
通过上一篇基本锁的介绍,基本上Mysql的基础加锁步奏,有了一个大概的了解。接下来我们进入最后一个锁的议题:间隙锁。间隙锁,与行锁、表锁这些要复杂的多,是用来解决幻读的一大手段。通过这种手段,我们没必要将事务隔离级别调整到序列化这个最严格的级别,而导致并发量大大下降。读取这篇文章之前,我想,我们要首先还是读一下我先前的两篇文章,否则一些理念还真的透彻不了:
一、基础测试表与数据
为了进行整个间隙锁的深入,我们要构建一些基础的数据,本章我们都会用构建的基础数据来进行,下面是数据表与索引的建立:
create table `t` (
`id` int(11) not null,
`c` int(11) DEFAULT null,
`d` int(11) DEFAULT null,
primary key (`id`),
key `c` (`c`)
) ENGINE=InnoDB;
然后我们插入一些基础的数据:
insert into t values
(0,0,0),
(5,5,5),
(10,10,10),
(15,15,15),
(20,20,20),
(25,25,25);
另外,我们本次讲解,都是使用默认的数据库隔离级别:可重复读
二、什么叫幻读
好,这个问题,就很关键了!我们来细说,幻读的具体出现的经典场景。其实很简单,先看下面的具体的复现sql语句:
| sessionA | sessionB | sessionC | |
|---|---|---|---|
| t1 | begin; | ||
| select * from t where d = 5 for update; | |||
| t2 | update t set d = 5 where id = 0; | ||
| t3 | select * from t where d = 5 for update; | ||
| t4 | insert into t values(1,1,5) | ||
| t5 | select * from t where d = 5 for update; | ||
| t6 | commit; |
针对这一系列的操作,我们来一个个分析:
- sessionA在t1时刻,可见读的结果是:(5,5,5),d没有索引,所以是全表扫描,对id为5的那一行,加行锁的写锁
- 由于sessionB再t2时刻,将id为0的数据改了下,所以t3时刻,sessionA的可见读的结果是:(0,0,5),(5,5,5)
- 由于sessionC再t4时刻,插入了条不存在的数据,所以t6时刻,sessionA的可见读结果是:(0,0,0)(1,1,5)(5,5,5)
- 如果,我们不添加for update进行可见读,普通的一致性读的情况下,由于mvcc的创建快照机制的影响,sessionA一直都会只看到(5,5,5)这一条数据
- update之后,可见读查出来的多一条数据,并不是幻读,只有插入之后的可见读,多读出来的数据,才叫幻读。就好比我们本来有两条原始数据,可是在事务的没结束之前的前后去读,分别读出来2条和3条,多出一条,就好像我在之后读出的3条数据,是幻影一样,突然出现了,所以叫幻读。
- 虽然我们平时几乎不会使用select for update进行查询,但是,要记住,update语句之前就是要进行一次for update的select查询的!
