一、 Fork/Join框架的介绍
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。我们再通过Fork和Join这两个单词来理解下Fork/Join框架,Fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计算1+2+。。+10000,可以分割成10个子任务,每个子任务分别对1000个数进行求和,最终汇总这10个子任务的结果。
Fork/Join的运行流程图如下:
1、实现步骤:
-
第一步分割任务。**首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小。
-
第二步执行任务并合并结果。**分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
Fork/Join使用两个类来完成以上两件事情:
ForkJoinTask:我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:
RecursiveAction:用于没有返回结果的任务。
RecursiveTask :用于有返回结果的任务。
ForkJoinPool :ForkJoinTask需要通过ForkJoinPool来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程队列的尾部获取一个务。
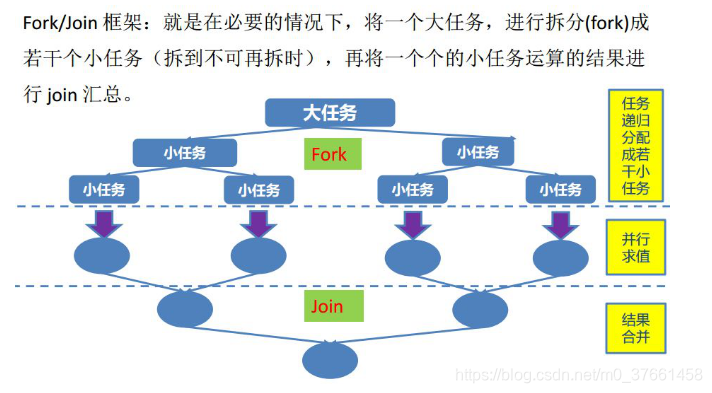
2、工作窃取算法
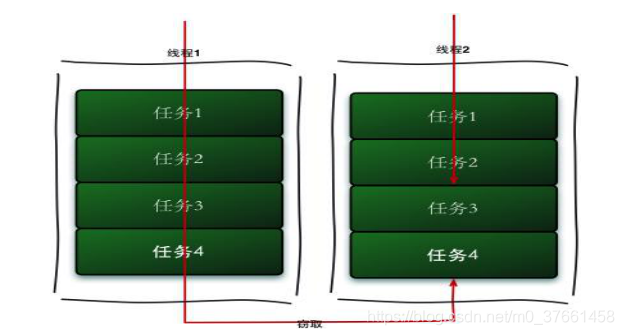
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
为什么要使用工作窃取算法呢?
- 假如我们要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。
但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
3、分而治之
同时fork-join在处理某一类问题时非常的有用,哪一类问题?分而治之的问题。十大计算机经典算法:快速排序、堆排序、归并排序、二分查找、线性查找、深度优先、广度优先、Dijkstra、动态规划、朴素贝叶斯分类,有几个属于分而治之?其中3个,快速排序、归并排序、二分查找,还有大数据中M/R都是采用分而治之思想。
分治法的设计思想是:将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破、分而治之。
分治策略是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同(子问题相互之间有联系就会变为动态规范算法),递归地解这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计策略叫做分治法。
3.1 归并排序
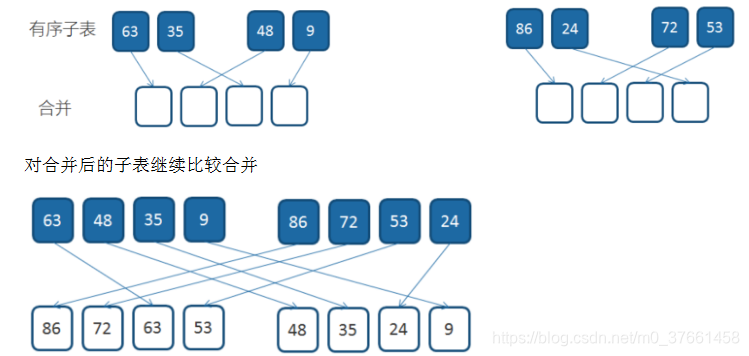
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
若将两个有序表合并成一个有序表,称为2-路归并,与之对应的还有多路归并。对于给定的一组数据,利用递归与分治技术将数据序列划分成为越来越小的半子表,在对半子表排序后,再用递归方法将排好序的半子表合并成为越来越大的有序序列。为了提升性能,有时我们在半子表的个数小于某个数(比如15)的情况下,对半子表的排序采用其他排序算法,比如插入排序。
