1、大赛赛制介绍
随着消费观念的升级,时尚行业拥有巨大的市场潜力。据权威机构统计,时尚行业全球市值已超3万亿美元。与此同时,AI技术也在不断发展,但在与时尚行业相互融合过程中,技术仍然面临重重挑战。
阿里巴巴“图像和美”团队联合香港理工大学纺织与制衣系共同举办2018 FashionAI全球挑战赛。大赛推出业界第一个同时符合服饰专业性和机器学习要求的大规模高质量时尚数据集,提供百万奖金池,召集全球人工智能研发者众智。大赛聚焦机器认知时尚的两个基础问题:服饰关键点定位和服饰属性标签识别,通过实战推动AI与时尚行业跨界融合。
赛程安排
本次大赛分为初赛、复赛和决赛三个阶段,具体安排和要求如下:
初赛(3月1日-4月21日,UTC+8)
1. 报名成功后,参赛队伍通过天池平台下载数据,本地调试算法,在线提交结果。若参赛队伍在一天内多次提交结果,新结果版本将覆盖旧版本。
2.比赛提供标准训练数据集(含标注),供参赛选手训练算法模型;提供标准测试数据集(无标注),供参赛选手提交评测结果参与排名。
3. 初赛一阶段:3月1日-4月18日。系统每天进行2次评测和排名,评测开始时间为当天12:00和22:00,按照评测指标从高到低进行排序,定时更新排行榜;排行榜将选择参赛队伍在本阶段的历史最优成绩进行排名展示。
4. 初赛二阶段:4月19日-4月21日。系统将在4月18日17:00更换测试数据,参赛队伍需再次下载数据文件。初赛成绩排行榜将选取4月19日起产生的成绩进行重新排名。
5. 初赛截止时间是4月21日12:00,TOP150团队需提交代码审核,组委会将识别并剔除只靠人工标注而没有算法贡献的队伍,晋级空缺名额后补。初赛成绩符合要求的排名前100名且通过支付宝实名认证的参赛队伍将进入复赛。(认证入口:天池网站-个人中心-认证-支付宝实名认证,要求初赛截至前完成认证,要求4月21日12:00 前完成认证)
复赛(4月26日-5月24日 ,UTC+8 )
1. 复赛参赛队伍通过天池平台下载新增的训练数据和更新的测试数据,本地调试算法,在线提交结果,若参赛队伍在一天内多次提交结果,新结果版本将覆盖旧版本。
2. 复赛一阶段: 4月26日12:00-5月22日12:00。从4月26日起,系统每天进行2次评测和排名,评测开始时间为当天12:00和22:00,按照评测指标从高到低进行排序,定时更新排行榜;排行榜将选择参赛队伍在本阶段的历史最优成绩进行排名展示。