三、幻读会有什么影响
大概上,有两个影响,如下。
1、语义冲突
select * from t where d = 5 for update;
类似的,我们这条语句,其实语义上面是想锁住所有d等于5的行数据,让其不能update和insert。然而,我们接下来的sessionB和sessionC里面,如果没有相关的解决幻读的机制存在,那么都会有问题:
-- sessionB增加点操作
update t set d = 5 where id = 0;
update t set c = 5 where id = 0;
可见第二条sql已经操作了id等于0,d等于5这一行的数据,与之前的锁所有等于5的行语义上面冲突。
2、数据一致性问题
这个很关键,涉及到binglog问题。下面是我们具体操作的sql表格:
| sessionA | sessionB | sessionC | |
|---|---|---|---|
| t1 | begin; | ||
| select * from t where d = 5 for update; | |||
| update t set d = 100 where d = 5; | |||
| t2 | update t set d = 5 where id = 0; | ||
| update t set c = 5 where id = 0; | |||
| t3 | select * from t where d = 5 for update; | ||
| t4 | insert into t values(1,1,5); | ||
| update t set c = 5 where id = 1; | |||
| t5 | select * from t where d = 5 for update; | ||
| t6 | commit; |
由于,binglog是要等commit之后,才会记录的(后面文章会有细节的讲解),所以,上面这一系列的sql操作,到了binglog里面会变成下面的样子:
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/* 所有 d=5 的行,d 改成 100*/
可以看到,由于我们前面说,只对id等于5这一行,加了行锁,所以sessionB的操作是可以进行的,所以,最终会发现,我们sessionA里面的update操作,是最后执行的,如果拿着这个binglog同步从库的话,必然会导致,(0,5,100)、(1,5,100) 和 (5,5,100)这种数据出现,和主库完全不一致!(主库里面,只有id为5的数据,d才为100)。
那么我们将所有扫秒到的数据行都加了锁,会如何呢?那么,sessionB里面的第一条update语句将被阻塞,binglog里面的数据如下:
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=100 where d=5;/* 所有 d=5 的行,d 改成 100*/
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
这样的结果,id为0的这一行的数据,的确能保证数据的一直性,但是,会发现,刚刚插进去的id为1的这一样,在主库里面,d的值为5,但是在从库里面执行了binglog之后,会变成100,又会有不一致的情况出现了!
四、初入"间隙锁"
针对幻读问题,我们日常理论中经常"背诵"的,是:第三事务隔离级别会出现幻读情况,只有通过提高隔离级别,到最高级别的串行化,能解决幻读这样的问题。但是这样,每一个时刻只能有一个线程操作同一个表,并发性大大的降低,根本无法满足,高并发的需求,要知道,Mysql这东西,可是各大顶级互联网公司趋之若鹜的基础数据库,怎么能效率这么差呢?在这里,Mysql就引入了间隙锁的概念。下面我们来看看,间隙锁如何加锁。
1、间隙锁的产生
首先,如果我们使用下面语句进行查询:
select * from t where d = 5 for update;
这样,由于d是没有索引的,那么会走全表查询,默认走的是id的主键索引,按照id的主键值,会产生如下的区间:
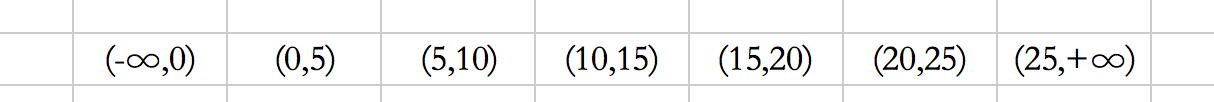
2、如何加间隙锁
例如上面的select语句中,d是没有索引的,所以通过id索引进行全表扫面,又因为是for update,那么,会将表中仅有的六条数据,都加上行锁,然后,针对上面的六个区间,也会加上间隙锁。行锁+间隙锁就是我们喜闻乐见的:next-key lock了!所以,整体上看也就是7个next-key lock:
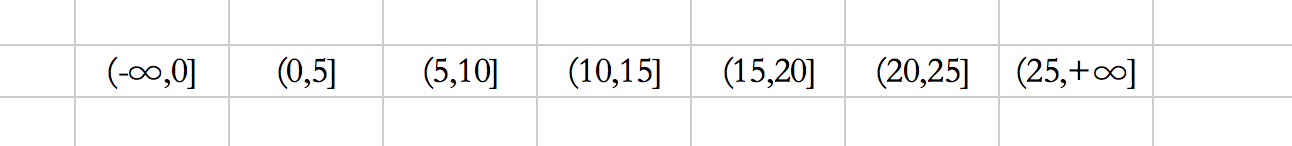
这个+∞是可以进行配置的,给每个索引分配一个不存在的值
3、间隙锁的特性
前面的文章,我们似乎聊过行锁之间的互斥形式:
| 读锁 | 写锁 | |
|---|---|---|
| 读锁 | 兼容 | 冲突 |
| 写锁 | 冲突 | 冲突 |
但是间隙锁不是。和间隙锁冲突的,是往这个间隙里面插入一条数据!这一点也是很好的保持并发性的一个挽回。下面看一个操作:
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from t where c = 7 lock in share model; | |
| begin; | |
| select * from t where c = 7 for update; |
虽然,两个事务,都是真对同一条数据,进行可见读的查询,但是并不会阻塞!因为c没有7的这个值,那结果就是,只会在数据库里面加上了(5,10)这个间隙锁,两个可见读并不会因为间隙锁和互斥冲突!
