一、集合:

1. 集合框架:
1)Collection
(1)List:有序的,有索引,元素可重复。
(add(index, element)、add(index, Collection)、remove(index)、set(index,element)、get(index)、subList(from, to)、listIterator())
①ArrayList:底层是数组结构,查询快,增删慢,不同步。
②LinkedList:底层是链表结构,增删快,查询慢,不同步。
addFist();addLast();getFirst();getLast()
removeFirst();
removeLast() 获取并删除元素,无元素将抛异常:NoSuchElementException
替代的方法(JDK1.6):
offerFirst();offerLast();
peekFirst();peekLast();无元素返回null
pollFirst();pollLast();删除并返回此元素,无元素返回null
③Vector:底层是数组结构,线程同步,被ArrayList取代了
注:Vector对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashCode和equals方法
ArrayList判断是否存在和删除操作依赖的是equals方法
(2)Set:无序的,无索引,元素不可重复
①HashSet:底层是哈希表,线程不同步,无序、高效
保证元素唯一性:通过元素的hashCode和equals方法。若hashCode值相同,则会判断equals的结果是否为true;hashCode不同,不会调用equals方法
LinkedHashSet:有序,是HashSet的子类
②TreeSet:底层是二叉树,可对元素进行排序,默认是自然顺序,不同步
保证唯一性:根据Comparable接口的compareTo方法的返回值
===》TreeSet两种排序方式:两种方式都存在时,以比较器为主
第一种:自然排序(默认排序):
添加的对象需要实现Comparable接口,覆盖compareTo方法
第二种:比较器
添加的元素自身不具备比较性或不是想要的比较方式。将比较器作为参数传递进去(Collection.sort(集合,比较器))。
定义一个类,实现Comparator接口,覆盖compare方法。当主要条件相同时,比较次要条件。
2)Map集合:
(1)HashTable:底层数据结构是哈希表,不可存入null键和null值。同步的
Properties继承自HashTable,可保存在流中或从流中加载,是集合和IO流的结合产物
(2)HashMap:底层数据结构是哈希表;允许使用null键和null值,不同步,效率高
(3) TreeMap:
底层数据结构是二叉树,不同步,可排序
与Set很像,Set底层就是使用了Map集合
方法:
V put(K key, V value) ; void putAll(Map m)
void clear(); V remove(Object key)
boolean containsKey(Object key); containsValue(Object key); isEmpty()
V get(Object key); int size(); Collection<V> values()
Set<K> keySet(); Set<Map.Entry<K,V>> entrySet()
Map集合两种取出方式:
第一种:Set<K> keySet()
取出Map集合中的所有键放于Set集合中,然后再通过键取出对应的值
Set<String> keySet = map.keySet();
Iterator<String> it = keySet.iterator();
while(it.hasNext()){
String key = it.next();
String value = map.get(key);
//…..
}
第二种:Set<Map.Entry<K,V>> entrySet()
取出Map集合中键值对的映射放于Set集合中,然后通过Map集合中的内部接口,然后通过其中的方法取出
Set<Map.Entry<String,String>> entrySet = map.entrySet();
