ELK环境搭建与测试
一、本文所需软件版本:
添加yum数据源查看我另外一篇博客:yum源安装
(1)两台服务器
(2)CentOS6.5
(3)Filebeat5.6
(4)Redis4.0.9
(5)Logstash5.6.8
(6)elasticsearch5.6.8
(7)Kibana5.6.8 (windows系统下启动)
(8)grafana6.2.5(windows系统下启动)
设计流程图:

注意⚠️:所有的版本一定要保持一致,高版本跟低版本之间会出现兼容性问题,比如我遇到的是elasticsearch7部署在服务器上,可以运行,但是在Kibana上显示时会要求密钥信息。
二、原理以及配置:
(1) Filebeat
工作原理:
1)filebeat用于本地日志数据采集,由于只申请到两台服务器,所以只用一台启动filebeat。
2)每个filebeat主要由两个部分组成,prospector和harvester,通过这两个部分来实现指定文件的查找与输出。
3)当启动filebeat后,prospector会查找配置的本地文件,对于查找到的文件,prospector会启动harvester,harvester会打开这个日志文件,并发送到libbeat,然后通过libbeat聚合数据后发送到redis数据库(本文output是redis)
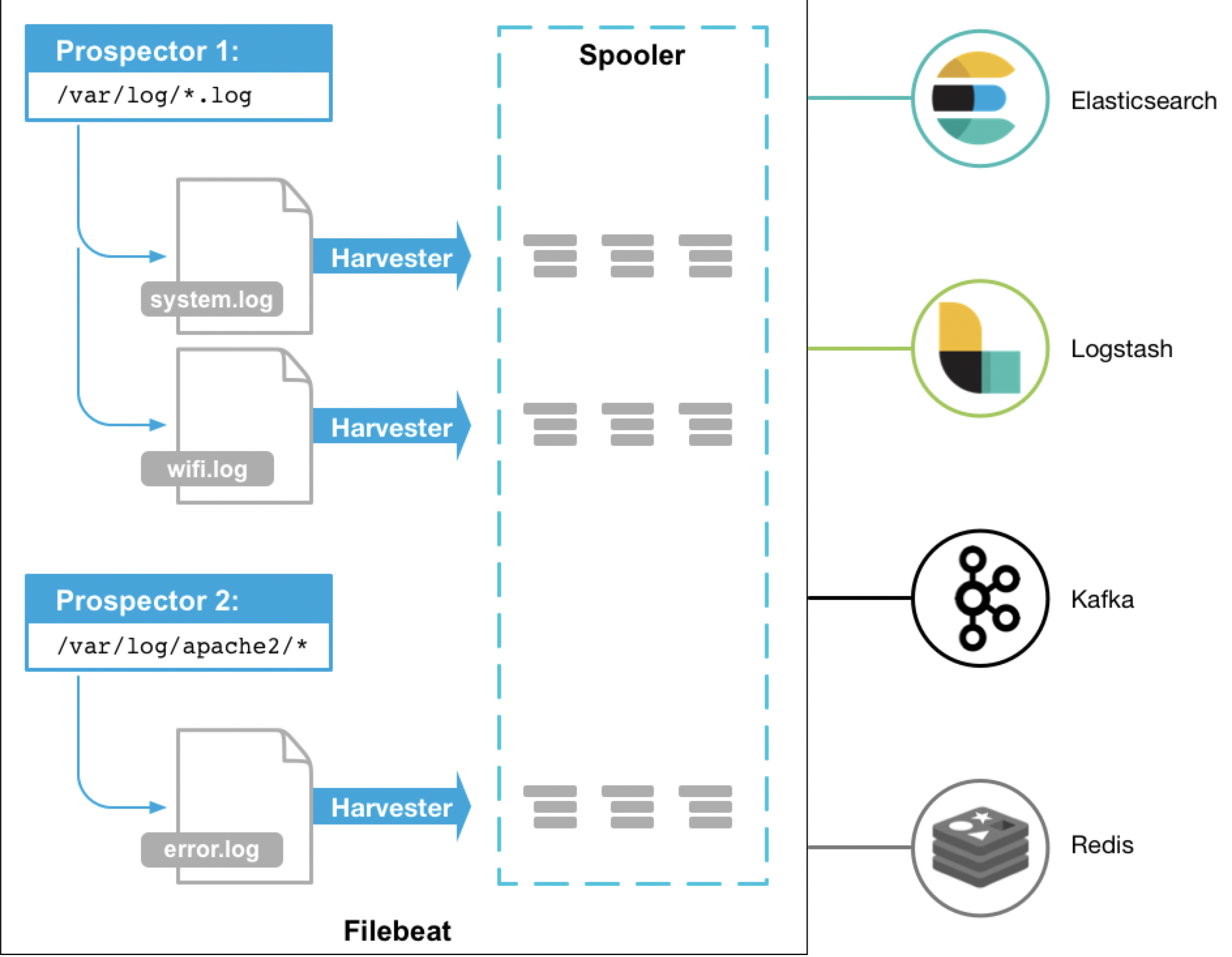
-图片来自网络-
4)如果在log文件中持续输入数据,那么harvester只会读取没有读过的数据,因为每次读完会在注册表中添加偏移量信息,这样每次读的时候就能知道跑,数据已读到哪个位置了。