归并排序(降序)示例

对有序的子表进行排序和比较合并
4、Fork/Join使用的标准范式
我们要使用Fork-Join框架,必须首先创建一个Fork-Join任务。它提供在任务中执行fork和join的操作机制,通常我们不直接继承ForkjoinTask类,只需要直接继承其子类。
- RecursiveAction,用于没有返回结果的任务
- RecursiveTask,用于有返回值的任务
Task要通过ForkJoinPool来执行,使用submit 或 invoke 提交,两者的区别是:invoke是同步执行,调用之后需要等待任务完成,才能执行后面的代码;submit是异步执行。
public static void main(String[] args) { // 创建ForkJoinPool来执行任务 ForkJoinPool pool = new ForkJoinPool(); int[] src = MakeArray.makeArray(); // 创建fork-join任务 SumTask innerTask = new SumTask(src, 0, src.length-1); long start = System.currentTimeMillis(); // invoke是同步执行,调用之后需要等待任务完成,才能执行后面的代码 pool.invoke(innerTask); //使用join方法会等待子任务执行完并得到其结果 result = innerTask.join(); int result = innerTask.join(); System.out.println("The count result is: "+result+" spend time:"+(System.currentTimeMillis()-start)+"ms"); }
join()和get方法当任务完成的时候返回计算结果。
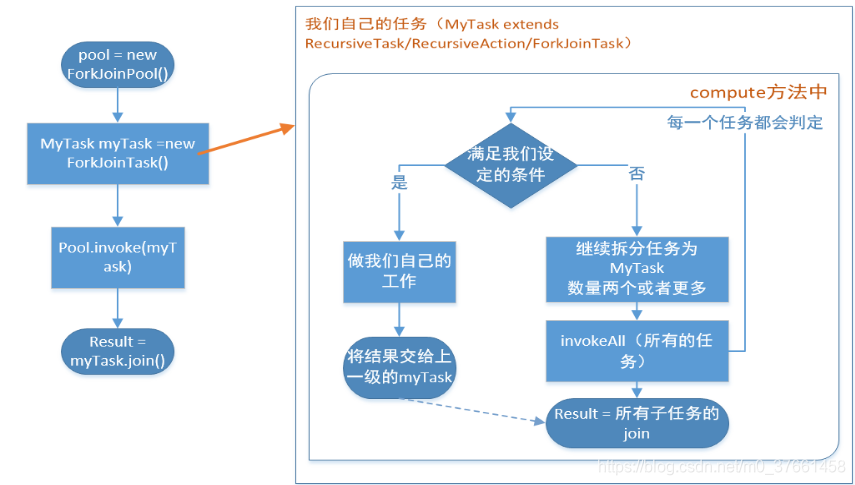
在我们自己实现的compute方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用invokeAll方法时,又会进入compute方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
@Override
protected Integer compute() {
// 首先判断任务是否足够小,如果足够小就直接执行任务
if(toIndex-fromIndex < THRESHOLD) {
// 将任务结果交给上一级
int count = 0;
for(int i = fromIndex; i<= toIndex; i++) {
SleepTools.ms(1);
count = count + src[i];
}
return count;
}else { //
int mid = (fromIndex + toIndex) / 2;
SumTask leftTask = new SumTask(src, fromIndex, mid);
SumTask rightTask = new SumTask(src, mid+1, toIndex);
// 任务拆分完城后调用invokeAll()方法将子任务放进去,继续计算判断是否需要再次拆分,直到拆分达到阈值
invokeAll(leftTask,rightTask);
// 返回计算结果
return leftTask.join() + rightTask.join();
}
}