3. 复赛二阶段:5月23日12:00-5月24日12:00。系统将在5月23日9:00更换测试数据,参赛队伍需再次下载数据文件。赛程期间系统每小时进行评测和排名,参赛队伍可自由选择提交时间,每支队伍限制5次提交机会(每次上传结果算做一次提交),机会用完即比赛结束。排行榜将选择参赛队伍在本阶段的历史最优成绩进行排名展示。该阶段截止时,要求TOP10团队提交代码审核。复赛代码审核通过的排名前5名的参赛队伍选手代表将受邀参加决赛。
决赛(7月4日-5日 ,UTC+8 )
1. 决赛将以现场答辩会的形式进行,晋级决赛团队需提前准备答辩材料,包括答辩PPT、参赛总结、算法核心代码。
2. 决赛将邀请每支队伍至多3位代表参加,由组委会承担差旅费用。具体安排另行通知。
3. 答辩现场,每支队伍面对评委有15分钟的陈述时间和10分钟的问答时间。评委将根据选手的技术思路、理论深度和现场表现进行综合评分。
4. 决赛分数将根据参赛队伍的算法成绩和答辩成绩加权得出。评分权重:复赛二阶段70%,决赛答辩30%。依据决赛分数评选出大赛奖项并举行隆重颁奖。
参赛对象
大赛面向全社会开放,个人、高等院校、科研单位、企业、创客团队等人员均可报名参赛,组队上限8人。
注:1)大赛组织机构单位中涉及题目编写、数据接触的人员禁止参赛;2)阿里巴巴集团员工和赛事合办单位参赛,可参与排名,但不参与评奖及领取奖金。
报名方式
1. 报名开始时间:2018年2月1日(UTC+8);
2. 截止报名及组队变更时间:2018年4月21日12:00(UTC+8);
3. 参赛队伍1-8人组队参赛,每位选手只能加入一支队伍;
4. 确保报名信息准确有效,否则会被取消参赛资格及激励;
5. 报名方式:用淘宝或阿里云账号登入天池官网,完成个人信息注册,即可报名参赛;
6. 大赛官方交流请至技术圈,选手交流钉钉群扫描以下二维码:

奖项设置
大赛总奖金池134万,每个赛道奖金池67万。
初赛激励
- 初赛冠军:获得价值壹万元人民币大赛奖品
决赛激励
- 冠军:1支队伍,奖金伍拾万人民币,颁发获奖证书
- 亚军:1支队伍,奖金拾万人民币,颁发获奖证书
- 季军:1支队伍,奖金伍万人民币,颁发获奖证书
