本单元主要学习一种能够直接提供针对性、分离的结构与行为描述手段,而且可以在后台把描述元素整合起来的语言——UML。但在学习过程中,我们并不是很关注UML语言的细节,而是更多的关注UML语言建立的模型本身,并通过完成解析UML的作业来加深对UML模型的理解。
两次作业分析
第一次作业
架构分析
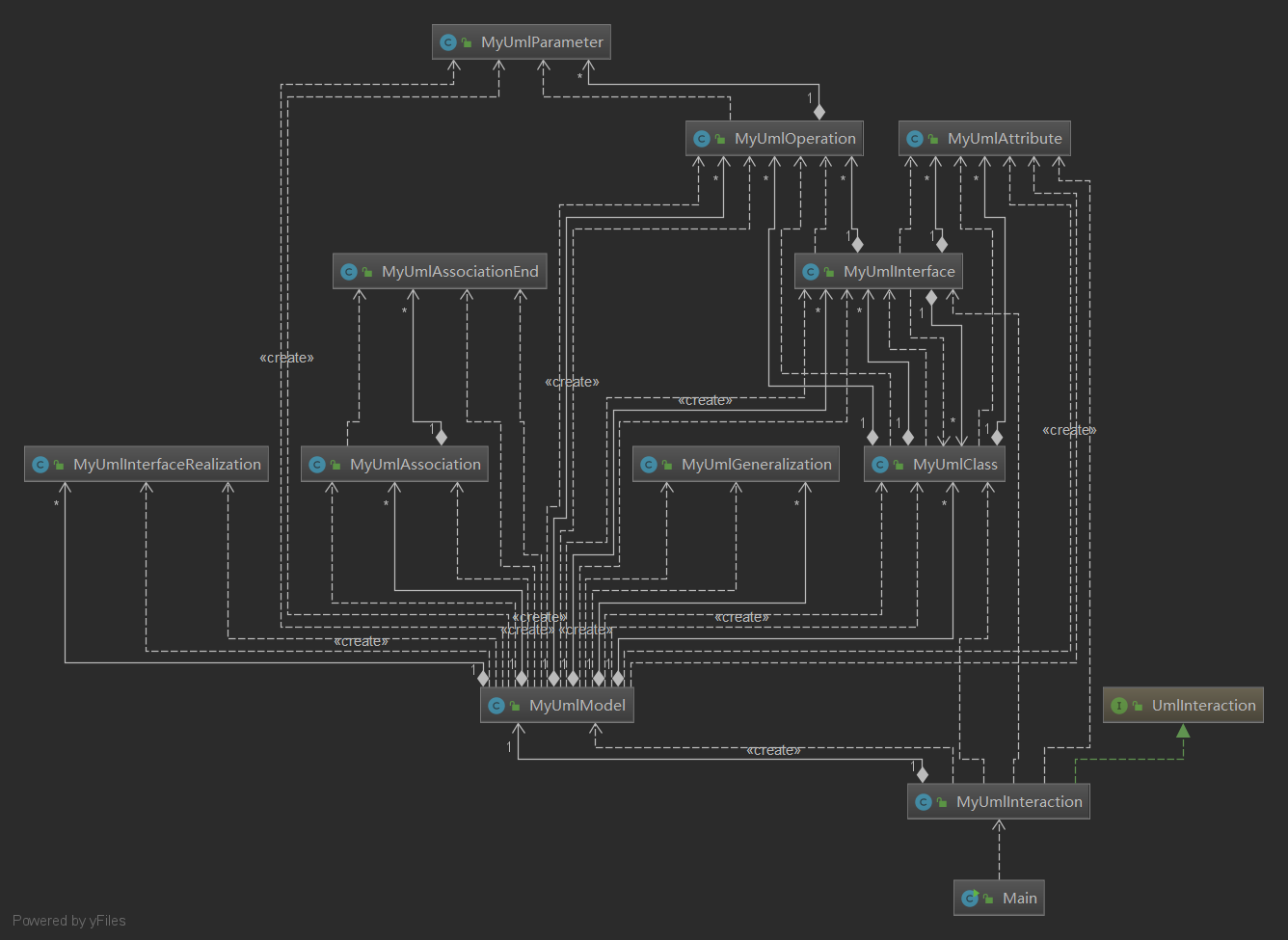
由于UML模型呈现一个树型结构,是划分层次的,所以这次作业的架构比较清晰,不同的对象对应不同的类,每个类做自己该做的事情。在作业中,我把输入的UMLElement都建了一个自己的类。
实现细节
在本次架构中,MyUmlInteraction仅仅负责与用户的交互,在模型管理上,我建了一个MyUmlModel类去存储一个模型内包含的所有元素。所以实际上,MyUmlModel就是一个Model的顶层视图,在这里可以查询和访问到一个Model里面的所有元素。
private HashMap<String, HashMap<String, MyUmlClass>> nameToUmlClass; private HashMap<String, MyUmlClass> idToUmlClass; private HashMap<String, MyUmlOperation> idToUmlOperation; private HashMap<String, MyUmlInterface> idToUmlInterface; private HashMap<String, MyUmlAssociation> idToUmlAssociation; private HashMap<String, MyUmlGeneralization> idToUmlGeneralization; private HashMap<String, MyUmlInterfaceRealization> idToUmlInterfaceRealization;
同时,加多一个MyUmlModel类可以带来的好处是使程序可以拥有处理多个Model的能力,只需要针对每个Model实例化对象即可,虽然本次作业的要求只会输入一个Model,我们并不需要过多关注代码的可扩展性问题,但是我们学习OO的目的不是为了完成作业,而是从OO中锻炼软件设计和代码架构的能力,而这能力就是从作业中得来的,我们平时写代码作业就得养成这种可扩展的思维习惯,这样才能真正得到锻炼。
在处理输入时,由于输入不保证先后顺序,输入中子UmlElement可能在父UmlElement之前,这样在构造父子Element的联系的时候会产生NullPointerException。所以我在处理输入时,按照元素之间的树状结构层次顺序进行处理,先处理UmlClass、UmlInterface,接着处理UmlOperation、UmlAttribute,再处理UmlParameter,最后处理UmlGeneralization和UmlInterfaceRealization和UmlAssociation,并根据UmlAssociation加入UmlAssociationEnd,构建类(接口)之间的关联关系,至此完成输入的处理并构建出各个元素之间的关系。
public MyUmlInteraction(UmlElement[] elements) { this.umlModel = new MyUmlModel(); ArrayList<UmlElement> elementContainer = new ArrayList<>(); this.addClassInterface(elements, elementContainer);
this.addAttributeOperation(elementContainer); this.addParameter(elementContainer); this.addRelations(elementContainer); this.addAssociationEnd(elementContainer); this.umlModel.putAssociation(); }
然后回到作业要求。
(1)模型中一共有多少个类:getClassCount
直接在MyUmlModel中返回Class的数目即可。
(2)类中的操作有多少个:getClassOperationCount
先通过classname在MyUmlModel的nameToClass中找到对应的MyUmlClass,并根据找到的情况来判断是否有类不存在或类存在多个的异常,如果成功找到,则根据要查找的Operation的类型返回对应的数目,在统计Operation不同类型的数目时,采用记忆化查询的方式,如果是第一次查找,则遍历该Class所有的Operation并统计对应类型的数目,之后直接返回遍历结果即可。
(3)类中的属性有多少个:getClassAttributeCount
先通过classname在MyUmlModel的nameToClass中找到对应的MyUmlClass,并根据找到的情况来判断是否有类不存在或类存在多个的异常,如果成功找到,则根据要查找的Attribute的类型返回对应的数目,如果是SELF_ONLY,则直接返回该Class本身包含的Attribute的数目,如果是ALL,则在统计所有Attribute的数目时,采用记忆化查询和递归的方式,如果是第一次查找,则遍历该Class及其父类所有的Attribute并统计数目,之后直接返回遍历结果即可。
