爬取豆瓣正在上映的电影
1.目标
爬取豆瓣上显示正在上映的电影的信息,包括电影名、评分、导演、主演等信息。将其保存在一个CSV文件中,可以使用Excel打开查看。
2.思路分析
1.获取网页的URL
2.请求网页的源代码
3.解析源代码,提取目标信息
4.保存信息
3.准备工作
1.请求网页源代码使用webdriver.Chrome()
2.解析网页使用xpath
4.实施阶段
1.获取URL
https://movie.douban.com/cinema/nowplaying/xian/
2.请求网页的源代码
driver = webdriver.Chrome()
driver.get(r'https://movie.douban.com/cinema/nowplaying/xian/')
html=driver.page_source
driver.close()
3.分析网页源代码
使用Chrome查看玩野源代码,可以发现正在上映的电影都在该标签之下
而且,每一部电影都在一个li标签中,而我们需要的信息就包含在其中,我们只需要获取到,并且将之提取出来即可。

4.提取目标信息
html = etree.HTML(html)
title = html.xpath('//*[@id="nowplaying"]//li/ul/li[2]/a/@title')
actor = html.xpath('//*[@id="nowplaying"]//li/@data-actors')
score = html.xpath('//*[@id="nowplaying"]//li/@data-score')
duration = html.xpath('//*[@id="nowplaying"]//li/@data-duration')
director = html.xpath('//*[@id="nowplaying"]//li/@data-director')
5.保存信息
使用pandas创建DataFrame,并且将数据存储为.csv 文件
df=pd.DataFrame(data=data,columns=['电影','评分','导演','主演','时长'])
df.to_csv('豆瓣最近上映.csv',encoding='gb18030')
为了能使用Excel查看保存的文件,保存文件是使用的编码的方式是gb18030
5.程序源代码
# -*- coding: utf-8 -*-
from selenium import webdriver
from lxml import etree
import pandas as pd
def get():
driver = webdriver.Chrome()
driver.get(r'https://movie.douban.com/cinema/nowplaying/xian/')
html=driver.page_source
driver.close()
#整理文档对象
html = etree.HTML(html)
title = html.xpath('//*[@id="nowplaying"]//li/ul/li[2]/a/@title')
actor = html.xpath('//*[@id="nowplaying"]//li/@data-actors')
score = html.xpath('//*[@id="nowplaying"]//li/@data-score')
duration = html.xpath('//*[@id="nowplaying"]//li/@data-duration')
director = html.xpath('//*[@id="nowplaying"]//li/@data-director')
data=list(zip(title,score,director,actor,duration))
return data
def saving(data):
df=pd.DataFrame(data=data,columns=['电影','评分','导演','主演','时长'])
df.to_csv('豆瓣最近上映.csv',encoding='gb18030')
def main():
data=get()
saving(data)
if __name__ == '__main__':
main()
6.结果显示
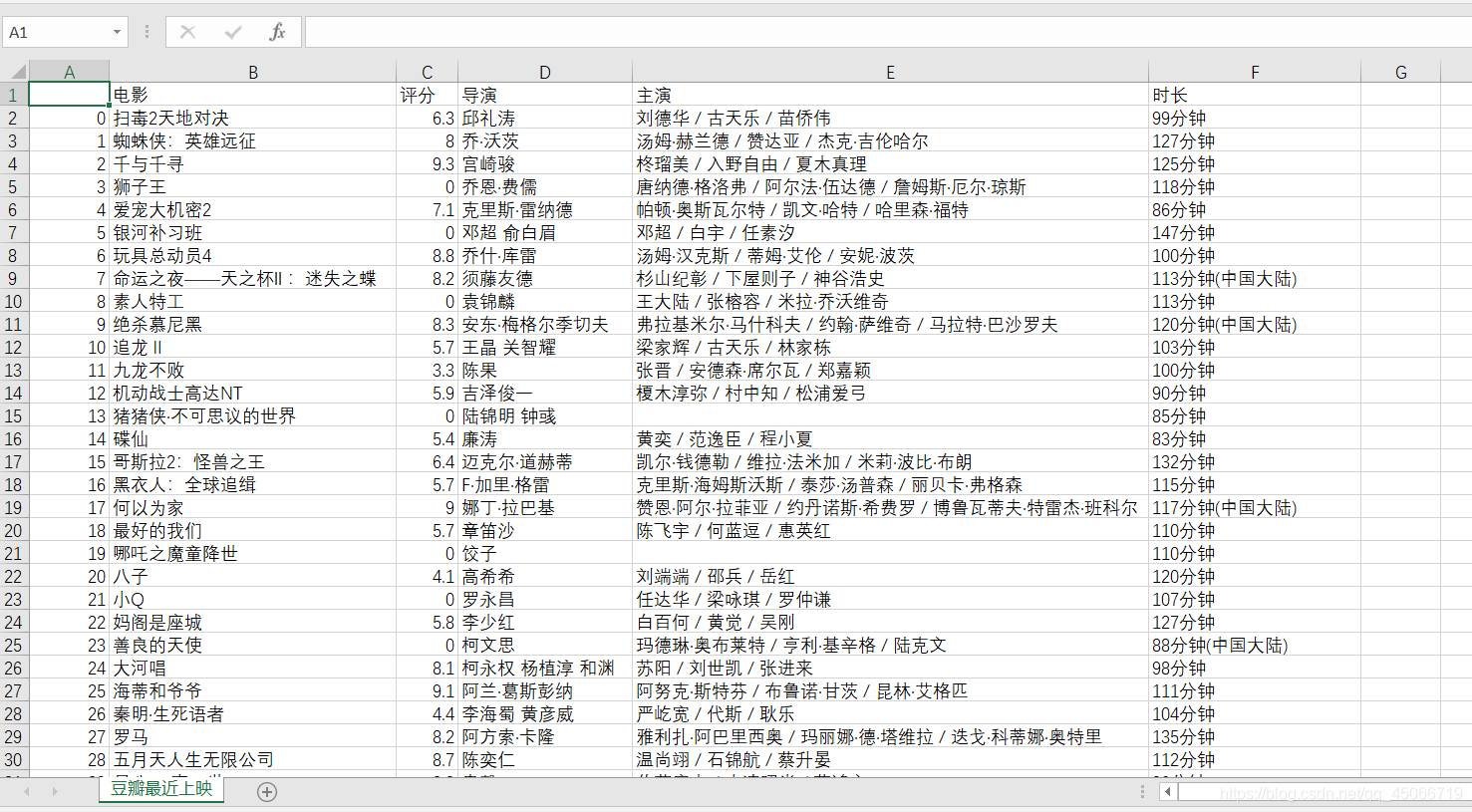
7.评价
1.可以发现爬取到的信息有部分是缺失的或者是异常的,例如在评分一列,值为0的数据是该电影暂未评分,我们同样可以使用pandas进行简单的数据清洗。
- 保存的
CSV文件会自己添加索引号,如果不想要,在保存文件的时候可以自己设置。