- 决赛第4-5名:各1支队伍,奖金壹万人民币,颁发获奖证书
(上述奖项以决赛的最终得分排名决定)
阿里校招绿色通道
- 实习offer:决赛TOP3团队,获得阿里巴巴-图像和美组实习offer,每队限一名选手;
- 直通终面:复赛TOP10团队,获得阿里招聘直通终面资格,每队限两名选手;
- 免笔试:复赛TOP20团队,入围阿里校园招聘绿色通道(直接安排初面),在校期间均有效。
2、赛事数据
文件名称
文件格式
fashionAI_attributes_test_a_20180222.tar
.tar (795MB)fashionAI_attributes_test_b_20180418.tar
.tar (1GB)fashionAI_attributes_train_20180222.tar
.tar (6GB)files_md5_20180418.txt
.txt (377B)warm_up_train_20180201.tar
.tar (801MB)竞赛题目
服饰属性标签是构成服饰知识体系的重要根基,内部庞大复杂。我们对服饰属性进行了专业的整理和抽象,构建了一个符合认知过程,结构化且满足机器学习要求的标签知识体系。由此诞生的服饰属性标签识别技术可以广泛应用在服饰图像检索,标签导航,服饰搭配等应用场景。
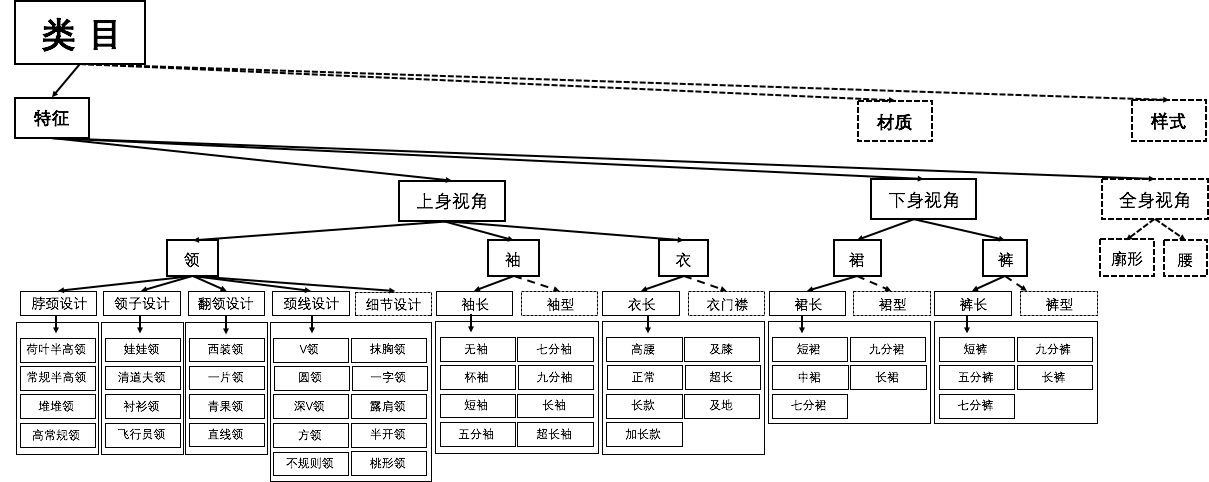
图1. 竞赛属性框架示意图
竞赛数据
术语说明:
a) 属性维度(AttrKey):比如袖长。是一个属性定义范畴。
数据来源:
图像数据采自阿里电商数据。
本赛道专注于服饰商品的局部属性识别,图中所有可清晰辨别的属性标签都要求预测。考虑到服饰知识的复杂性,本期我们只保留了单人模特的商品图数据,参赛选手可专注于解决属性标签任务中的挑战。
标签数据:
a) 图像由标注人员标注标签,经服饰专业研究人员复审,保证标注正确率。标注数据存在一定的missing-label的现象,比如,一个图中存在领型、袖长2个维度的属性,可能数据中只标注了领型1个维度的属性,袖长维度没有标注。这样保证了标签的均匀性。
b) 考虑到属性含义理解的复杂性,我们从属性标签知识体系中拿出了8种重要的属性维度进行比赛。这些属性维度是:颈线设计、领子设计、脖颈设计、翻领设计、袖长、衣长、裙长、裤长。具体示意,见下图:
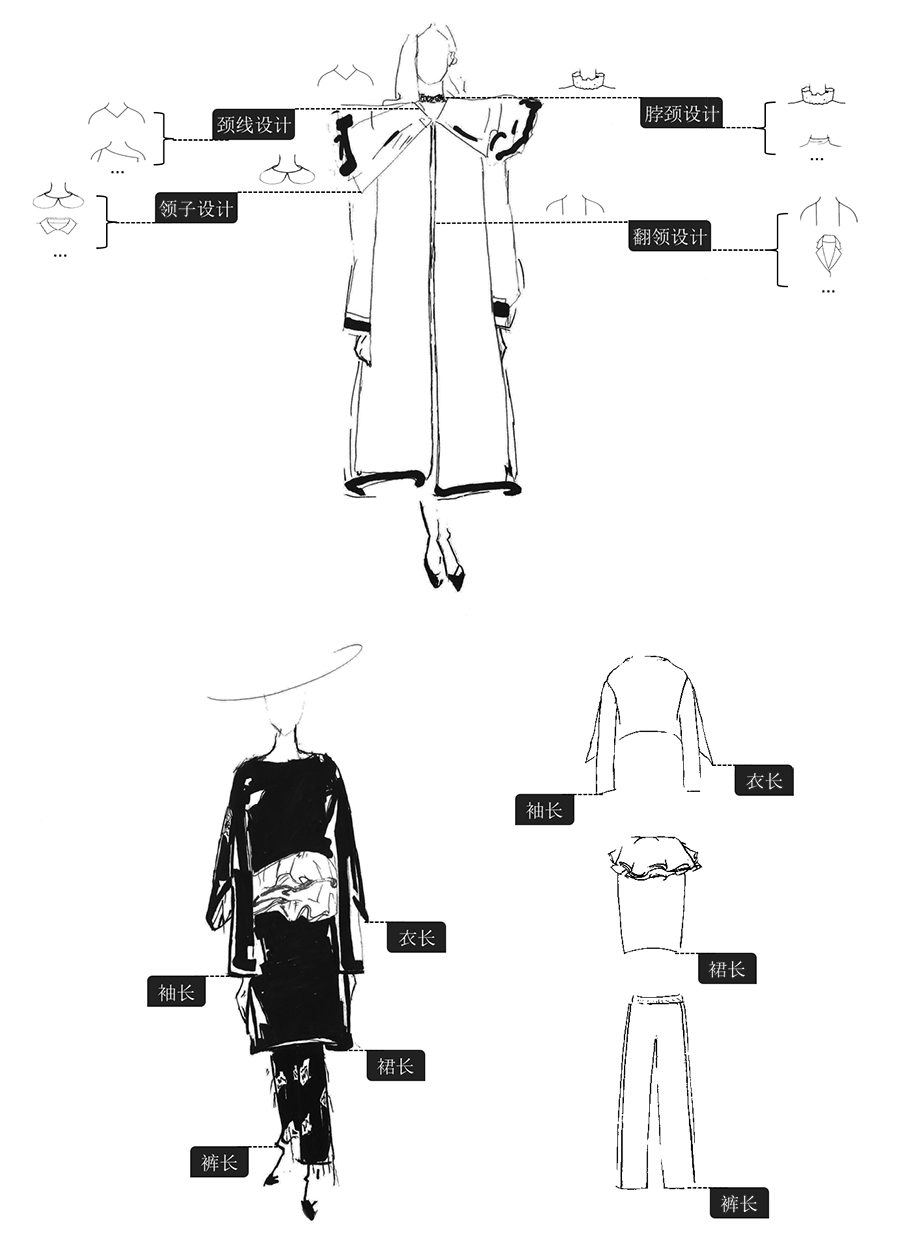
图2. 竞赛属性在模特图表征示意图
数据特性:
a) 互斥:一个属性维度下,属性值之间是互斥的,不能同时成立。比如脖颈设计维度,不能同时既是常规高领,又是荷叶半高领。这是一个“多选一”的问题。考虑到比赛的严谨性,我们去除了部分做不到互斥准则的数据。比如一个模特,叠穿多件单品,致使在同一个属性纬度出现了多个属性。
b) 独立:一个图像中,不同属性维度下的属性值可同时存在,它们之间相互独立。比如“领-脖颈设计-常规高领”和“领-领子设计-衬衫领”可以同时存在,且概念上相互独立。
c) 每个属性维度下都有一个属性值叫“不存在”。这个表示当前属性维度在该图像所展示的视角下,是被定义过的,但是该属性在图中并没有出现或者被遮挡看不见。比如一个模特身穿连衣裙的图片(如图5所示),它包含了上身视角和下身视角,所以衣长维度是需要被考虑的,然而它的裙摆被遮住了,衣长维度的属性值是“不存在”,在这类的遮挡或不可见情况下,我们考察模型的“否决”能力,但本期我们不考察对于图片中不存在的视角的属性维度的否决能力。比如,对于下身视角的裤子图片,不会考察对于上身视角的属性(比如“袖长”)否决能力。
训练数据文件结构
a) 我们将提供用于训练的图像数据和识别标签,文件夹结构:
o Images
o Annotations
o README.md
b) Images : 存放图像数据,jpeg编码图像文件。图像文件名如:0000001.jpg
c) Annotations : 存放属性标签标注数据,csv格式文件。
d) README.md:对数据的详细介绍。
训练数据示例

图3. 训练数据各属性示意图
上图对应的csv标注文件示例:
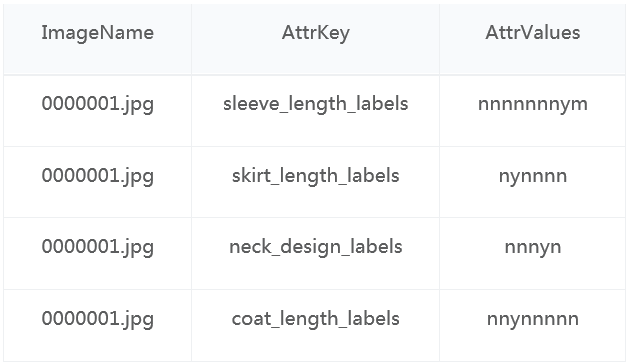
标注文件格式说明:
ImageName : 图像文件名,对应Images文件夹下面的图像文件
AttrKey :属性维度,比如袖长(sleeve_length_labels),裤长(pant_length_labels)等等