public int getAttributeTypeCount(AttributeQueryType attributeQueryType) { if (!initialCountAttribute) { countAttribute(); initialCountAttribute = true; } String mode = attributeQueryType.toString(); if (mode.equals("ALL")) { return this.attributeAll; } else if (mode.equals("SELF_ONLY")) { return this.classAttribute.size(); } return 0; } private void countAttribute() { this.attributeAll = this.getAllAttributeCount(); } private int getAllAttributeCount() { return this.getAttributeCount() + this.getParentAttributeCount(); } private int getParentAttributeCount() { int ans = 0; Iterator<MyUmlClass> iterator = this.classGeneralization.iterator(); while (iterator.hasNext()) { ans += iterator.next().getAllAttributeCount(); } return ans; }
(4)类有几个关联:getClassAssociationCount
先通过classname在MyUmlModel的nameToClass中找到对应的MyUmlClass,并根据找到的情况来判断是否有类不存在或类存在多个的异常,如果成功找到,则根据返回关联的数目,在统计关联的数目时,采用记忆化查询和递归的方式,如果是第一次查找,则统计该Class及其父类所有的关联的数目,之后直接返回遍历结果即可。
public int getAssociationCount() { if (!initialCountAssociation) { countAssociation(); initialCountAssociation = true; } return this.associationAll; } private void countAssociation() { this.associationAll = this.getAllAssociationCount(); } private int getAllAssociationCount() { return this.getSelfAssociationCount() + this.getParentAssociationCount(); } private int getSelfAssociationCount() { return this.classAssociationClass.size() + this.classAssociationInterface.size(); } private int getParentAssociationCount() { int ans = 0; Iterator<MyUmlClass> iterator = this.classGeneralization.iterator(); while (iterator.hasNext()) { ans += iterator.next().getAssociationCount(); } return ans; }
(5)类的关联的对端是哪些类:getClassAssociatedClassList
先通过classname在MyUmlModel的nameToClass中找到对应的MyUmlClass,并根据找到的情况来判断是否有类不存在或类存在多个的异常,如果成功找到,则根据返回关联的List,在统计关联的List时,采用记忆化查询和递归的方式,如果是第一次查找,则统计该Class及其父类所有的关联的List,之后直接返回遍历结果即可。
public HashMap<String, MyUmlClass> getAssociationList() { if (!initialAssociationList) { countAssociationList(); initialAssociationList = true; } return this.classAssociationList; } private void countAssociationList() { HashMap<String, MyUmlClass> selfList = this.getSelfList(); HashMap<String, MyUmlClass> parentList = this.getParenList(); selfList.putAll(parentList); this.classAssociationList = selfList; } private HashMap<String, MyUmlClass> getSelfList() { HashMap<String, MyUmlClass> selfList = new HashMap<>(); Iterator<MyUmlClass> iterator = this.classAssociationClass.iterator(); while (iterator.hasNext()) { MyUmlClass umlClass = iterator.next(); selfList.put(umlClass.getClassId(), umlClass); } return selfList; } private HashMap<String, MyUmlClass> getParenList() { HashMap<String, MyUmlClass> parentList = new HashMap<>(); Iterator<MyUmlClass> iterator = this.classGeneralization.iterator(); while (iterator.hasNext()) { parentList.putAll(iterator.next().getAssociationList()); } return parentList; }
