Set
看下jdk中集合框架部分的类图:
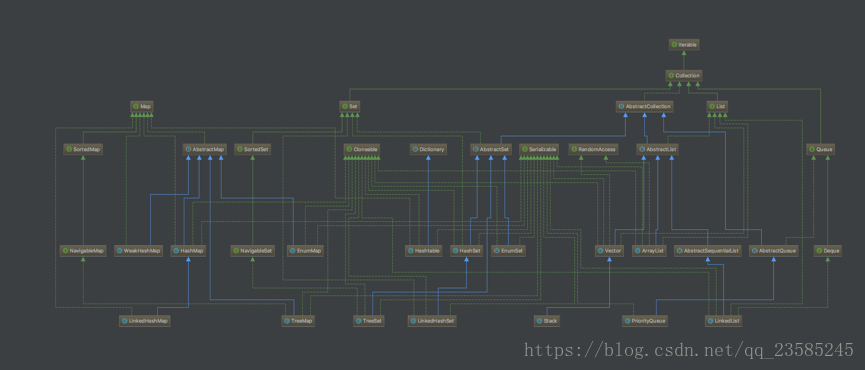
是不是被这密密麻麻的关系吓到了,其实里面的体系没有想象的那么复杂,java集合体系主要分为四大类:set,queue,list和map,由collection和map两个接口派生出,set,queue和list继承coeelction。这篇文章主要学习其中的set部分。
1.set介绍
*无序指的是放入和取出的顺序不同。
set和数组的区别:
(1) 数组大小被固定,set没有固定大小;
(2)数组可以放入重复数据,set不行。
2.set的主要的几种实现
我们主要了解set中的HashSet,LinkedHashSet,TreeSet和EnumSet.
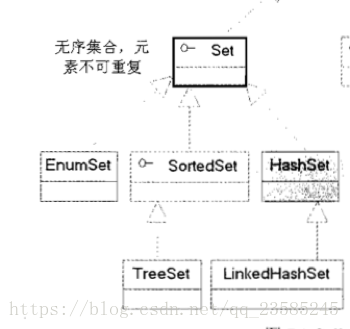
图.(疯狂java中的集合继承树)
以下都会通过具体实例来说明各自的特点。
HashSet:
package com.ljw.ColleactionAndMap;
import java.util.HashSet;
import java.util.Set;
/**
* Created by liujiawei on 2018/6/27.
*/
public class TestSet {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add(1);
hashSet.add(1);
hashSet.add(2);
hashSet.add(4);
hashSet.add(3);
hashSet.add(null);
System.out.println("放入hashset中的数据依次是:1,1,2,4,3,null");
System.out.println("输出hashset中的数据依次为:" + hashSet);
}
}
 通过上面的代码,可以看到我们从hashset中取出数据的顺序并不是按照我们放入的顺序来的,这说明hashset是无序的,同时重复的数据并没有被成功加入到集合中。
通过上面的代码,可以看到我们从hashset中取出数据的顺序并不是按照我们放入的顺序来的,这说明hashset是无序的,同时重复的数据并没有被成功加入到集合中。
总结一下HashSet特点:
(1)hashset是无序的;(2)hashset允许插入null;
(3)hashset不支持插入重复数据;
(4)hashset是线程不安全,多个线程同时访问同一个hashset时,要保证线程安全。
LinkedHashSet:
LinkedHashSet是hashset的子类,它也是通过hashcode来决定元素的存储位置,但同时用链表维护元素的顺序,所以LinkedHashSet的取出顺序和放入顺序是一致的,看下具体实例。package com.ljw.ColleactionAndMap;
import java.util.LinkedHashSet;
/**
* Created by liujiawei on 2018/6/27.
*/
public class TestSet {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet();
linkedHashSet.add(1);
linkedHashSet.add(1);
linkedHashSet.add(2);
linkedHashSet.add(4);
linkedHashSet.add(3);
linkedHashSet.add(null);
System.out.println("放入linkedHashSet中的数据依次是:1,1,2,4,3,null");
System.out.println("输出linkedHashSet中的数据依次为:" + linkedHashSet);
}
}
运行结果:

