1.1.变量替换
变量替换的六种形式

实例:非贪婪和贪婪的区别
从头部删除
[root@VM_0_9_centos shell_learn]# var_1="i love you,do you love me" [root@VM_0_9_centos shell_learn]# echo $var_1 i love you,do you love me [root@VM_0_9_centos shell_learn]# var1=${var_1#*ov} [root@VM_0_9_centos shell_learn]# echo $var1 e you,do you love me [root@VM_0_9_centos shell_learn]# var2=${var_1##*ov} [root@VM_0_9_centos shell_learn]# echo $var2 e me [root@VM_0_9_centos shell_learn]#
从尾部删除
[root@VM_0_9_centos shell_learn]# var_1="i love you,do you love me" [root@VM_0_9_centos shell_learn]# echo $var_1 i love you,do you love me [root@VM_0_9_centos shell_learn]# var3=${var_1%ov*} [root@VM_0_9_centos shell_learn]# echo $var3 i love you,do you l [root@VM_0_9_centos shell_learn]# var4=${var_1%%ov*} [root@VM_0_9_centos shell_learn]# echo $var4 i l [root@VM_0_9_centos shell_learn]#
字符串替换,把bin替换成大写的BIN,单斜线和双斜线的区别
[root@VM_0_9_centos shell_learn]# echo $PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin [root@VM_0_9_centos shell_learn]# [root@VM_0_9_centos shell_learn]# var5=${PATH/bin/BIN} [root@VM_0_9_centos shell_learn]# echo $var5 /usr/local/sBIN:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin [root@VM_0_9_centos shell_learn]# [root@VM_0_9_centos shell_learn]# var6=${PATH//bin//BIN} [root@VM_0_9_centos shell_learn]# echo $var6 /usr/local/s/BIN:/usr/local//BIN:/usr/s/BIN:/usr//BIN:/root//BIN [root@VM_0_9_centos shell_learn]#
1.2.字符串处理
计算字符串长度
方法一
${#string}
方法二
string有空格,则必须加双引号
expr length "$string"
实例
[root@VM_0_9_centos shell_learn]# var1="hello world" [root@VM_0_9_centos shell_learn]# len=${#var1} [root@VM_0_9_centos shell_learn]# echo $len 11 [root@VM_0_9_centos shell_learn]# len2=`expr length "$var1"` [root@VM_0_9_centos shell_learn]# echo $len2 11 [root@VM_0_9_centos shell_learn]#
获取子串在字符串中的索引位置
expr index $string $substring
实例
[root@VM_0_9_centos shell_learn]# var1="quickstart is a app" [root@VM_0_9_centos shell_learn]# index=`expr index "$var1" start` [root@VM_0_9_centos shell_learn]# echo $index 6 [root@VM_0_9_centos shell_learn]# index2=`expr index "$var1" uniq` [root@VM_0_9_centos shell_learn]# echo $index2 1 [root@VM_0_9_centos shell_learn]# index3=`expr index "$var1" cnk` [root@VM_0_9_centos shell_learn]# echo $index3 4 [root@VM_0_9_centos shell_learn]#
会把子串分割成一个一个字符,index是最先找到的那个字符的位置。
计算子串长度
expr match $string substr
实例
[root@VM_0_9_centos shell_learn]# var1="quickstart is a app" [root@VM_0_9_centos shell_learn]# len=`expr match "$var1" quic` [root@VM_0_9_centos shell_learn]# echo $len 4 [root@VM_0_9_centos shell_learn]# len=`expr match "$var1" app` [root@VM_0_9_centos shell_learn]# echo $len 0 [root@VM_0_9_centos shell_learn]# len=`expr match "$var1" quic.*` [root@VM_0_9_centos shell_learn]# echo $len 19 [root@VM_0_9_centos shell_learn]#
必须从开头匹配才可以
抽取子串
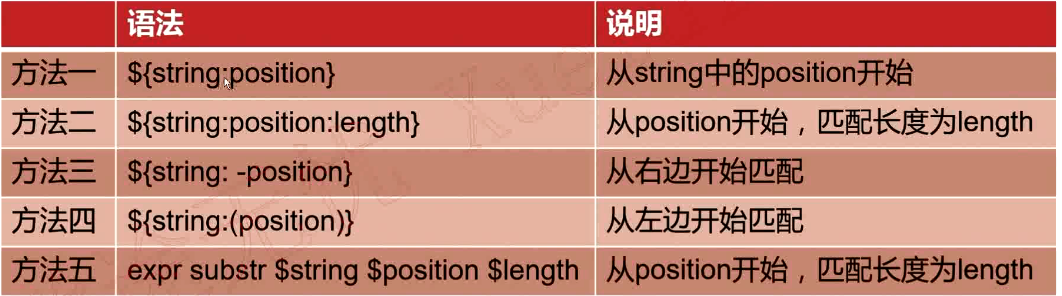
实例
[root@VM_0_9_centos shell_learn]# var1="kafka hadoop yarn mapreduce" [root@VM_0_9_centos shell_learn]# sub1=${var1:10} [root@VM_0_9_centos shell_learn]# echo $sub1 op yarn mapreduce [root@VM_0_9_centos shell_learn]# sub2=${var1:10:5} [root@VM_0_9_centos shell_learn]# echo $sub2 op ya [root@VM_0_9_centos shell_learn]# sub3=${var1: -5} [root@VM_0_9_centos shell_learn]# echo $sub3 educe [root@VM_0_9_centos shell_learn]# sub4=${var1:(-6)} [root@VM_0_9_centos shell_learn]# echo $sub4 reduce [root@VM_0_9_centos shell_learn]# sub5=${var1: -5:3} [root@VM_0_9_centos shell_learn]# echo $sub5 edu [root@VM_0_9_centos shell_learn]# sub6=`expr substr "$var1" 10 5` [root@VM_0_9_centos shell_learn]# echo $sub6 oop y [root@VM_0_9_centos shell_learn]#
注意:使用expr索引是从1开始计算,使用${string:position},索引从0开始计算。
1.3.字符串处理完整脚本

思路分析
1.将不同的功能模块划分,并编写函数 function print_tips function len_of_string function del_hadoop function rep_hadoop_mapreduce_first function rep_hadoop_maapreduce_all 2.实现第一步所定义的功能函数 3.程序主流程的设计
vim example.sh
#!/bin/bash string="Bigdata process framework is Hadoop,Hadoop is an open source project" function print_tips { echo "******************************" echo "(1)打印string长度" echo "(2)删除字符串中所有的Hadoop" echo "(3)替换第一个Hadoop为Mapreduce" echo "(4)替换全部Hadoop为Mapreduce" echo "*******************************" } function len_of_string { echo "${#string}" } function del_hadoop { echo "${string//Hadoop/}" } function rep_hadoop_mapreduce_first { echo "${string/Hadoop/Mapreduce}" } function rep_hadoop_mapreduce_all { echo "${string//Hadoop/Mapreduce}" } while true do echo "[string=$string]" echo print_tips read -p "Pls input your choice(1|2|3|4|q|Q): " choice case $choice in 1) len_of_string ;; 2) del_hadoop ;; 3) rep_hadoop_mapreduce_first ;; 4) rep_hadoop_mapreduce_all ;; q|Q) exit ;; *) echo "Error,input only in {1|2|3|4|q|Q|}" ;; esac done
sh example.sh
