val rdd1 = sc.parallelize(List(2,3,4,1,7,5,6,9,8))
获取分区的个数:rdd1.partitions.length,在spark-shell中没有指定分区的个数获取的是默认分区数,除了这个外parallelize方法可以使用,指定几个分区就会有几个分区出现
val rdd1 = sc.textFile("hdfs://hadoop02:8020/word.txt",3).flatMap _.split('')).map((_,1)).reduceByKey(_+_)
textFile这个方法是有默认值就是2 除非改变loacl中的即默认值这个只要这个默认值小于2的话会使用小于默认的值
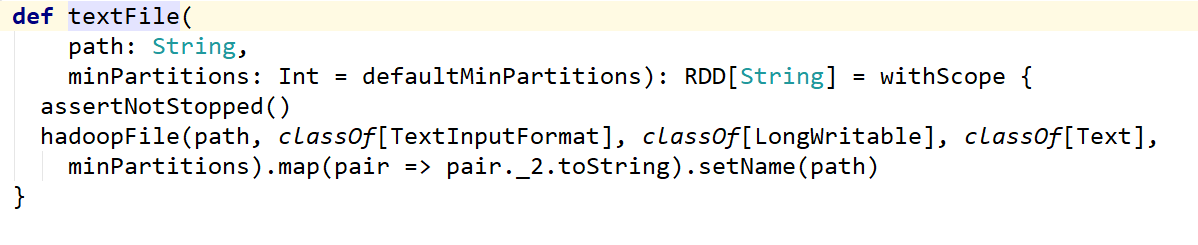
这个默认属性是有值的defaultMinPartitions




如果在textfile中传入了分区数,那么这个分区数可能相同也可能不同需要看底层计算!



扫描二维码关注公众号,回复:
6648616 查看本文章

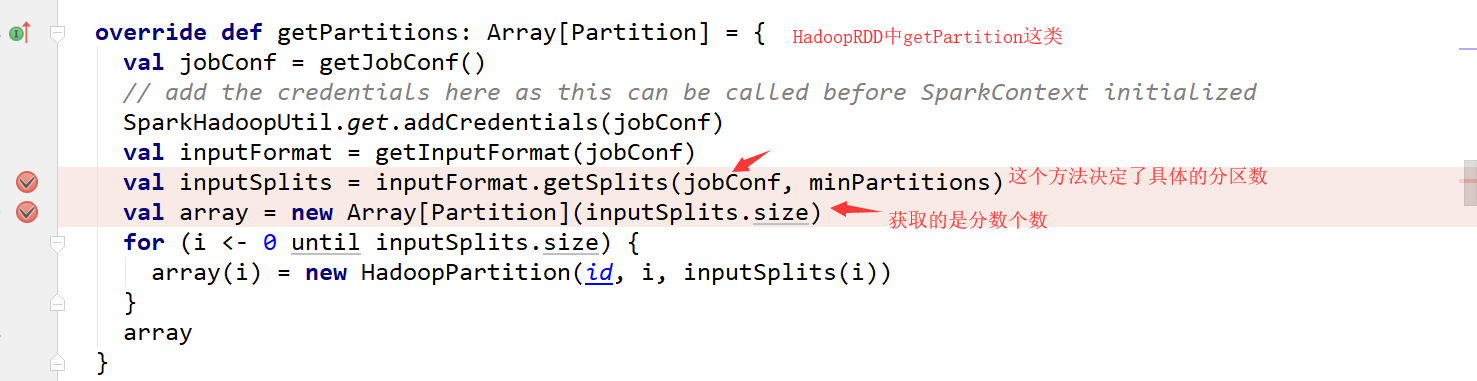
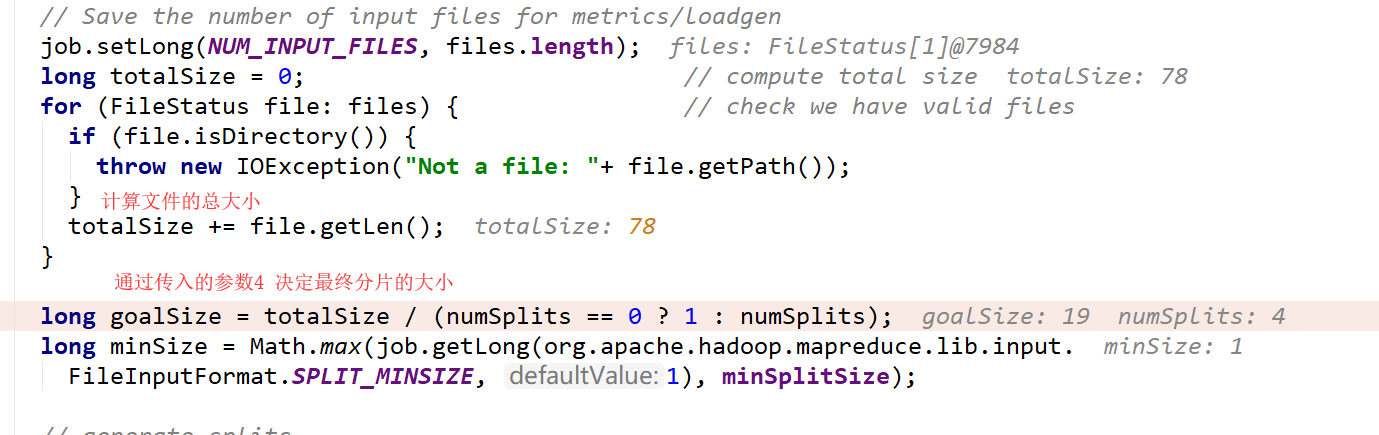
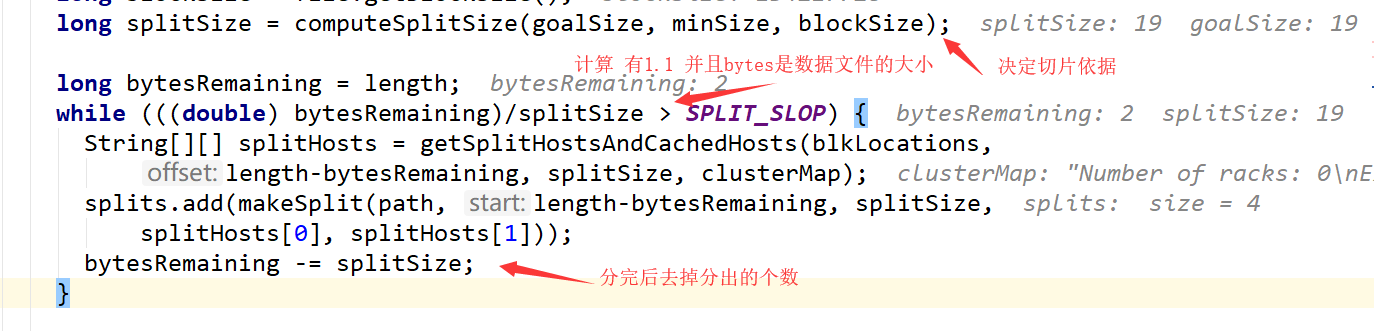
下面就是分片了,这个就是为什么textfile传入的参数和实际输出的分区可能不符合的原因
总结:
在textFile中没有指定分区的情况下都是默认大小2,除非指定小于2的值
若在textFile中指定了分区,name切分文件工作,实际上是计算出多少切分大小即多少切分一下,然后将文件按照这个大小切分成多份,最后partition数就是切分文件的个数。