5、Fork/Join框架的异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常。使用如下代码:
if(task.isCompletedAbnormally())
{ System.out.println(task.getException());}
getException方法返回Throwable对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
6、Fork/Join框架的实现原理
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务。ForkJoinTask的fork方法实现原理:当我们调用ForkJoinTask的fork方法时,程序会调用ForkJoinWorkerThread的pushTask方法异步的执行这个任务,然后立即返回结果。
JDK1.8代码如下:
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
push方法把当前任务放入到任务队列里面,然后调用ForkJoinPool 的signalWork方法唤醒或者创建一个线程来执行任务
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a; ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
if ((p = pool) != null)
p.signalWork(p.workQueues, this);
}
else if (n >= m)
growArray();
}
}
JDK1.7代码如下:

ForkJoinTask的join方法实现原理。Join方法的主要作用是阻塞当前线程并等待获取结果。让我们一起看看ForkJoinTask的join方法的实现,代码如下:
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
private void reportException(int s) {
if (s == CANCELLED)
throw new CancellationException();
if (s == EXCEPTIONAL)
rethrow(getThrowableException());
}
JDK1.7实现:
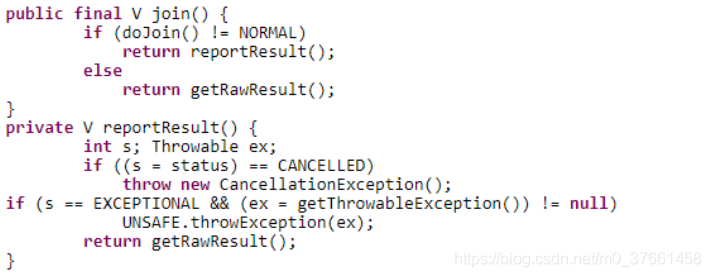
首先,它调用了doJoin()方法,通过doJoin()方法得到当前任务的状态来判断返回什么结果,任务状态有四种:
已完成(NORMAL),被取消(CANCELLED),信号(SIGNAL)和出现异常(EXCEPTIONAL)。
- 如果任务状态是已完成,则直接返回任务结果。
- 如果任务状态是被取消,则直接抛出CancellationException。
- 如果任务状态是抛出异常,则直接抛出对应的异常。
让我们再来分析下doJoin()方法的实现代码JDK1.8:
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}
JDK1.7实现如下:

在doJoin()方法里,首先通过查看任务的状态,看任务是否已经执行完了,如果执行完了,则直接返回任务状态,如果没有执行完,则从任务数组里取出任务并执行。如果任务顺利执行完成了,则设置任务状态为NORMAL,如果出现异常,则纪录异常,并将任务状态设置为EXCEPTIONAL。
二、闭锁CountDownLatch