(6)类的操作可见性:getClassOperationVisibilityCount
先通过classname在MyUmlModel的nameToClass中找到对应的MyUmlClass,并根据找到的情况来判断是否有类不存在或类存在多个的异常,如果成功找到,统计出全部的名为methodname的方法的可见性信息并返回即可。
(7)类的属性可见性:getClassAttributeVisibilityCount
先通过classname在MyUmlModel的nameToClass中找到对应的MyUmlClass,并根据找到的情况来判断是否有类不存在或类存在多个的异常,如果成功找到,则根据要查找的attrname的返回对应的attributelist,并根据attributelist为空或者有多个处理属性不存在或者属性存在多个的异常,如果只有一个该属性,则返回其类型即可。在统计所有Attribute的list时,采用递归的方式。
public ArrayList<MyUmlAttribute> getAttributeVisibilityCount( String attribute) { ArrayList<MyUmlAttribute> arrayList; arrayList = countAttributeVisibility(attribute); return arrayList; } public ArrayList<MyUmlAttribute> countAttributeVisibility( String attribute) { ArrayList<MyUmlAttribute> selfList = getSelfAttributeList(attribute); ArrayList<MyUmlAttribute> parentList = getParentAttributeList(attribute); selfList.addAll(parentList); return selfList; } public ArrayList<MyUmlAttribute> getSelfAttributeList(String attribute) { ArrayList<MyUmlAttribute> selfList = new ArrayList<>(); Iterator<MyUmlAttribute> iterator = this.classAttribute.iterator(); while (iterator.hasNext()) { MyUmlAttribute umlAttribute = iterator.next(); if (umlAttribute.getAttributeName().equals(attribute)) { selfList.add(umlAttribute); } } return selfList; } public ArrayList<MyUmlAttribute> getParentAttributeList(String attribute) { ArrayList<MyUmlAttribute> parentList = new ArrayList<>(); Iterator<MyUmlClass> iterator = this.classGeneralization.iterator(); while (iterator.hasNext()) { parentList.addAll(iterator.next(). getAttributeVisibilityCount(attribute)); } return parentList; }
(8)类的顶级父类:getTopParentClass
先通过classname在MyUmlModel的nameToClass中找到对应的MyUmlClass,并根据找到的情况来判断是否有类不存在或类存在多个的异常,如果成功找到,则使用递归的方式找到顶层父类并返回即可。
(9)类实现的全部接口:getImplementInterfaceList
先通过classname在MyUmlModel的nameToClass中找到对应的MyUmlClass,并根据找到的情况来判断是否有类不存在或类存在多个的异常,如果成功找到,则返回类实现的接口的List,在统计类实现接口的List时,采用记忆化查询和递归的方式,如果是第一次查找,则统计该Class及其父类所有的实现接口的List,之后直接返回遍历结果即可。
