()) lst = re.findall("\w+", "alex and exo") print(lst) it = re.finditer("\w+", "mai le fo leng") for el in it: print(el.group()) # # 这个分组是优先级 lst = re.findall(r"www\.(baidu|oldboy)\.com", "www.oldboy.com") print(lst) # (?: ) 去掉优先级 lst = re.findall(r"www\.(?:baidu|oldboy)\.com", "www.oldboy.com") print(lst) # 加了括号。 split会保留你切的刀 lst = re.split("([ab])", "alex is not a sb, no he is a big sb") # 根据正则表达式进行切割 print(lst) # # # 替换 res = re.sub(r"\d+", "_sb_", "alex333wusir666taibai789ritian020feng") print(res) # # # 替换。 返回的结果带有次数 res = re.subn(r"\d+", "_sb_", "alex333wusir666taibai789ritian020feng") print(res) a = eval("1+3+5+6") print(a) code = "for i in range(10):print(i)" c = compile(code, "", "exec") # 编译代码 exec(c) obj = re.compile(r"alex(?P<name>\d+)and") # 把正则表达式预加载 res = obj.search("alex250andwusir38ritian2") print(res.group()) print(res.group("name"))
import re from urllib.request import urlopen #正则 obj=re.compile(r'<div class="item">.*? <a href=(?P<URL>.*?)">.*?<span class="title">(?P<name>.*?)</span>' r'.*?<span class="rating_num" property="v:average">(?P<fen>.*?)</span>.*?<span>(?P<pingjia>.*?)人评价</span>',re.S) #获取网页内容函数 def get_content(url): content=urlopen(url).read().decode("utf-8") return content #获取网页所要内容转化成字典的函数 def parse(content): g=obj.finditer(content) for el in g: yield { '电影名':el.group("name"), 'url':el.group("URL"), '评分':el.group('fen'), '评价人数':el.group("pingjia") } #分页爬取 for i in range(10): url="https://movie.douban.com/top250?start=%s&filter="%i*25 #每页的url 每页共25部电影 g=parse(get_content(url)) f=open("dian.txt","a",encoding="utf-8") for el in g: f.write(str(el)+"\n") # print(el) f.close()
import re from urllib.request import urlopen import json url="https://www.dytt8.net/" content=urlopen(url).read().decode("gbk") obj=re.compile(r"最新电影下载</a>]<a href='(?P<URL>.*?)'>.*?《(?P<name>.*?)》",re.S) obj2=re.compile(r'<!--Content Start--><span style="FONT-SIZE: 12px"><td>.*?' r'【下载地址】</font></font></strong> <br /><br /><br /><a href=".*?(?P<xiazai>.*?)"><strong>',re.S) lst=obj.findall(content) f=open("movie",'w',encoding="utf-8") for el in lst: try: dic= {"name":el[1],"URL":"https://www.dytt8.net"+el[0]} url2=dic["URL"] content2=urlopen(url2).read().decode("gbk") dz=obj2.search(content2).group("xiazai") dic2={"name":dic["name"],"地址":dz} s=json.dumps(dic2,ensure_ascii=False) f.write(s+"\n") print(dic) except Exception as e: continue f.close()