AttrValues :AttrKey属性维度对应的属性值。袖长属性维度(AttrKey)有9个属性值(AttrValues):不存在,无袖,杯袖,短袖,中袖,七分袖,九分袖,长袖,超长袖。分别对应上图示例标注数据中的:nnnnnnmyn。一共九位,每一位是下面三个值中的一个:
y(yes, 一定是) m(maybe, 可能是) n(no, 一定不是)
对某个图的某个属性维度的标注数据中,有且只有一个“y”标注,其余的可能是“m”或者“n”
袖长属性维度(AttrKey)对应它的属性值(AttrValues)的关系,将在README.md中详细说明。
模糊边界问题的定义:
模糊边界的现象在属性标签问题中,不可避免,如下图所示:
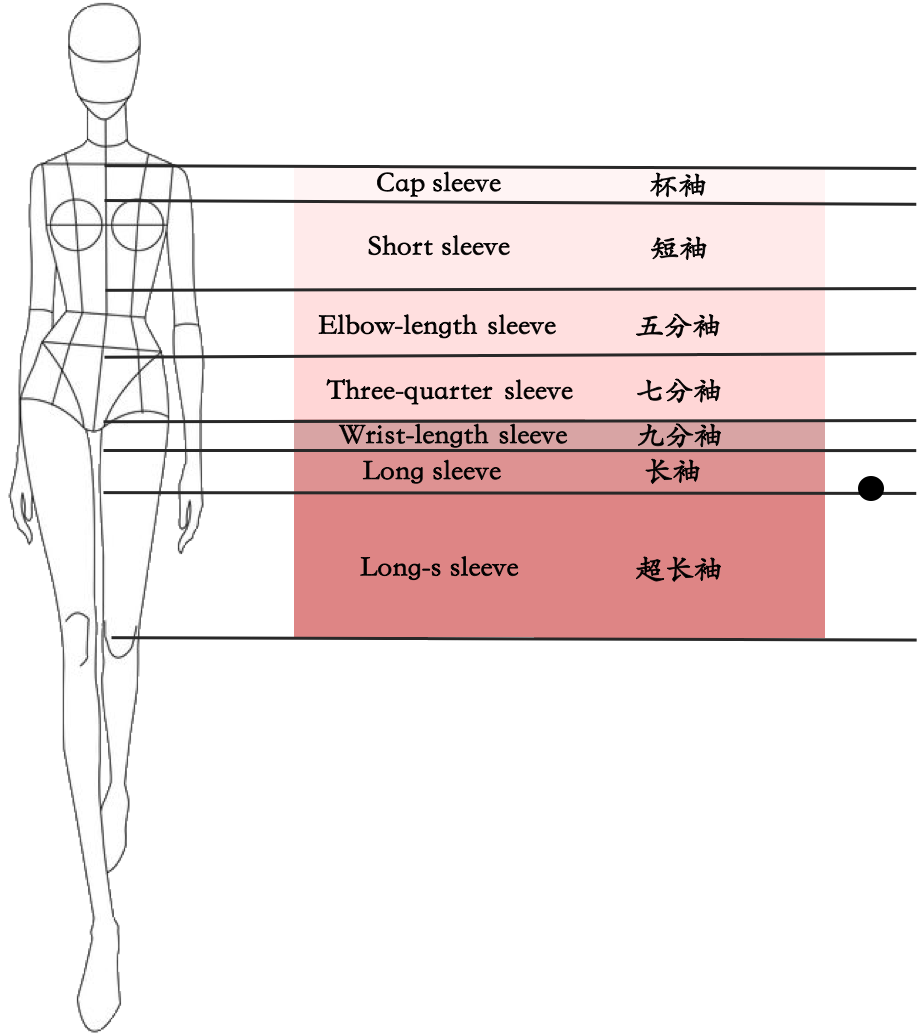
图4. 模糊边界示意图
上面示例中, 黑色点的位置是当前衣服的袖长。该点位于长袖和超长袖的分界线上,更多属于长袖。此时,”长袖位“对应标注"y",”超长袖位“对应标注"m",”其余位“是"n"。
遮挡问题的定义

图5. 属性值遮挡示意图
a) 在属性标签识别中,遮挡现象是不可避免的。
b) 如果上图示例的图像,裙子下沿被截图截掉,不太能准确判断裙长。此时,裙长的“不存在位”对应的标注为"y",“其余位”是"n"。此时skirt_length_labels维度对应的标注为ynnnnn。
提交说明
给出的测试数据
a) 比赛过程中,我们会定期给出一些数据,用于对大家的算法进行评测、评分。
文件夹结构:
o Images
o Annotations
o README.md
b) Images存放图像数据,jpeg编码图像文件。图像文件名如:0000001.jpg
c) Annotations存放需要参赛者模型计算的属性维度信息。参赛者需要对这些维度进行预测,输出各个属性值的预测概率,将“?”替换成计算出来的各个标签的预测概率值(分数)。我们将取最大的预测概率(分数)的属性值作为预测结果。csv格式文件:
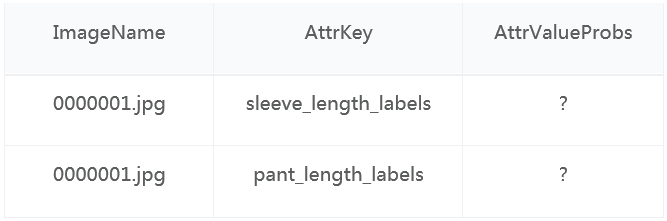
参赛者只需要提交一份csv压缩的zip文件即可,给出的测试数据Annotations文件夹下有提交示例csv文件,可作为参考:
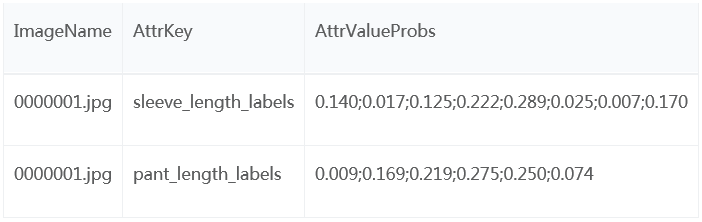
字段解释:
a) ImageName : 对应Images文件夹里面图像的名字;
