一、 HashSet哈希表存储、重复元素存储底层探究
我们首先要知道,
set集合中元素不可以重复;(只限对于字符串、八大基本数据类型)
set集合中的元素是无序的(存入和取出的顺序不一定一致)
1.如以下代码:
package com.huangzhiyao.set;
import java.util.HashSet;
import java.util.Set;
public class Text2 {
public static void main(String[] args) {
Set set=new HashSet<>();
set.add("lm");
set.add("qb");
set.add("lm");
set.add("xf");
System.out.println(set.size());
}
}
运行结果:

由运行结果可以得知 set集合中元素不可以重复。
2.再如以下代码:
package com.huangzhiyao.se't;
import java.util.HashSet;
import java.util.Set;
public class Text2 {
public static void main(String[] args) {
Set set=new HashSet<>();
set.add(new Person("laomo", 18, 1500));
set.add(new Person("dabai", 23, 500));
set.add(new Person("xiaoxi", 19, 1200));
set.add(new Person("goudan", 22, 2500));
set.add(new Person("laomo", 18, 1500));//这里数据与第一条数据相同
System.out.println(set.size());
}
}
//定义Person类
class Person{
private String name;
private int age;
private int money;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getMoney() {
return money;
}
public void setMoney(int money) {
this.money = money;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", money=" + money + "]";
}
public Person(String name, int age, int money) {
super();
this.name = name;
this.age = age;
this.money = money;
}
public Person() {
super();
}
}
由此运行后打印结果为5,所以set重复只限于只限对于字符串、八大基本数据类型。
3.再比如下面这个代码:
package com.huangzhiyao.set;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Text2 {
public static void main(String[] args) {
Set set=new HashSet<>();
set.add(new Person("laomo", 18, 1500));
set.add(new Person("dabai", 23, 500));
set.add(new Person("xiaoxi", 19, 1200));
set.add(new Person("goudan", 22, 2500));
set.add(new Person("laomo", 18, 1500));//这里数据与第一条数据相同
Iterator it=set.iterator();//定义一个迭代器
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
//定义Person类
class Person{
private String name;
private int age;
private int money;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getMoney() {
return money;
}
public void setMoney(int money) {
this.money = money;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", money=" + money + "]";
}
public Person(String name, int age, int money) {
super();
this.name = name;
this.age = age;
this.money = money;
}
public Person() {
super();
}
}
多运行几次打印后会发现顺序不同,那么我们可以知道set集合中的元素是无序的(存入和取出的顺序不一定一致)。
那么HashSet是如何保证元素唯一性的呢?
通过元素的两个方法:hashCode与equals方法来完成;
如果hashCode值相同,才会判断equals是否为true;
如果hashCode值不同,那么不会调用equals。
所以关于set存储自定义类时,判断是否重复需要根据需求重写hashCode()和equals(Object obj)方法。
如以下代码:
package com.huangzhiyao.set;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Text2 {
public static void main(String[] args) {
Set set=new HashSet<>();
set.add(new Person("laomo", 18, 1500));
set.add(new Person("dabai", 23, 500));
set.add(new Person("xiaoxi", 19, 1200));
set.add(new Person("goudan", 22, 2500));
set.add(new Person("laomo", 18, 1500));//这里数据与第一条数据相同
//System.out.println(set.size());
Iterator it=set.iterator();//定义一个迭代器
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
//定义Person类
class Person{
private String name;
private int age;
private int money;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getMoney() {
return money;
}
public void setMoney(int money) {
this.money = money;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", money=" + money + "]";
}
public Person(String name, int age, int money) {
super();
this.name = name;
this.age = age;
this.money = money;
}
public Person() {
super();
}
@Override
public int hashCode() {
System.out.println("hashCode---------"+this.name);
int code=this.name.hashCode()+this.age;//算一个name和age的哈希码值的和
System.out.println(code);
return code;
}
@Override
public boolean equals(Object obj) {
System.out.println("equals---");
Person p=(Person)obj;
return this.name.equals(p.name) && this.age==p.age;
}
}
二、集合框架TreeSet(自然排序、数据结构二叉树、比较器排序)
1.TreeSet自然排序
使元素具备比较性,在对象的类中实现Comparable接口,重写compareTo方法
TreeSet排序的第一种方式,让元素自身具有比较性;
元素需要实现Comparable接口,覆盖compareTo方法;
这种方式也被称为元素的自然顺序,或者叫做默认顺序
比如运行以下代码:
package com.huangzhiyao.set;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet set=new TreeSet<>();
set.add(74); //存放int类型排序
set.add(14);
set.add(68);
set.add(23);
System.out.println(set);
}
}
运行结果如下:
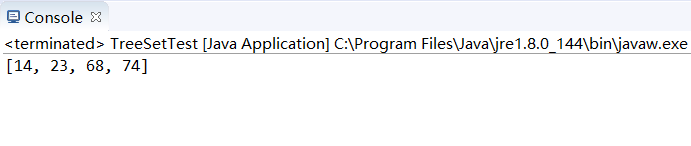
又如:
package com.huangzhiyao.set;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet set=new TreeSet<>();
// set.add(74); //存放int类型排序
// set.add(14);
// set.add(68);
// set.add(23);
set.add("q"); //存放String类型排序
set.add("x");
set.add("a");
set.add("qw");
set.add("c");
System.out.println(set);
}
}
运行结果如下:

咱们可以发现存放时是乱的,取出来的时候自动进行了排序。
2.数据结构二叉树
可以对set集合进行排序,底层数据结构是二叉树
package com.huangzhiyao.set;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet set=new TreeSet<>();
set.add(new Person("wanting", 18, 1500));
set.add(new Person("zhuangyuan", 23, 500));
set.add(new Person("runchen", 19, 1200));
set.add(new Person("xiang", 22, 2500));
set.add(new Person("wantings", 88, 1500));
// System.out.println(set);
Iterator it = set.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
//定义Person类
class Person implements Comparable<Person>{
private String name;
private int age;
private int money;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getMoney() {
return money;
}
public void setMoney(int money) {
this.money = money;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", money=" + money + "]";
}
public Person(String name, int age, int money) {
super();
this.name = name;
this.age = age;
this.money = money;
}
public Person() {
super();
}
@Override
public int hashCode() {
System.out.println("hashCode---------"+this.name);
int code=this.name.hashCode()+this.age; //算一个name和age的哈希码值的和
System.out.println(code);
return code;
}
@Override
public boolean equals(Object obj) {
System.out.println("equals---");
Person p=(Person)obj;
return this.name.equals(p.name) && this.age==p.age;
}
/**
*
* 让元素具有比较性
*
* 注意:在做自然排序方法重写的时候,一定要先判断主要条件,还要判断次要条件
*
*/
@Override
public int compareTo(Person o){
int num=o.money-this.money;
if(num==0) {
return o.age-this.age;
}
return num;
}
}
3.TreeSet比较器排序
当元素自身不具备比较性时,或者具备的比较性不是所需要的时候
这时需要让集合自身具备比较性,在集合初始化时,就有了比较方式;
比如做个年少多金的例子
如以下代码:
package com.huangzhiyao.set;
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet<Person> set = new TreeSet<>(new PersonMoneyAgeComp());// 调用比较器
set.add(new Person("王五", 12, 1000));
set.add(new Person("王五", 12, 1800));
set.add(new Person("张三", 18, 1900));
set.add(new Person("张三丰", 22, 5000));
set.add(new Person("李四", 90, 1000));
Iterator it = set.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
/**
* 比较器排序 需求:money多 age小
*/
class PersonMoneyAgeComp implements Comparator<Person> {
@Override
public int compare(Person o1, Person o2) {
// TODO Auto-generated method stub
int num = o2.getMoney() - o1.getMoney();// 比较money
if (num == 0) {// 当money相等时
return o1.getAge() - o2.getAge();// 比较age
}
return num;
}
}
/**
* age比较
*
* @author 10570
*
*/
class Person implements Comparable<Person> {
private String name;
private int age;
private int money;
public Person(String name, int age, int money) {
super();
this.name = name;
this.age = age;
this.money = money;
}
public Person() {
super();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getMoney() {
return money;
}
public void setMoney(int money) {
this.money = money;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", money=" + money + "]";
}
// 重写hashcode方法
@Override
public int hashCode() {
// TODO Auto-generated method stub
int code = this.name.hashCode() + this.age;// 计算名字和年龄的值
System.out.println(this.toString() + "-----code:" + code);// 查看code值
return code;
}
// 重写equals
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
Person p = (Person) obj;
System.out.println("比较名字:" + this.name + "---" + p.name);
System.out.println("比较年龄:" + this.age + "---" + p.age);
return this.name.equals(p.name) && this.age == p.age;// 当值code相等时,就比较名字和年龄是否相等
}
/**
* 让元素具备比较性 注意:在做自然排序方法重写的时候,一定先判断主要条件、还要判断次要条件
*/
@Override
public int compareTo(Person o) {
// TODO Auto-generated method stub
return this.age - o.age;
}
}
运行结果:

以上咱们可以看到 money多的在前面, 而当money相等时,age小的在前面。
咱们再把条件改成:年纪大 钱多
/**
* 比较器排序 需求:age大 money少
*/
class PersonAgeMoneyComp implements Comparator<Person>{
@Override
public int compare(Person o1, Person o2) {
// TODO Auto-generated method stub
int num = o2.getAge() - o1.getAge();
if(num == 0) {//当money相等时
return o1.getMoney() - o2.getMoney();
}
return num;
}
}
运行后:

三、泛型
1.什么是泛型?
不使用泛型的情况下,会将未知的错误表现在运行期。
如果说用代码去处理了这个可能发现的错误,那么运行时期的错误就不会暴露出来。
例如:
package com.huangzhiyao.set;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class FanXinTest {
public static void main(String[] args) {
List c = new ArrayList();
c.add(22);
c.add(23);
c.add(26);
c.add(28);
c.add(55);
c.add("错误");
Iterator it = c.iterator();
while(it.hasNext()) {
Object obj = it.next();
int num = (int) obj;
if(num % 2 == 0) {
System.out.println(num);
}
}
}
}
运行结果:
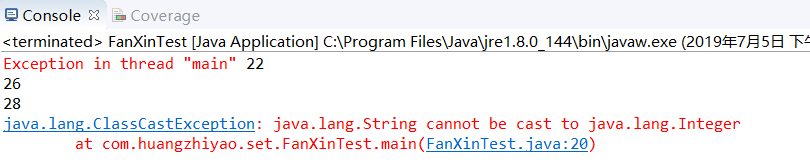
加上泛型后:

2.泛型的好处
(1)将运行期的异常转换成编译期的错误,让程序员更早的发现,从而解决代码隐患。
(2)提高了代码的健壮性。
3.泛型的简单应用
/*
* 购物车项目
* 订单模块、用户模块、商品模块
* Class OrderDao{
* public List<Order> list(Order o){}
* public int add(Order o){}
* public int edit(String id,Order o){}
* public int del(String id){}
*
* }
* Class UserDao{
* public List<User> list(User u){}
* public int add(User u){}
* public int edit(String id,User u){}
* public int del(String id){}
*
* }
* * Class ProductDao{
* public List<Product> list(Product p){}
* public int add(Product p){}
* public int edit(String id,Product p){}
* public int del(String id){}
*
* }
*
* ----不使用泛型的情况---
* ----使用泛型的情况---
* Class BaseDao<T>{
* public List<T> list(T t){}
* public int add(T t){}
* public int edit(String id,T t){}
* public int del(String id){}
* }
*Class OrderDao extends BaseDao<Order>{}
*Class UserDao extends BaseDao<User>{}
*Class ProductDao extends BaseDao<Product>{}
*
*/