Iterator<Map.Entry<String,String>> it = entrySet.iterator();
While(it.hasNext()){
Map.Entry<String,String> entry = it.next();
String key = entry.getKey();
String value = entry.getValue();
//……
}
Collection和Map的区别:
Collection:单列集合,一次存一个元素
Map:双列集合,一次存一对数据,两个元素(对象)存在着映射关系
集合工具类:
Collections:操作集合(一般是list集合)的工具类。方法全为静态的
sort(List list);对list集合进行排序; sort(List list, Comparator c) 按指定比较器排序
fill(List list, T obj);将集合元素替换为指定对象;
swap(List list, int I, int j)交换集合指定位置的元素
shuffle(List list); 随机对集合元素排序
reverseOrder() :返回比较器,强行逆转实现Comparable接口的对象自然顺序
reverseOrder(Comparator c):返回比较器,强行逆转指定比较器的顺序
Collection和Collections的区别:
Collections:java.util下的工具类,实现对集合的查找、排序、替换、线程安全化等操作。
Collection:是java.util下的接口,是各种单列集合的父接口,实现此接口的有List和Set集合,存储对象并对其进行操作。
3)Arrays:
用于操作数组对象的工具类,全为静态方法
asList():将数组转为list集合
好处:可通过list集合的方法操作数组中的元素:
isEmpty()、contains()、indexOf()、set()
弊端:数组长度固定,不可使用集合的增删操作。
如果数组中存储的是基本数据类型,asList会将数组整体作为一个元素存入集合
集合转为数组:Collection.toArray();
好处:限定了对集合中的元素进行增删操作,只需获取元素
二、IO流
1、结构:
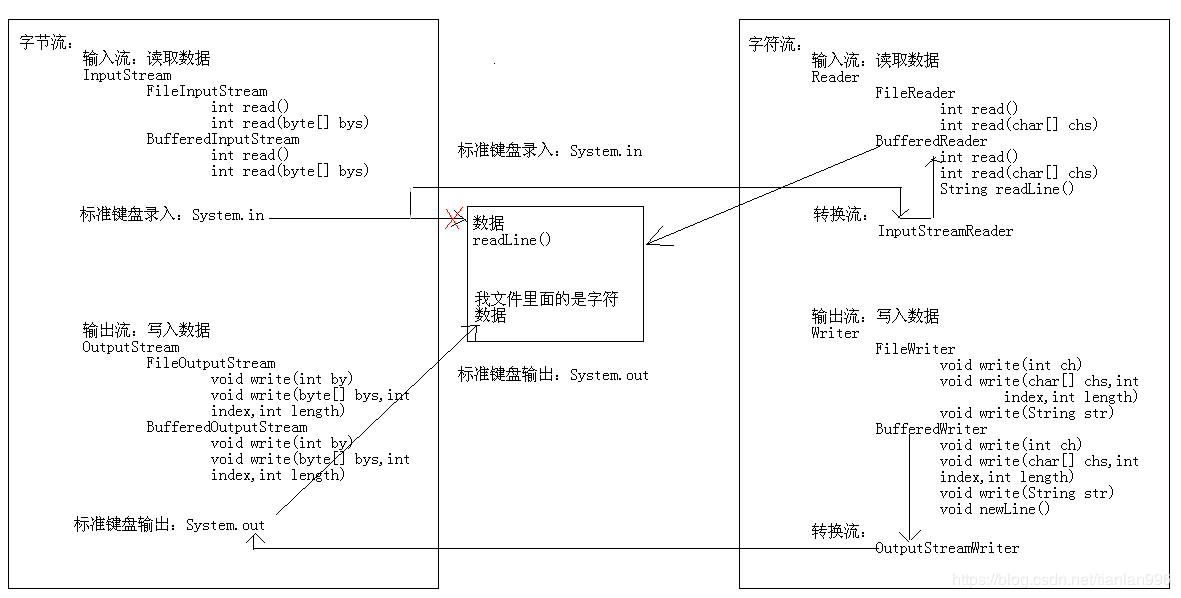
字节流:InputStream,OutputStream
字符流:Reader,Writer
Reader:读取字符流的抽象类
BufferedReader:将字符存入缓冲区,再读取
LineNumberReader:带行号的字符缓冲输入流
InputStreamReader:转换流,字节流和字符流的桥梁,多在编码的地方使用
FileReader:读取字符文件的便捷类。
Writer:写入字符流的抽象类
BufferedWriter:将字符存入缓冲区,再写入
OutputStreamWriter:转换流,字节流和字符流的桥梁,多在编码的地方使用
FileWriter:写入字符文件的便捷类。
InputStream:字节输入流的所有类的超类
ByteArrayInputStream:含缓冲数组,读取内存中字节数组的数据,未涉及流
FileInputStream:从文件中获取输入字节。媒体文件
BufferedInputStream:带有缓冲区的字节输入流
DataInputStream:数据输入流,读取基本数据类型的数据
ObjectInputStream:用于读取对象的输入流
PipedInputStream:管道流,线程间通信,与PipedOutputStream配合使用
SequenceInputStream:合并流,将多个输入流逻辑串联。
OutputStream:此抽象类是表示输出字节流的所有类的超类
ByteArrayOutputStream:含缓冲数组,将数据写入内存中的字节数组,未涉及流
FileOutStream:文件输出流,将数据写入文件
BufferedOutputStream:带有缓冲区的字节输出流
PrintStream:打印流,作为输出打印
DataOutputStream:数据输出流,写入基本数据类型的数据
ObjectOutputStream:用于写入对象的输出流
