前言:
对链接爬虫:
1、抓取它的图片地址
2、抓取标题
针对地址:https://bh.sb/post/44622
脚本:
import requests
from lxml import etree
r=requests.get('https://bh.sb/post/44622/').content
topic=etree.HTML(r)
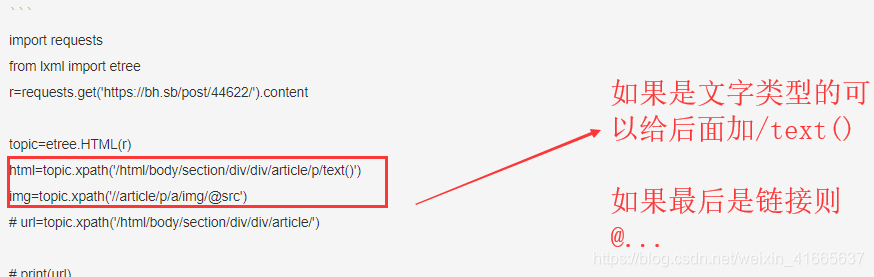
html=topic.xpath('/html/body/section/div/div/article/p/text()')
img=topic.xpath('//article/p/a/img/@src')
# url=topic.xpath('/html/body/section/div/div/article/')
# print(url)
for x in html:
print(x,end="")
for i in img:
print(i)