b) AttrKey : 属性维度,比如袖长(sleeve_length_labels);
c) AttrValueProbs : 各个属性值的预测概率。我们用于计算mAP指标 。
评估指标
1. 录入参赛者提交的csv文件,为每条数据计算出AttrValueProbs中的最大概率以及对应的标签,分别记为MaxAttrValueProb和MaxAttrValue。
2. 对每个属性维度,分别初始化评测计数器:
BLOCK_COUNT = 0 (不输出的个数)
PRED_COUNT = 0 (预测输出的个数)
PRED_CORRECT_COUNT = 0 (预测正确的个数)
设定GT_COUNT为该属性维度下所有相关数据的总条数
3. 给定一个模型输出阈值(ProbThreshold),分析与该属性维度相关的每条数据的预测结果:
当MaxAttrValueProb < ProbThreshold,模型不输出:BLOCK_COUNT++
当MaxAttrValueProb >= ProbThreshold:
MaxAttrValue对应的标注位是'y'时,记为正确: PRED_COUNT++,PRED_CORRECT_COUNT++
MaxAttrValue对应的标注位是'm'时,不记入准确率评测:无操作
MaxAttrValue对应的标注位是'n'时,记为错误: PRED_COUNT++
4. 遍历使BLOCK_COUNT落在[0, GT_COUNT)里所有可能的阈值ProbThreshold,分别计算:
准确率(P):PRED_CORRECT_COUNT / PRED_COUNT
统计它们的平均值,记为AP。
5. 综合所有的属性维度计算得到的AP,统计它们的平均值,得出mAP。mAP将作为挑战赛——服饰属性标签识别赛道的竞赛排名得分。
6. 我们还会展示BasicPrecision指标,即模型在测试集全部预测输出(ProbThreshold=0)情况下每个属性维度准确率的平均值,作为更直接的准确率预估指标供大家参考。在BasicPrecision = 0.7时,排名得分mAP一般在 0.93 左右。
注意事项
此次挑战赛不限制参赛者使用外部数据/模型进行竞赛
但禁止以下行为:
a) 人工标注/修改评测结果数据
b) 多账号刷分等