版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Register_man/article/details/78911403
一、分析网站
游民星空的趣图网站为:http://www.gamersky.com/ent/qw/
点击下一页可以拉取到数据,但是网址未发生变化,查看Network标签,可以看到实际上进行了ajax请求,
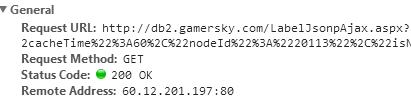
可以看到url地址是另外一个,而且get方法传递了参数:

扫描二维码关注公众号,回复:
3297210 查看本文章

其中jsondata中的page参数就是跳转的页数,改变它,就可以获得任意页面的数据了
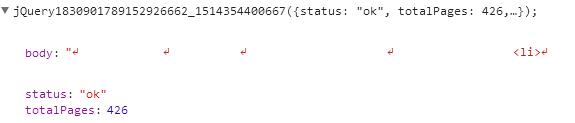
该方法返回值是一个json数据,其中body中保存了创建单条趣图的html代码,totalPages保存了总页数

对每个页面,使用xpath("//*[@class='con']/div[1]/a")查找到对应<a>标签即可对应页面的链接和标题
模拟访问链接时,在headers中提供User-Agent

二、代码
import requests
import re
from lxml import html
import xlrd
import xlwt
from xlutils3 import copy
import os
# ajax地址
list_url = "http://db2.gamersky.com/LabelJsonpAjax.aspx"
# excel文件名
file_name = 'gamesky_fun_list.xls'
# 匹配文本
pattern = "(福利|动态|囧图|内涵|轻松)"
# 趣图url列表
fun_list_url = []
workbook = None
table = None
if os.path.exists(file_name):
workbook = xlrd.open_workbook(file_name)
table = workbook.sheet_by_name('list')
def pull(current_page, max_page):
while current_page < max_page:
params = {
'callback': 'jQuery183010650035300910066_1514276718854',
# 此处jsondata的值不能是dict,否则服务器无法识别
'jsondata': '{"type": "updatenodelabel", "isCache": true, "cacheTime": 60, "nodeId": "20113", "isNodeId": true,"page": %d}' % (
current_page,), # 根据当前页号修改数据
'_': '1514276904732'
}
headers = {
'Accept-Language': 'zh-CN,zh;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
}
respond = requests.get(url=list_url, params=params, headers=headers)
# 使用content获取二进制表示,使用decode方法获取对应编码的字符串
# 此处这么做是为了防止中文乱码
html_text = respond.content.decode("utf-8")
# 将获得的json字符串生成dict
json = eval(html_text[html_text.find("(") + 1:html_text.rfind(")")])
# 总页码
max_page = json['totalPages']
# 获取html文档
document = html.fromstring(json['body'])
# 查询到a标签
titles = document.xpath("//*[@class='con']/div[1]/a")
# 当前页码+1
current_page += 1
print("current page : %d, max page :%d" % (current_page, max_page))
for title in titles:
# 获取标题文字
tit_str = title.text_content()
# 查询是否匹配
ret = re.search(pattern, tit_str)
if ret:
if table is not None:
for i in range(table.nrows):
if table.cell(i, 1).value == tit_str:
return
fun_list_url.append(title.attrib)
pull(0, 1)
worksheet = None
if workbook:
last_len = table.nrows
workbook = copy.copy(workbook)
worksheet = workbook.get_sheet('list')
# 将数据保存到xls中
for i in range(len(fun_list_url)):
print(fun_list_url[i])
worksheet.write(i + last_len, 0, fun_list_url[i]['href'])
worksheet.write(i + last_len, 1, fun_list_url[i]['title'])
else:
# 创建一个wordbook
workbook = xlwt.Workbook(encoding='utf-8')
# 添加一页
worksheet = workbook.add_sheet('list', cell_overwrite_ok=True)
# 写标题
row0 = ['href', 'title']
worksheet.write(0, 0, 'href')
worksheet.write(0, 1, 'title')
# 将数据保存到xls中
for i in range(len(fun_list_url)):
worksheet.write(i + 1, 0, fun_list_url[i]['href'])
worksheet.write(i + 1, 1, fun_list_url[i]['title'])
workbook.save(file_name)
运行完成后就会生成xls文件:
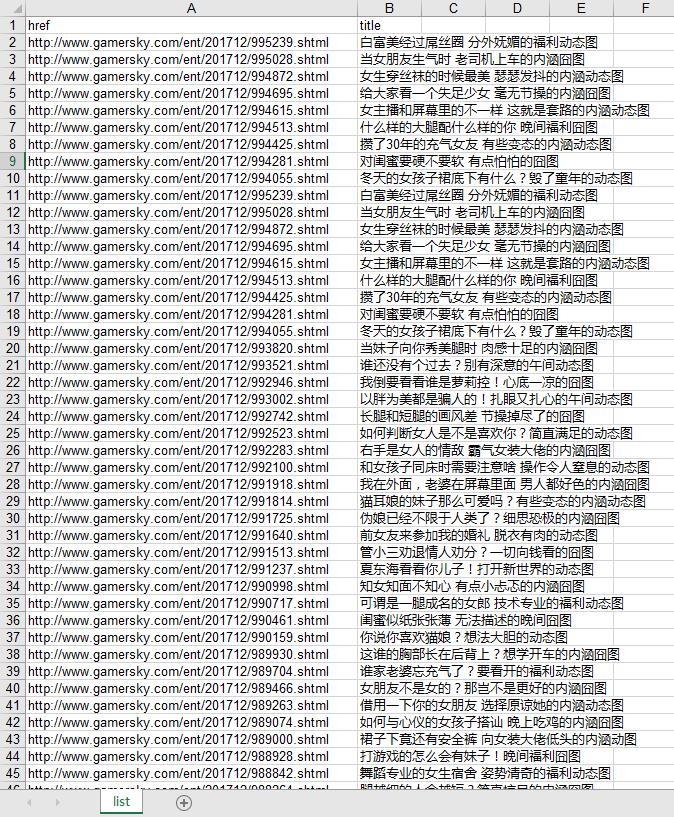
接下来只就需要对每个文章单独抓取图片