如果这样,加上间隙锁的特性,和行锁的特性,针对上面章节的sql操作:
| sessionA | sessionB | sessionC | |
|---|---|---|---|
| t1 | begin; | ||
| select * from t where d = 5 for update; | |||
| update t set d = 100 where d = 5; | |||
| t2 | update t set d = 5 where id = 0;(阻塞) | ||
| update t set c = 5 where id = 0; | |||
| t3 | select * from t where d = 5 for update; | ||
| t4 | insert into t values(1,1,5);(阻塞) | ||
| update t set c = 5 where id = 1; | |||
| t5 | select * from t where d = 5 for update; | ||
| t6 | commit; |
最终生成的binglog就会是:
update t set d=100 where d=5;/* d 改成 100*/
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/
update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
这样,就解决了数据一致性的问题了,主从库里面都能保持一致。
4、间隙锁带来的问题
虽然,间隙锁能比较好的解决上诉我们探讨的问题,但是同时也会带来些麻烦,要我们特别的注意。例如下面的操作,是一段业务上面的伪代码:
tx.beginTransaction();
var t = select * from t where id = 9 for update;
if(t){
update t set d = 45 where id = 9;
}else{
insert into t values(9,5,45);
}
tx.commit();
(假设id等于9这一行不存在)这段业务逻辑代码,普通情况下,我也经常看到,问题不太会出现,一旦并发量上去了,就会出问题,会造成死锁,下面我们看看造成死锁的sql执行序列:
| sessionA | sessionB | |
|---|---|---|
| t1 | begin; | |
| select * from t where id = 9 for update; | ||
| begin; | ||
| t2 | select * from t where id = 9 for update; | |
| insert into t values(9,5,45);(阻塞,等待sessionA的(5,10)的间隙锁释放) | ||
| t3 | insert into t values(9,5,45); (阻塞,等待sessionB的(5,10)的间隙锁释放,死锁!) |
当然,InnoDB的自动死锁检测,会发现这一点,主动将sessionA回滚,报错!
五、晋级"间隙锁"
有关于间隙锁,是最后一层级的细节所在,所以在判断是否加、怎么加、是否会阻塞方面,有非常多的考量。接下来我们来分别来说一下4个细节,分别对应4个例子,来讲讲,首先我们列出五条规则:
- 加锁的基本单位是next-key lock,就是针对扫描过的数据进行加间隙锁
- 索引上进行等值查询时,给唯一索引加锁的时候,next-key lock退化为行锁
- 索引上进行等值查询时,向右遍历,最后一个数值不满足等值的条件的时候,next-key lock退化为间隙锁,就是前后都是开区间
- 唯一索引的范围查询,会访问到第一个不满足的条件为止
1、第一条规则
加锁的基本单位是next-key lock,就是针对扫描过的数据进行加间隙锁
先来看看几个sql语句:
select * from t where id = 5 for update;
select * from t where id = 10 lock in share model;
两个分别对5和10这两行加了写锁与读锁,但是最开始,再索引树上面,首先加载id为5和10的这两行的时候,加锁步骤如下:
- 加(0,5)和(5,10)这两个间隙锁
- 加5的这一行的行锁(写锁),加10这一行的行锁(读锁)
- 所以目前为止,基础加锁的单位为next-key lock
2、第二条规则