闭锁CountDownLatch这个类能够使一个线程等待其他线程完成各自的工作后再执行。例如应用程序的主线程希望在负责启动框架服务的线程已经启动所有的框架服务之后再执行。
CountDownLatch是通过一个计数器来实现的,计数器的初始值为初始任务的数量。每当完成了一个任务后,计数器的值就会减1(CountDownLatch.countDown()方法)。当计数器值到达0时,它表示所有的已经完成了任务,然后在闭锁上等待CountDownLatch.await()方法的线程就可以恢复执行任务。
1、应用场景
实现最大的并行性:有时我们想同时启动多个线程,实现最大程度的并行性。例如,我们想测试一个单例类。如果我们创建一个初始计数为1的CountDownLatch,并让所有线程都在这个锁上等待,那么我们可以很轻松地完成测试。我们只需调用
一次countDown()方法就可以让所有的等待线程同时恢复执行。
开始执行前等待n个线程完成各自任务:例如应用程序启动类要确保在处理用户请求前,所有N个外部系统已经启动和运行了,例如处理excel中多个表单。
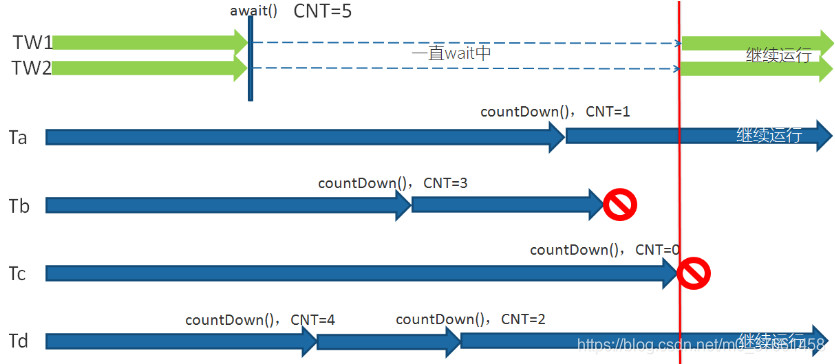
参见代码包cn.enjoyedu.ch2.tools下
2、CyclicBarrier
CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
CyclicBarrier默认的构造方法是CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await方法告诉CyclicBarrier我已经到达了屏障,然后当前线程被阻塞。
CyclicBarrier还提供一个更高级的构造函数CyclicBarrier(int parties,Runnable barrierAction),用于在线程到达屏障时,优先执行barrierAction,方便处理更复杂的业务场景。
CyclicBarrier可以用于多线程计算数据,最后合并计算结果的场景。
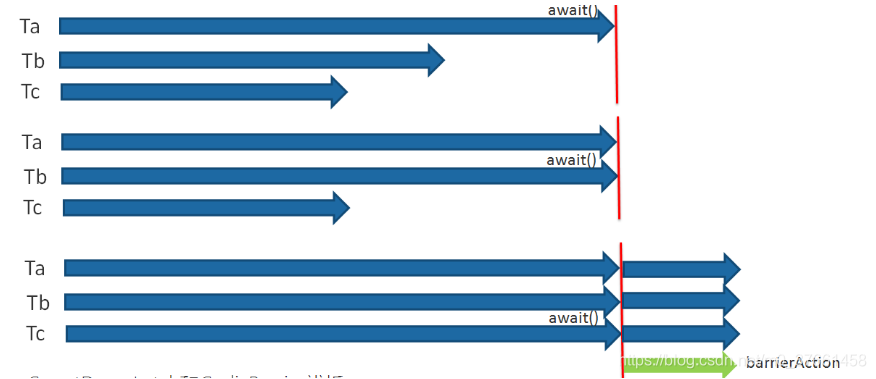
CountDownLatch和CyclicBarrier辨析:
- CountDownLatch的计数器只能使用一次,而CyclicBarrier的计数器可以反复使用。
- CountDownLatch.await一般阻塞工作线程,所有的进行预备工作的线程执行countDown,而CyclicBarrier通过工作线程调用await从而自行阻塞,直到所有工作线程达到指定屏障,再大家一起往下走。
- 在控制多个线程同时运行上,CountDownLatch可以不限线程数量,而CyclicBarrier是固定线程数。
- 同时,CyclicBarrier还可以提供一个barrierAction,合并多线程计算结果。
3、Semaphore
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。应用场景Semaphore可以用于做流量控制,特别是公用资源有限的应用场景,比如数据库连接。假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发地读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有10个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,就可以使用Semaphore来做流量控制。
