二、目标分类卷积神经网络结构介绍
随着卷积神经网络的提出,Alex等人首次将其应用到ImageNet比赛中,并斩获2012年ImageNet的冠军。然后越来越多的优秀分类网络结构被提出来,比如vgg16,GoogLeNet,和ResNet等,下面我们来一一介绍其结构及特点。
2.1 AlexNet网络
AlexNet原文在这里。AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。在ImageNet大规模视觉挑战赛(ILSVRC)中,AlexNet凭借其独特的卷积神经网络结构以37.5%的top-1错误率和17%的top-5错误率斩获当时比赛的冠军,也是在那年之后,更多的更深的神经网络被提出,开启了深度学习的新时代。AlexNet中含有6千万个参数和大约65万个神经节点,总共有5个卷积层和3个全连接层,最后一层接了一个softmax分类用于输出。除了网络结构的创新外,为了减少网络过拟合的问题,AlexNet还使用了多种策略如dropout和数据增强等。
2.1.1 AlexNet网络结构
ImageNet数据集包括1500万带有分类标签的图片,总共大约有22000个类别。ILSVRC使用ImgetNet中1000个类别(每个类别大约1000张图片)作为数据集,AlexNet使用120万张图片作为训练集,5万张验证集图片以及12万张测试集图片。Alex的网络结构如下图,AlexNet是一个8层的深度神经网络,每个卷积神经网络在完成卷积操作后使用relu函数激活,然后在第一和第二的卷积层激活后还跟了一个LRN(局部响应归一化层),然后再在第一、二、五层卷积层后面又增加了最大池化层。

| Type | Filters | Size | Output |
|---|---|---|---|
| Input | - | - | 227*227*3 |
| Convolutional | 96 | 11*11(p=0, s=4) | 55*55*96 |
| LRN | - | - | - |
| Maxpool | - | 3*3(s=2) | 27*27*96 |
| Convolutional | 256 | 5*5(p=2, s=1) | 27*27*256 |
| LRN | - | - | - |
| Maxpool | - | 3*3(s=2) | 13*13*256 |
| Convolutional | 384 | 3*3(p=2, s=1) | 13*13*384 |
| Convolutional | 384 | 3*3(p=2, s=1) | 13*13*384 |
| Convolutional | 256 | 3*3(p=1, s=1) | 13*13*256 |
| Maxpool | - | 3*3(s=2) | 6*6*256 |
| Connected | - | 4096 | 4096 |
| Connected | - | 4096 | 4096 |
| Connected | - | 1000 | 1000 |
在AlexNet中,作者使用了一些tricks来改善网络的性能,当然在目前看来,很多tricks都已经被用烂了,有些tricks也因为其局限性而被淘汰。下面具体介绍一下这些tricks,各位也可以应用到自己的训练网络中去:
- 采用ReLU激活函数
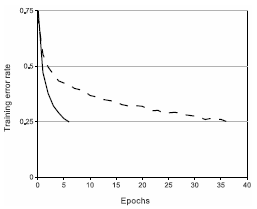
在我们之前的文章中,介绍了激活函数的作用,常用的sigmoid和tanh激活函数由于随着网络层数的增加会导致梯度消失和梯度更新缓慢等问题,AlexNet中引入了ReLU激活函数 。使用ReLU激活函数的卷积神经网络要比tanh激活函数的训练速度快好几倍,如下图所示,虚线表示使用tanh函数的卷积网络,实线表示使用ReLU激活函数的卷积网络。显然,ReLU激活函数比tanh激活函数更快收敛。
- 使用多GPU进行训练