# print(html)
# print(img)
# print(html[1],img[1])
# print(r)

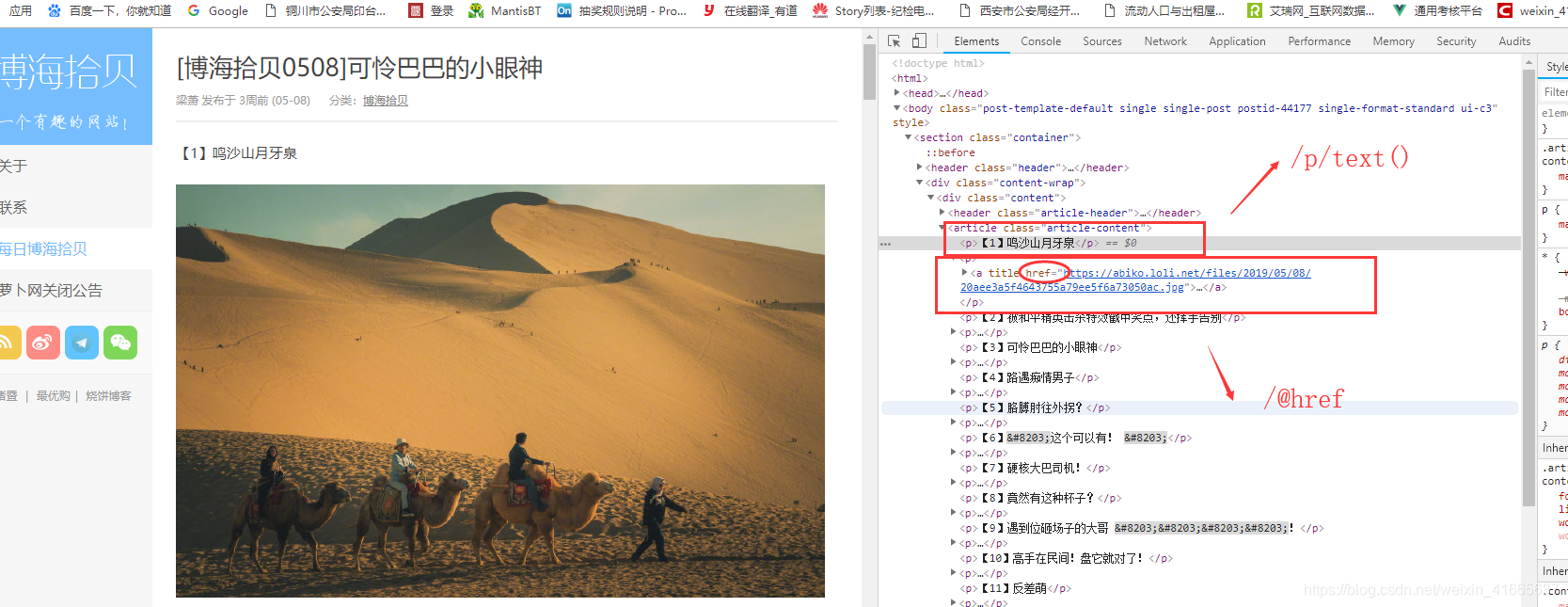
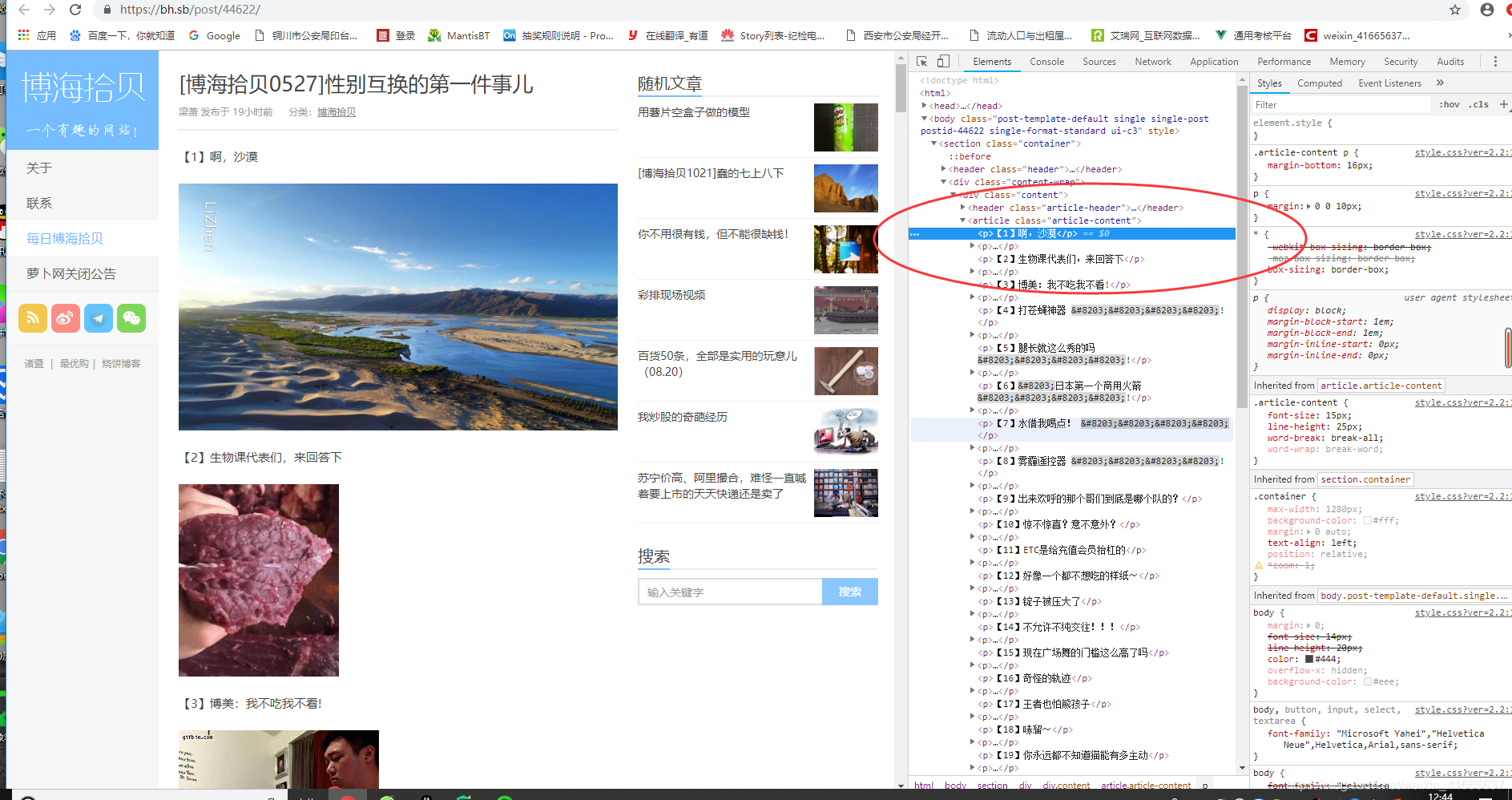
1、xpath的取法:
点击标题:谷歌浏览器-》右键-》检查-》copy-》xpath
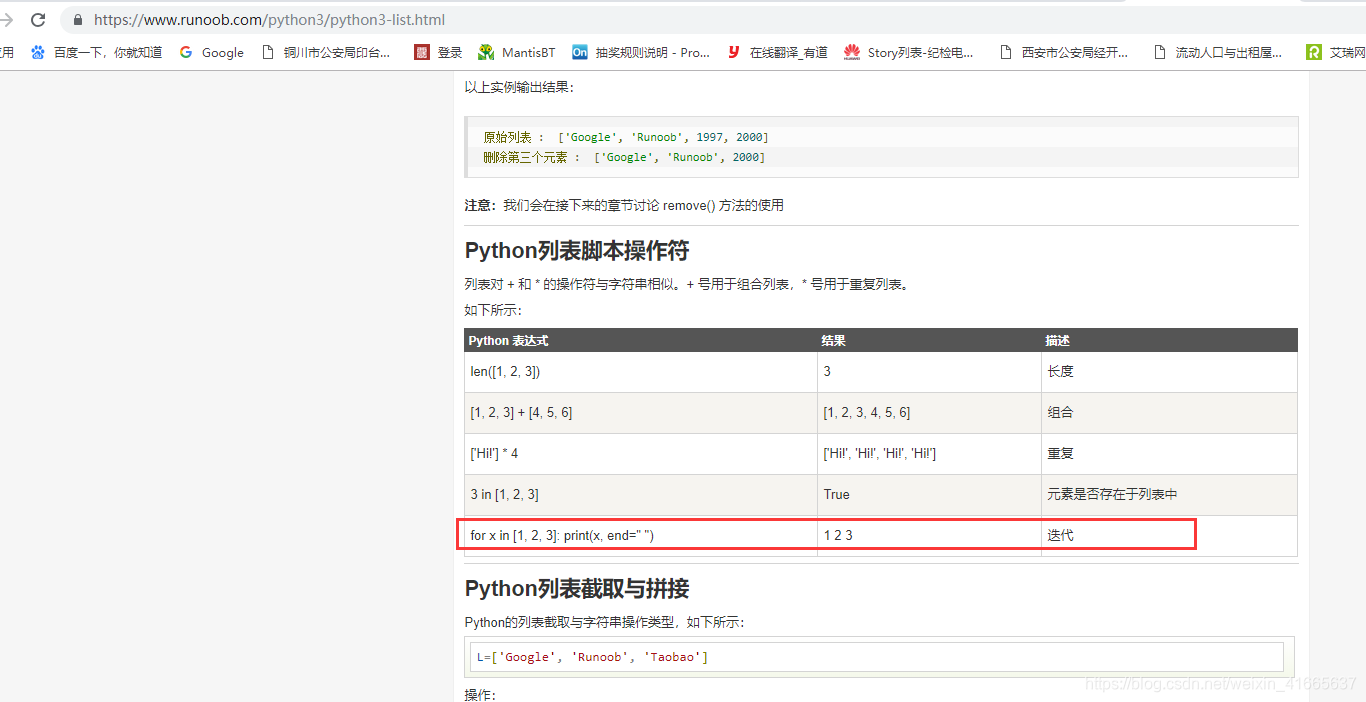
2、怎么把数组转换成正常字符-》菜鸟教程去查看
3、小节