Semaphore的构造方法Semaphore(int permits)接受一个整型的数字,表示可用的许可证数量。Semaphore的用法也很简单,首先线程使用Semaphore的acquire()方法获取一个许可证,使用完之后调用release()方法归还许可证。还可以用tryAcquire()方法尝试获取许可证。
Semaphore还提供一些其他方法,具体如下。
- intavailablePermits():返回此信号量中当前可用的许可证数。
- intgetQueueLength():返回正在等待获取许可证的线程数。
- booleanhasQueuedThreads():是否有线程正在等待获取许可证。
- void reducePermits(int reduction):减少reduction个许可证,是个protected方法。
- Collection getQueuedThreads():返回所有等待获取许可证的线程集合,是个protected方法。
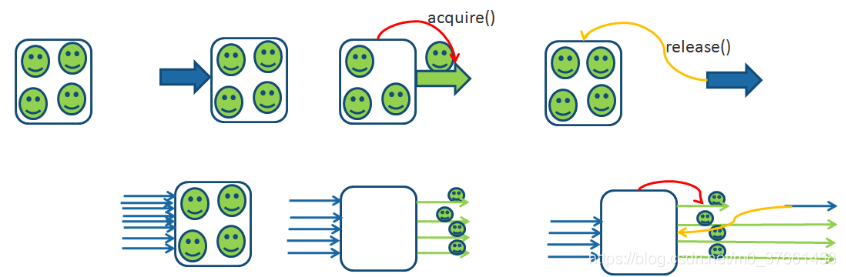
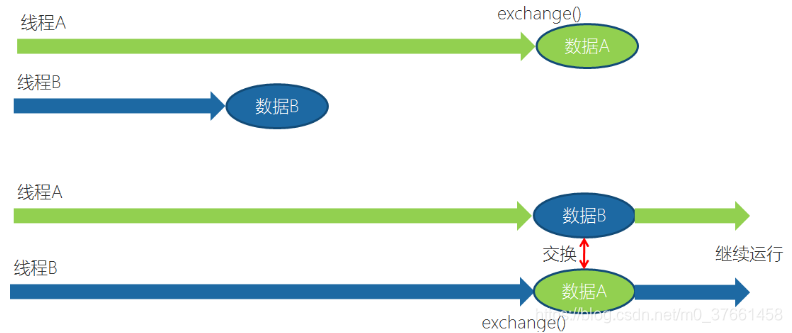
4、Exchange:
Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过exchange方法交换数据,如果第一个线程先执行exchange()方法,它会一直等待第二个线程也执行exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。
5、Callable、Future和FutureTask
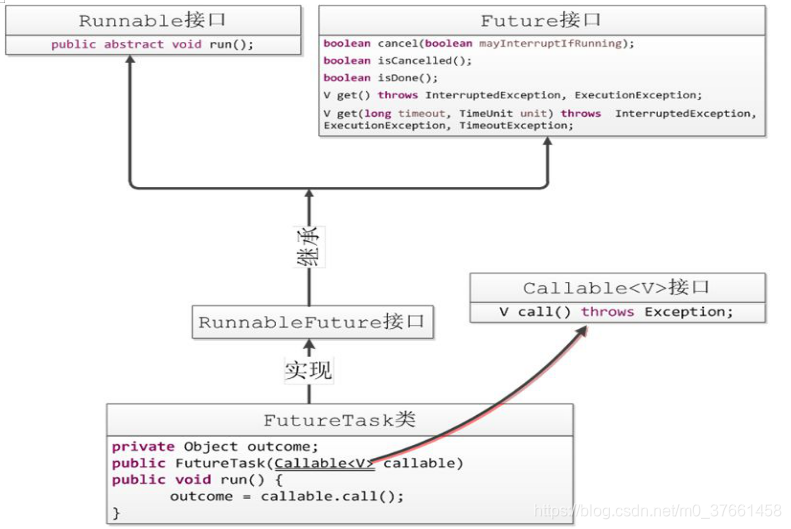
Runnable是一个接口,在它里面只声明了一个run()方法,由于run()方法返回值为void类型,所以在执行完任务之后无法返回任何结果。
Callable位于java.util.concurrent包下,它也是一个接口,在它里面也只声明了一个方法,只不过这个方法叫做call(),这是一个泛型接口,call()函数返回的类型就是传递进来的V类型。
Future就是对于具体的Runnable或者Callable任务的执行结果进行取消、查询是否完成、获取结果。必要时可以通过get方法获取执行结果,该方法会阻塞直到任务返回结果。

FutureTask类实现了RunnableFuture接口,RunnableFuture继承了Runnable接口和Future接口,而FutureTask实现了RunnableFuture接口。所以它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值。
因此我们通过一个线程运行Callable,但是Thread不支持构造方法中传递Callable的实例,所以我们需要通过FutureTask把一个Callable包装成Runnable,然后再通过这个FutureTask拿到Callable运行后的返回值。要new一个FutureTask的实例,有两种方法
三、原子操作CAS (compare atomic swap)
1、什么是原子操作?如何实现原子操作?
假定有两个操作A和B,如果从执行A的线程来看,当另一个线程执行B时,要么将B全部执行完,要么完全不执行B,那么A和B对彼此来说是原子的。
实现原子操作可以使用锁,锁机制满足基本的需求是没有问题的了,但是有的时候我们的需求并非这么简单,我们需要更有效,更加灵活的机制,synchronized关键字是基于阻塞的锁机制,也就是说当一个线程拥有锁的时候,访问同一资源的其它线程需要等待,直到该线程释放锁。
- 这里会有些问题:
- 首先,如果被阻塞的线程优先级很高很重要怎么办?