Alex等人利用了两块GPU来进行卷积计算,利用GPU强大的并行计算能力,大大地提高了网络训练的速度(可以理解CPU计算是用一辆法拉利来拉货,GPU是用十辆大卡车拉货,动力或许不及法拉利,但一次可以拉更多的货)。由于论文中使用的是GTX580进行训练,而单个GTX580只有3GB显存,所以作者将AlexNet分布在两个GPU上,每个GPU的显存中只存储一半的神经元参数。因为GPU之间通信方便,可以互相访问显存,而不需要通过主机内存,所以同时使用多块GPU也是非常高效的。目前很多实验室的工作站都是用多路Titan来进行深度学习的训练。
- 使用局部响应归一化层(Local Response Normalization)
在使用ReLU作为激活函数时,其输出没有饱和区,因此ReLU激活函数不需要对输入进行归一化变换来防止梯度饱和。但是Alex等人发现,局部响应归一化仍然有助于提高网络的检测精度,所以其在第一层和第二层卷积层后面增添了两个LRN层以增强泛化能力。局部响应归一化的参数如下所示:
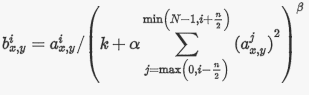
其中, 表示神经元激活,通过在 位置应用核 ,然后应用ReLU非线性来计算,响应归一化激活 , 是卷积核的个数,也就是生成的FeatureMap的个数; 是超参数,论文中使用的值是 。输出 和输入 的上标表示的是当前值所在的通道,也即是叠加的方向是沿着通道进行。将要归一化的值 所在附近通道相同位置的值的平方累加起来。但是,下一篇VGGNet论文中实验指出LRN并不能降低错误率,反倒加大了计算量,LRN的应用场合还需要考虑。目前,很多神经网络中采用了Batch Normalization策略来取代了LRN。
- 层叠池化(Overlapping Pooling)
以前的pooling都是核多大,步长就多大,这样池化层的池化核的作用区域不会重叠。而在AlexNet中采用了池化核尺寸和步长不相同的策略,即池化过程中,池化核每次移动的步长小于池化的窗口的长度。比如,AlexNet池化的大小为3*3的正方形,每次移动步长为2,每次移动,这样就会出现重叠,在一定程度上提高了模型的泛化能力,减少过拟合现象。
2.1.2 减少过拟合方法
AlexNet含有超过6千万个参数,尽管ImageNet的数据量很大,但还是不足以满足如此多参数的学习而不产生过拟合现象。为了减低过拟合的影响,Alex设计如下两种方法。
- 数据增强
减轻过拟合最简单和最有用的方法就是人为地增加数据集的数据量,Alex通过对原始图片做一些计算量不大的变换来扩增数据集。
采用的一种方法是在训练时从尺寸为256*256的原始图片中随机裁剪出大小为224*224的图像来作为网络的输入,并对输入图像再做一次水平翻转又能将数据集扩增一倍,这样数据集的容量就变成了
倍。在测试时,作者只对输入测试图片裁剪出五张224*224大小的图像(四角+中间),再对其进行翻转,这样扩增了10倍,最后对这10张patch在softmax层输出相加去平均值输出相加去平均值作为最后的输出结果。另一种方法是改变训练图片的RGB通道,对原训练集做PCA(主成份分析),对每张训练图片加上主成份的倍数,即大小成正比的对应特征值乘以一个随机变量,随机变量通过均值为0,标准差为0.1的高斯分布得到。即:
分别是RGB像素值 协方差矩阵的第i个特征向量和特征值, 是前面提到的随机变量。对于某个训练图像的所有像素,每个 只获取一次,直到图像进行下一次训练时才重新获取。这个方案近似抓住了自然图像的一个重要特性,即降低了光照和颜色和灯光对结果的影响。这个方案减少了top-1错误率1%以上。
- Dropout
Dropout方法能够有效地减少过拟合现象,在上一篇博文中已经有过介绍了。它会以0.5的概率对每个隐层神经元的输出设为0。那些“失活的”的神经元不再进行前向传播并且不参与反向传播。因此每次输入时,神经网络会采样一个不同的架构,但所有架构共享权重。dropout技术减少了神经元之间的耦合,在每一次传播的过程中,hidden层的参与传播的神经元不同,整个模型的网络就不相同了,这样就会强迫网络学习更robust的特征,从而提高了模型的鲁棒性。
2.1.3 训练细节
作者在训练时使用了小幅度的权值衰减,这样利于模型的训练学习。此外,对于第二、四、五卷积层以及所有的全连接层,初始化偏置值为1,这样有利于给ReLU提供一个正输入,加快训练速度,剩下的层偏置初始化为0。学习率初始化为0.01,随着模型在验证集错误率不提升时,再将学习率降低10倍,整个训练过程降低了3次。