索引上进行等值查询时,给唯一索引加锁的时候,next-key lock退化为行锁
还是第一条规则的两天语句,发现,id是主键索引(唯一索引),所以去掉了(0,5)(5,10)的这两个间隙锁,所以整个next-key lock变成了单纯的行锁
3、第三条规则
索引上进行等值查询时,向右遍历,最后一个数值不满足等值的条件的时候,next-key lock退化为间隙锁,就是前后都是开区间
先来看看下面的操作过程:
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; | ||
| update t set d = d+1 where id = 7; | ||
| insert into t values (8,8,8);(阻塞!) | ||
| update t set d = d+1 where id = 10;(成功) |
我们来分析:
- update之前会进行select for update操作,所以就是对id为7的这一行进行可见读
- 由于7这行记录不存在,但是7落在了(5,10)这个区间,而根据第一条原则,加锁基本单位是next-key lock,所以加锁会加上(5,10)的间隙锁,和10这一行的行锁(写锁),就是(5,10]
- 由于最后一条记录10和等值查询中的7并不相等,所以退化成了间隙锁,10这个的行锁解除。
所以根据这个规则,(5,10)这个区间是被锁住额,所以insert会被阻塞,另外10这一行的行锁解除,所以sessionC中的update会成功。
4、第四条规则
唯一索引的范围查询,会访问到第一个不满足的条件为止
看看下面的操作序列:
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; | ||
| select * from t where id > 10 and id <=15 for update; | ||
| update t set d = d+1 where id = 20;(阻塞) | ||
| insert into t values(16,16,16);(阻塞) |
分析:
- 由于10不是等值,15是等值,所以10这一条不会加next-key lock,15会,所以首先加上了(10,15]
- 虽然是唯一索引,但是是区间查询,并不会停止加锁的脚步,会继续向右
- 找到20这条记录,加上了next-key lock的(15,20]
- 由于不是等值查询,是范围查询,所以应用不了规则三,所以最终形成的锁是:(10,15],(15,20]
这么一看,20这一行被行锁锁住,而且15,20的区间还有间隙锁,所以sessionB和sessionC的操作才会阻塞。
5、其他方面的细节
每次加锁,其实都是锁索引树。众所周知,InnoDB的非主键索引的最终叶子节点,都只存储id主键值,然后还要遍历id主键索引,才能搜索出整条的数据,我们通常将这个过程称之为:回表。当然,如果select的是一个字段,这个字段刚好是id,那么Mysql就不用进行回表查询,因为直接在索引树上就能读取到值,MySQL会进行这种优化,通常我们称之为:索引下推。根据这个特性,我们来看看下面的操作序列:
| sessionA | sessionB | sessionC |
|---|---|---|
| begin; | ||
| select id from t where c = 5 lock in share model; | ||
| update t set d = d+1 where id = 5;(成功) | ||
| insert into t values(3,3,3);(阻塞) |
- 只在c这个非唯一索引上,加了行读锁,基础的加锁单位是(0,5],由于是非唯一索引的查询,并不能退化为行锁
- 由于非唯一索引,要继续往下,加上了(5,10]这一个的next-key lock,由于最右边的最后一个值,和等值查询并不相等,所以退化成间隙锁(5,10),所以sessionC会被阻塞
- 由于sessionA中的可见读是读锁,并且只查询id的值,所以启动了索引下推优化,只会加c这个索引上面的行锁。如果换成for update,那就会顺便将主键索引上面也加上锁。所以这里要分清两种行锁的粒度。
- 所以,最后,sessionB能成功的愿意是:主键索引上并没有加锁
六、结束
锁,在我的能力范围能,能说的就这么多,具体还是要用于实践。接下来,打算写很重要的两个日志文件的介绍:binglog和redolog
转载于:https://my.oschina.net/UBW/blog/3059914