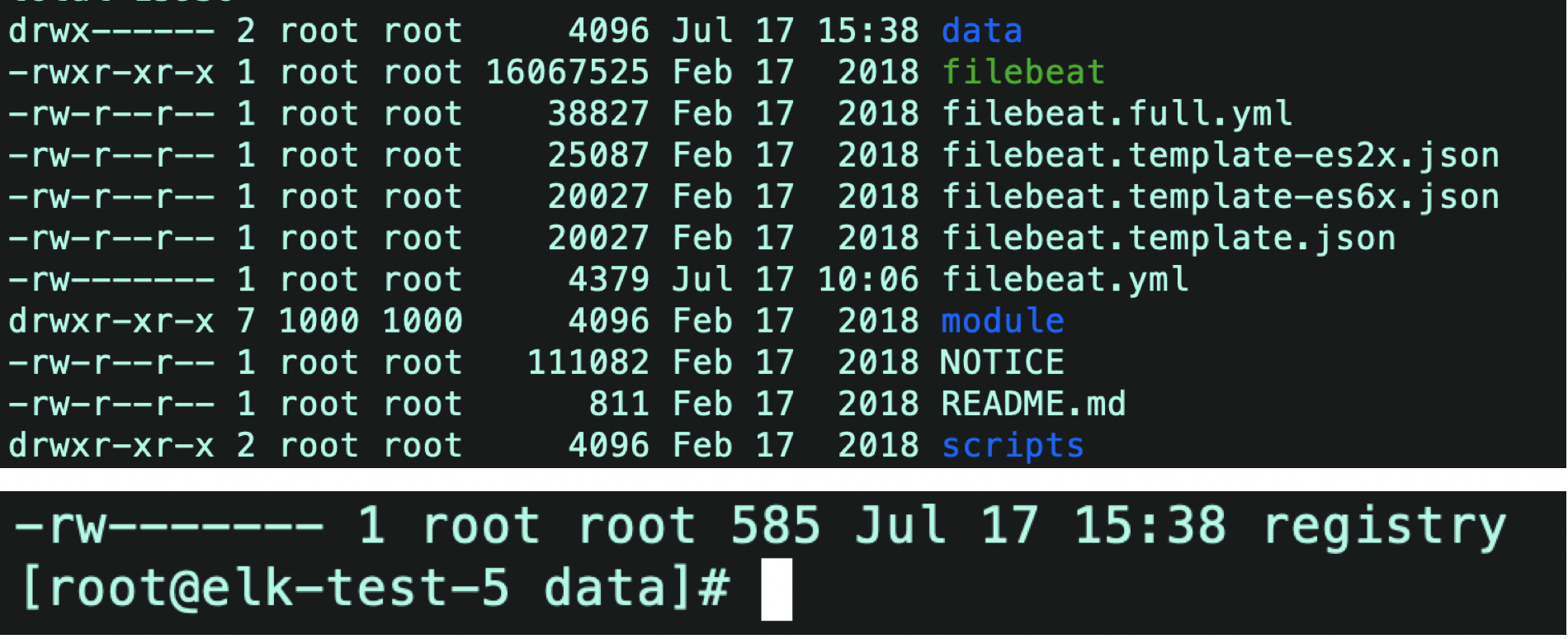

data下面有一个registry,里面存放的已读数据的信息
参考文档:filebeat原理
配置:
1)
修改filebeat.yml中的input和output配置,input为本地日志文件的地址,output为redis的地址。
2)

input地址:/opt/logs
3)
redis output需要自己手动添加
hosts:ip为第二台服务器的ip地址,端口6379为redis的端口
key:由于redis是(k,v)格式,所以这边规定一下key,与后面配置的logstash中配置的key要一致。
(2)Redis
工作原理:(K,V)类型基于内存的数据库,处理数据量大,IO大的情况,支持每秒十几万的读写,有效的解决了数据库不能快速IO的问题。而且支持持久化到硬盘。
配置:
参考文档:Redis配置
除了以上博客中的内容,修改以下配置:
修改redis.conf
目的:redis监听所有的连接,redis其实只要监听来自filebeat服务器的数据即可,所以也可以改成filebeat服务器的ip地址
(3)logstash
工作原理:实时数据采集引擎,
处理流程:input(redis)—— Filter —— Output(elasticsearch)
Input:从数据源获取数据
Filter:处理数据,如格式转换
Output:数据输出到相应插件,如elasticsearch