(1)LinkedHashSet有序,放入顺序和取出顺序相同;
(2)LinkedHashSet允许插入null;
(3)LinkedHashSet不支持插入重复数据;
(4)LinkedHashSet也是非线程安全的。
(5)LinkedHashSet因为内部需要用链表维护元素的插入顺序,所以在性能上差于HashSet,但在迭代访问元素时具有优势。
TreeSet:
我们还是用上面那组数据来举例:
package com.ljw.ColleactionAndMap;
import java.util.HashMap;
import java.util.LinkedHashSet;
import java.util.TreeSet;
/**
* Created by liujiawei on 2018/6/27.
*/
public class TestSet {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
treeSet.add(1);
treeSet.add(1);
treeSet.add(2);
treeSet.add(4);
treeSet.add(3);
treeSet.add(null);
System.out.println(treeSet);
}
}运行结果:

我们可以看到运行报错了,可以看到具体报错信息是在添加null的时候报错,难道是因为treeset不支持插入null导致的报错么?
单独执行一下add(null)方法,运行也是报错的,看起来好像treeset并不支持插入null,我们继续往下分析,我们在类图中可以看到,TreeSet是sortedSet的唯一实现,它可以确保TreeSet内部的元素处于排序状态,它是通过实现comparator接口,来对对象进行排序的,也就是说插入null报错,只是因为null没有实现 comparator接口,我们写个小例子证明一下我们的观点:
TreeSet treeSet1 = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
if(o1 == null && o2 == null){
return 0;
}
return 0;
}
});
treeSet1.add(null);
System.out.println(treeSet1);

可以看到null已经被插进去了。
TreeSet在执行add()时,会调用对象的compare()方法来进行比较,也就是说往TreeSet中添加对象时,对象类需要实现Comparator接口, java中的常用类都已经实现了Comparator接口(摘自疯狂讲义):

这就是为什么TreeSet可以保证内部元素是处于排序状态的原因。
TreeSet提供了一些方法,用来提取数据(摘自疯狂讲义):
其实很好理解,因为TreeSet进行了排序,所以可以访问首尾位置的元素,以此衍生出这些方法。

总结一下TreeSet特点:
(1) TreeSet不允许插入重复数据;(2)TreeSet内部使用红黑树实现,数据处于排序状态;
(3)TreeSet添加元素时会进行比较,所以对象最好是同一类的对象;
*因为可以自己重写compare方法,所以我们可以实现定制排序(默认时升序):
我们写一个例子,对整型数据实现降序排序:
TreeSet treeSet1 = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
int a = (int) o1;
int b = (int) o2;
if(a > b){
return -1;
}else if(a == b){
return 0;
}else{
return 1;
}
}
});
treeSet1.add(1);
treeSet1.add(2);
treeSet1.add(3);
treeSet1.add(4);
System.out.println(treeSet1);
运行结果:

可以看到输出的数据是按照降序输出。
EnumSet(使用较少,用时补充):
总结一下EnumSet特点:
3.set使用场景
存放一组不确定数据大小、不在乎顺序、不重复的数据时,可以考虑使用set。
4.小结
HashSet和TreeSet 是Set的两个经典实现,HashSet的性能好于TreeSet,因为TreeSet内部使用了红黑树算法来对对象进行排序,需要耗费额外的性能。除非需要使用排序的set时使用TreeSet,其他时候都应该使用HashSet。
LinkedHashSet是HashSet的子类,它使用链表维护了元素插入的顺序,在迭代元素方面优于HashSet,插入、删除数据方面逊色于HashSet。HashSet,LinkedHashSet和TreeSet都是线程不安全的,可以使用Collections工具类进行操作(后续写到多线程时一起补充)。