- 其次,如果获得锁的线程一直不释放锁怎么办?(这种情况是非常糟糕的)。
- 还有一种情况,如果有大量的线程来竞争资源,那CPU将会花费大量的时间和资源来处理这些竞争,同时,还有可能出现一些例如死锁之类的情况。
- 最后,其实锁机制是一种比较粗糙,粒度比较大的机制,相对于像计数器这样的需求有点儿过于笨重。
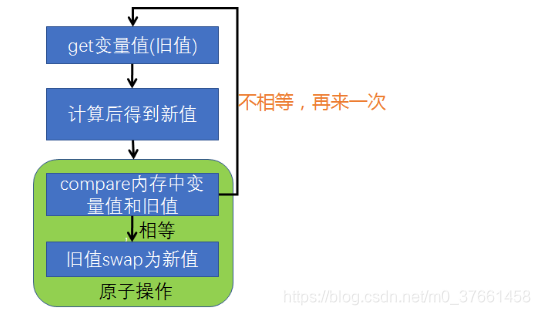
- 实现原子操作还可以使用当前的处理器基本都支持CAS()的指令,只不过每个厂家所实现的算法并不一样,每一个CAS操作过程都包含三个运算符:一个内存地址V,一个期望的值A和一个新值B,操作的时候如果这个地址上存放的值等于这个期望的值A,则将地址上的值赋为新值B,否则不做任何操作。
- CAS的基本思路就是,如果这个地址上的值和期望的值相等,则给其赋予新值,否则不做任何事儿,但是要返回原值是多少。循环CAS就是在一个循环里不断的做cas操作,直到成功为止。
- CAS是怎么实现线程的安全呢?语言层面不做处理,我们将其交给硬件—CPU和内存,利用CPU的多处理能力,实现硬件层面的阻塞,再加上volatile变量的特性即可实现基于原子操作的线程安全。
2、CAS实现原子操作的三大问题
2.1 ABA问题
因为CAS需要在操作值的时候,检查值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。
ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么A→B→A就会变成1A→2B→3A。举个通俗点的例子,你倒了一杯水放桌子上,干了点别的事,然后同事把你水喝了又给你重新倒了一杯水,你回来看水还在,拿起来就喝,如果你不管水中间被人喝过,只关心水还在,这就是ABA问题。
如果你是一个讲卫生讲文明的小伙子,不但关心水在不在,还要在你离开的时候水被人动过没有,因为你是程序员,所以就想起了放了张纸在旁边,写上初始值0,别人喝水前麻烦先做个累加才能喝水。
循环时间长开销大,自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。
只能保证一个共享变量的原子操作:
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。
还有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java 1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作。
2.2 Jdk中相关原子操作类的使用
AtomicInteger使用:
- int addAndGet(int delta):以原子方式将输入的数值与实例中的值(AtomicInteger里的value)相加,并返回结果。
- boolean compareAndSet(int expect,int
update):如果输入的数值等于预期值,则以原子方式将该值设置为输入的值。 - int getAndIncrement():以原子方式将当前值加1,注意,这里返回的是自增前的值。
- int getAndSet(int newValue):以原子方式设置为newValue的值,并返回旧值。 AtomicIntegerArray
主要是提供原子的方式更新数组里的整型,其常用方法如下。
- int addAndGet(int i,int delta):以原子方式将输入值与数组中索引i的元素相加。
- boolean compareAndSet(int i,int expect,int update):如果当前值等于预期值,则以原子方式将数组位置i的元素设置成update值。
需要注意的是,数组value通过构造方法传递进去,然后AtomicIntegerArray会将当前数组复制一份,所以当AtomicIntegerArray对内部的数组元素进行修改时,不会影响传入的数组。
更新引用类型:AtomicReference
原子更新基本类型的AtomicInteger,只能更新一个变量,如果要原子更新多个变量,就需要使用这个原子更新引用类型提供的类。Atomic包提供了以下3个类。
AtomicStampedReference:
利用版本戳的形式记录了每次改变以后的版本号,这样的话就不会存在ABA问题了。这就是AtomicStampedReference的解决方案。
AtomicMarkableReference跟AtomicStampedReference差不多, AtomicStampedReference是使用pair的int stamp作为计数器使用,AtomicMarkableReference的pair使用的是boolean mark。还是那个水的例子,AtomicStampedReference可能关心的是动过几次,AtomicMarkableReference关心的是有没有被人动过,方法都比较简单。
AtomicMarkableReference:
原子更新带有标记位的引用类型,可以原子更新一个布尔类型的标记位和引用类型。构造方法是AtomicMarkableReference(V initialRef,booleaninitialMark)。
原子更新字段类:
如果需原子地更新某个类里的某个字段时,就需要使用原子更新字段类,Atomic包提供了以下3个类进行原子字段更新。要想原子地更新字段类需要两步。第一步,因为原子更新字段类都是抽象类,每次使用的时候必须使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新类的字段(属性)必须使用public volatile修饰符。
AtomicIntegerFieldUpdater:原子更新整型的字段的更新器。
AtomicLongFieldUpdater:原子更新长整型字段的更新器。
AtomicReferenceFieldUpdater:原子更新引用类型里的字段。