PipedOutputStream:管道流,线程间通信,与PipedInputStream配合使用
2、流操作规律:
明确源和目的:
数据源:读取,InputStream和Reader
目的:写入:OutputStream和Writer
数据是否是纯文本:
是:字符流,Reader,Writer
否:字节流,InputStream,OutStream
明确数据设备:
源设备:内存、硬盘、键盘
目的设备:内存、硬盘、控制台
是否提高效率:用BufferedXXX
3、转换流:将字节转换为字符,可通过相应的编码表获得
转换流都涉及到字节流和编码表
三、多线程
进程和线程:
1)进程,是并发执行的程序在执行过程中分配和管理资源的基本单位;线程,是进程的一部分,一个没有线程的进程可以被看作是单线程的。线程有时又被称为轻量级进程,是 CPU 调度的一个基本单位。
线程是划分得比进程更小的执行单位,在同一个进程中的线程共享进程的内存单元,共享进程拥有的资源。
1、创建线程的方式:
创建方式一:继承Thread
1:定义一个类继承Thread
2:覆盖Thread中的run方法(将线程运行的代码放入run方法中)。
3:直接创建Thread的子类对象
4:调用start方法(内部调用了线程的任务(run方法));作用:启动线程,调用run方法
方式二:实现Runnable
1:定义类实现Runnable接口
2:覆盖Runnable接口中的run方法,将线程的任务代码封装到run中
3:通过Thread类创建线程对象
4、并将Runnable接口的子类对象作为Thread类的构造函数参数进行传递
作为参数传递的原因是让线程对象明确要运行的run方法所属的对象。
区别:
继承方式:线程代码放在Thread子类的run方法中
实现方式:线程存放在接口的子类run方法中;避免了单继承的局限性,建议使用。
2、线程状态:
Java中的线程的生命周期大体可分为5种状态。
①NEW(新建状态):这种情况指的是,通过New关键字创建了Thread类(或其子类)的对象
②RUNNABLE(可运行状态):(这种情况指的是Thread类的对象调用了start()方法,这时的线程就等待时间片轮转到自己这,以便获得CPU;第二种情况是线程在处于RUNNABLE状态时并没有运行完自己的run方法,时间片用完之后回到RUNNABLE状态;还有种情况就是处于BLOCKED状态的线程结束了当前的BLOCKED状态之后重新回到RUNNABLE状态。)这种情况是指线程已具备运行条件,但是还没有得到CPU调度的状态。
③RUNNING(运行状态):这时的线程指的是获得CPU的RUNNABLE线程,RUNNING状态是所有线程都希望获得的状态。
④BLOCKED:这种状态指的是处于RUNNING状态的线程,出于某种原因,比如调用了sleep方法、等待用户输入等而让出当前的CPU给其他的线程。
⑤DEAD(消亡状态):处于RUNNING状态的线程,在执行完run方法之后,就变成了DEAD状态了。
3、多线程安全问题:
多个线程共享同一数据,当某一线程执行多条语句时,其他线程也执行进来,导致数据在某一语句上被多次修改,执行到下一语句时,导致错误数据的产生。
因素:多个线程操作共享数据;多条语句操作同一数据
解决:
原理:某一时间只让某一线程执行完操作共享数据的所有语句。
办法:使用锁机制:synchronized或lock对象
4、线程的同步:
当两个或两个以上的线程需要共享资源,他们需要某种方法来确定资源在某一刻仅被一个线程占用,达到此目的的过程叫做同步(synchronization)。
同步代码块:synchronized(对象){},将需要同步的代码放在大括号中,括号中的对象即为锁。
同步函数:放于函数上,修饰符之后,返回类型之前。
5、wait和sleep的区别:(执行权和锁区分)
wait:可指定等待的时间,不指定须由notify或notifyAll唤醒。
线程会释放执行权,且释放锁。
sleep:必须制定睡眠的时间,时间到了自动处于阻塞状态。
即使睡眠了,仍持有锁,不会释放执行权。
---------------------
作者:tianlan996
来源:CSDN
原文:https://blog.csdn.net/tianlan996/article/details/88169225
版权声明:本文为博主原创文章,转载请附上博文链接!