在对logstash进行调优的时候主要是pipeline的线程数,由于没有接触调优,暂时挂一张图。
配置:
1)在安装目录的bin目录下添加一个新的文件,名字任意,我的叫redis.log,因为数据来自于redis
在里面添加
input {
redis {
host => "127.0.0.1"
port => "6379"
data_type => "list"
db => 2
batch_count => 1
#type => "log"
key => "nginx-log"
}
}
filter {
grok {
match => { "message" => "%{IPORHOST:remote_addr} - - [%{HTTPDATE:time_local}] "%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{INT:status} %{INT:body_bytes_sent} %{QS:http_referer} %{QS:http_user_agent}"
}
}
}
output {
elasticsearch {
hosts => "127.0.0.1:9200"
index => "nginx-log"
}
}
Input:表示数据输入来源的信息,127.0.0.1是因为在同一个服务器中,key与filebeat中的key保持一致
filter:处理数据,转换格式
Output:表示数据输出的信息,index是之后在Kibana中需要用到的索引名,从logstash过去的数据索引名为nginx-log
遇到的问题:Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the "path.data" setting.
原因:之前运行的instance有缓冲,保存在path.data里面有.lock文件,删除掉就可以。
解决方法:data目录下通过ls -alh找到.lock文件并删除

(4)elasticsearch
工作原理:看我的另外一篇博客elastisearch分布式原理
配置:
这是出于系统安全考虑设置的条件。由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考虑,建议创建一个单独的用户用来运行ElasticSearch。
1)修改elasticsearch.yml文件
添加数据地址、日志地址,去掉注释,这两个地址需要自己新建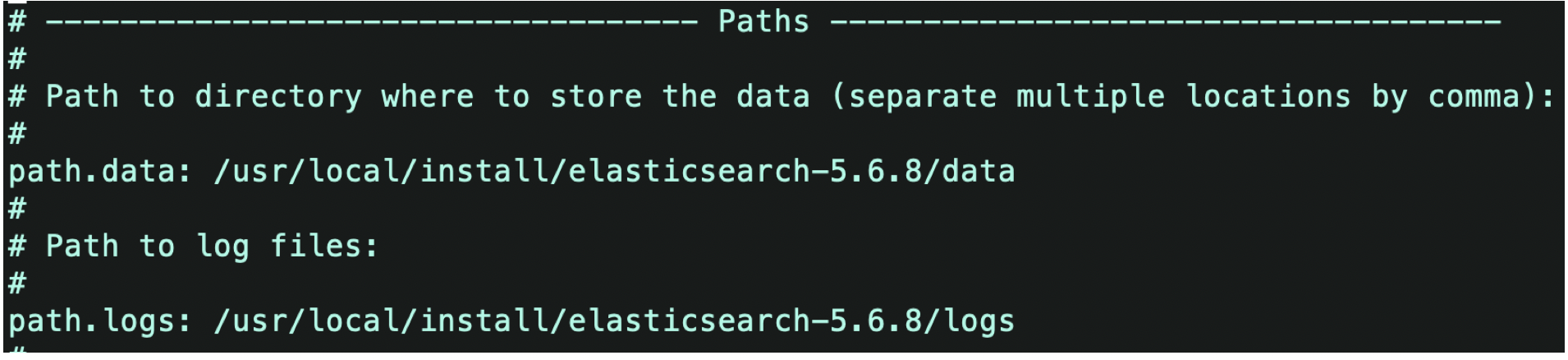
修改绑定ip,允许任何ip访问

其他问题可以在以下两个博客找到解答:
常见问题解决
报bootstrap checks failed错误
2)如果遇到lock的情况,需要杀死进程重新运行,因为elasticsearch基于java
所以可以用jps查看进程
kill -9 杀死进程
(5)kibana可视化界面
因为Kibana基于node,所以需要先配置nodejs环境,其他过程很简单,也不会遇到什么问题,我就直接贴图了
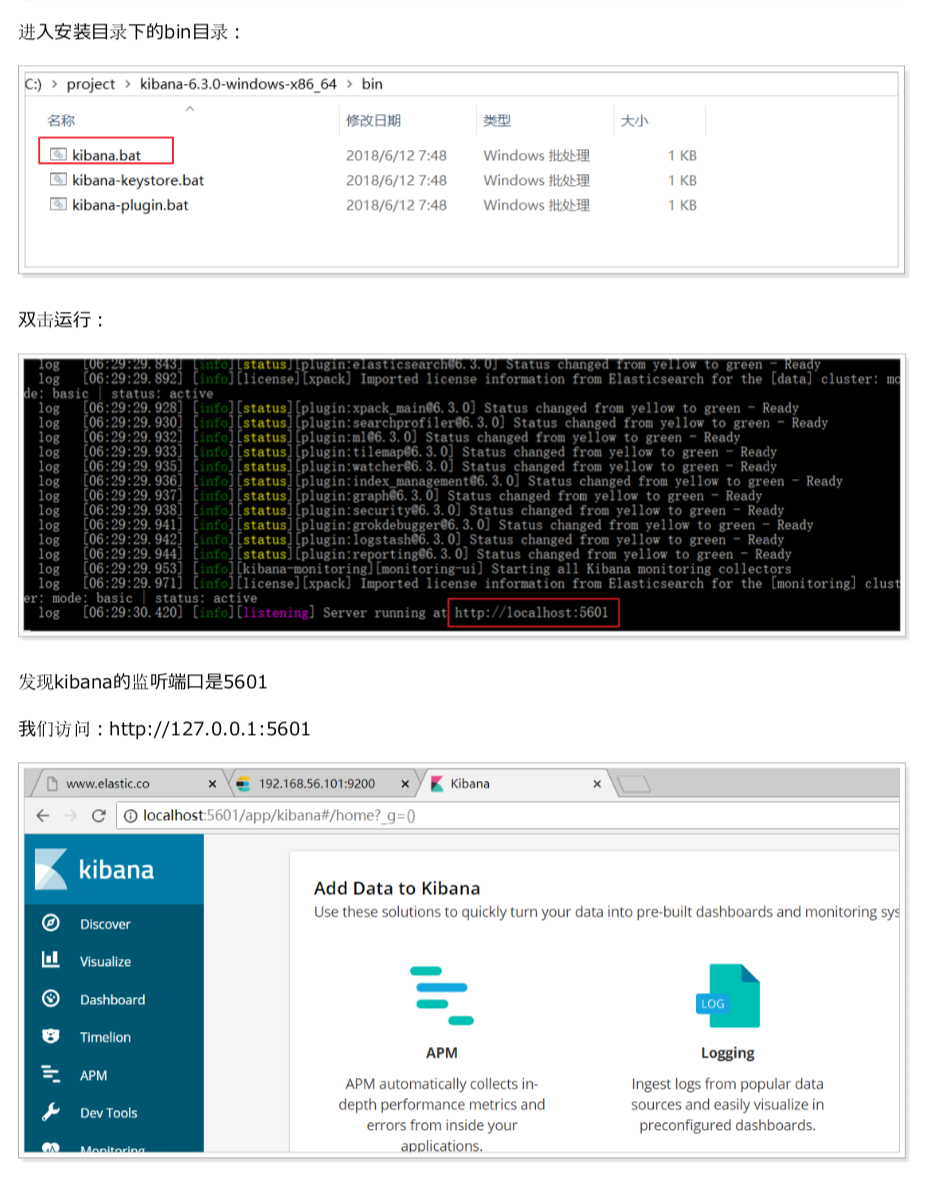
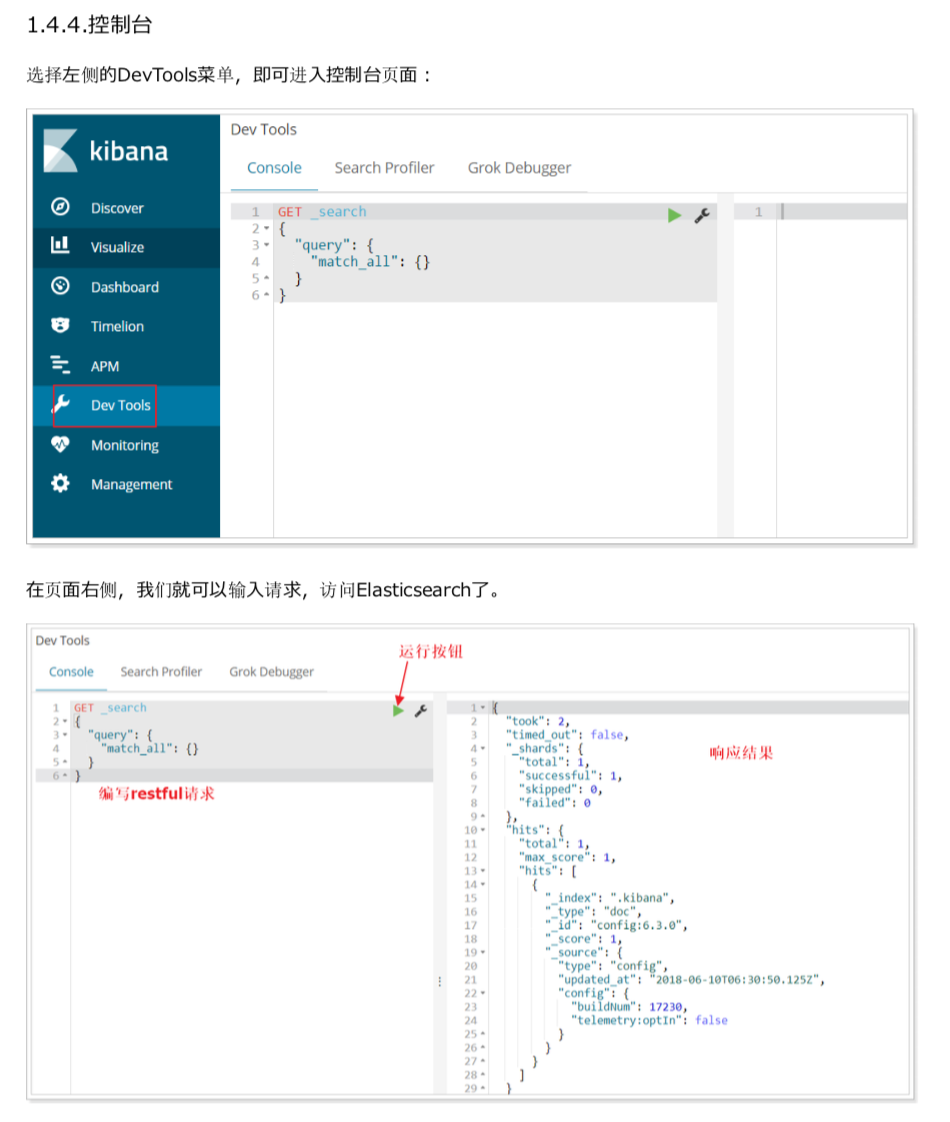
(6)grafana图像化界面
过程同样简单,直接通过以下链接配置
1)在windows下安装运行grafana
2)grafana与elasticsearch结合
三、启动
(1) filebeat
1)cd /usr/local/install/filebeat-5.6.8-linux-x86_64
2)./filebeat -e

(2) redis
配置中的一个问题
vi /etc/redis/redis.conf

bind 0.0.0.0表示可以监听来自任何地址的内容
因为我的数据是从filebeat发送到redis,所有bind可以改成filebeat的地址,只监听来自filebeat的数据
1)cd /etc/redis/
2)redis-server redis.conf //运行redis.conf的配置文件
3)ps -ef | grep redis //查看redis进程,检查是否启动
4)redis-cli //客户端连接
(3) logstash
1)cd /usr/local/install/logstash-5.6.8/bin
2)./logstash -f redis.conf
(4)elasticsearch
注意:为了安全,只能使用普通用户启动
1)cd /usr/local/install/elasticsearch
2) ./elasticsearch
3)测试:ip:9200
(5) kibana
在windows系统中安装
1) 运行kibana.bat
2) 访问:localhost:5601