在列表里面计数
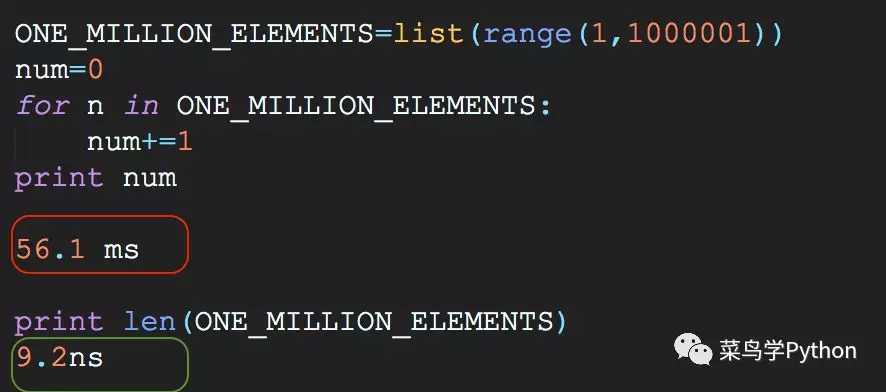
性能:第二种计数方法比第一种快6290倍,为啥因为Python原生的内置函数都是优化过的,所以能用原生的计算的时候,尽量用原生的函数来计算。
过滤一个列表

性能:第二种方法比第一种慢近50%,有人可能觉得filter应该会快一些,其实filter增加了复杂度,返回一个迭代对象再用list转化为一个列表,所以开销大一些。其实最快是推导列表,比第一种性能提高近30%。
异常处理

性能:第二种比第一种快了近3倍,简单粗暴直接用异常,而第一种会通过内置函数hasattr来先检查,查找内部类的属性,增加了开销。
列表成员检查

性能:第二种比第一种快了1倍,直接用in这样的方法检查列表内部成员比遍列要快很多的。当然如果你的num是在列表的头部,搜索会更快!
去重

性能:第二种比第一种快了近400倍,所以能用原生的内置的数据结构,一定要用原生的。不过相信大部分同学去重都开始用set了。
列表的排序
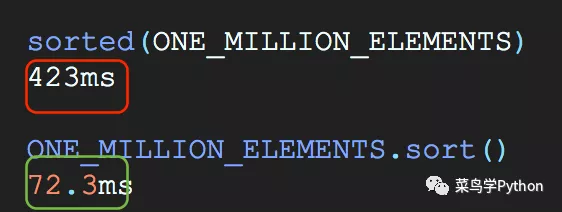
性能:第二种比第一种快了近6倍,sorted函数会把原来的列表进行排序然后再返回一个新的列表,而sort函数直接再原来的列表上面排序,节省了开销。
把迭代循环放到函数里面

性能:第二种要比第一种快了20%多,原因是因为把重复的循环直接放到了一次性的塞入函数,要把你调用1000次函数开销小很多。
检查是否为True

性能:最快的是第三种(直接用if)比第一种快了60%,不需要用借助==和is来进行判断。因为==会调用内置的魔法函数__eq__来比较左右两边的类型,而直接用if来判断var是否为空,None,空的列表,字典会快很多。
检查列表是否为空
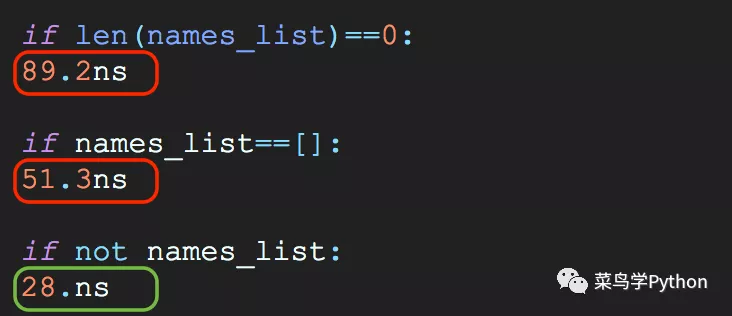
性能:第三种最快,第三种比第一种快了3倍;其实大部人新手都喜欢用len来判断,其实我也是,这个习惯要改。
直接创建容器

性能:没有对比没有伤害,因为Python一切皆对象,所以当你用list()生成一个对象的时候会产生开销,而[]直接返回一个list,会快很多,同理dict也是一样的。