public HashMap<String, MyUmlInterface> getInterfaceList() { if (!initialInterfaceList) { countInterfaceList(); initialInterfaceList = true; } return this.interfaceCount; } public void countInterfaceList() { HashMap<String, MyUmlInterface> selfInterfaceList = this.getSelfInterfaceList(); HashMap<String, MyUmlInterface> parentInterfaceList = this.getParentInterfaceList(); selfInterfaceList.putAll(parentInterfaceList); interfaceCount = selfInterfaceList; } public HashMap<String, MyUmlInterface> getSelfInterfaceList() { HashMap<String, MyUmlInterface> selfInterfaceList = new HashMap<>(); Iterator<MyUmlInterface> iterator = this.classInterface.iterator(); while (iterator.hasNext()) { selfInterfaceList.putAll(iterator.next().getInterfaceList()); } return selfInterfaceList; } public HashMap<String, MyUmlInterface> getParentInterfaceList() { HashMap<String, MyUmlInterface> parentInterfaceList = new HashMap<>(); Iterator<MyUmlClass> iterator = this.classGeneralization.iterator(); while (iterator.hasNext()) { parentInterfaceList.putAll(iterator.next().getInterfaceList()); } return parentInterfaceList; }
(10)类是否违背信息隐藏原则
先通过classname在MyUmlModel的nameToClass中找到对应的MyUmlClass,并根据找到的情况来判断是否有类不存在或类存在多个的异常,如果成功找到,则返回类的不满足隐藏原则的List,在统计类不满足隐藏原则的List时,采用记忆化查询和递归的方式,如果是第一次查找,则统计该Class及其父类所有的实现接口的List,之后直接返回遍历结果即可。
public HashMap<String, AttributeClassInformation> getHiddenInformationList() { if (!initialCountHiddenAttribute) { countHiddenAttribute(); initialCountHiddenAttribute = true; } return this.nohiddenAttributeList; } public void countHiddenAttribute() { HashMap<String, AttributeClassInformation> selfList = this.getSelfNoHiddenAttribute(); HashMap<String, AttributeClassInformation> parentList = this.getParentNoHiddenAttribute(); selfList.putAll(parentList); this.nohiddenAttributeList = selfList; } public HashMap<String, AttributeClassInformation> getSelfNoHiddenAttribute() { Iterator<MyUmlAttribute> iterator = this.classAttribute.iterator(); HashMap<String, AttributeClassInformation> selfList = new HashMap<>(); while (iterator.hasNext()) { MyUmlAttribute umlAttribute = iterator.next(); if (!umlAttribute.getAttributeVisibility().equals("PRIVATE")) { selfList.put(umlAttribute.getAttributeId(), new AttributeClassInformation( umlAttribute.getAttributeName(), this.className)); } } return selfList; } public HashMap<String, AttributeClassInformation> getParentNoHiddenAttribute() { Iterator<MyUmlClass> iterator = this.classGeneralization.iterator(); HashMap<String, AttributeClassInformation> parentList = new HashMap<>(); while (iterator.hasNext()) { MyUmlClass umlClass = iterator.next(); parentList.putAll(umlClass.getHiddenInformationList()); } return parentList; }
BUG分析
第一次作业比较简单,架构思路非常清晰,所以处理好输入和构建各个元素之间的关系后,直接在模型中查询就可完成作业要求,这次作业没有出现BUG。
第二次作业
架构分析
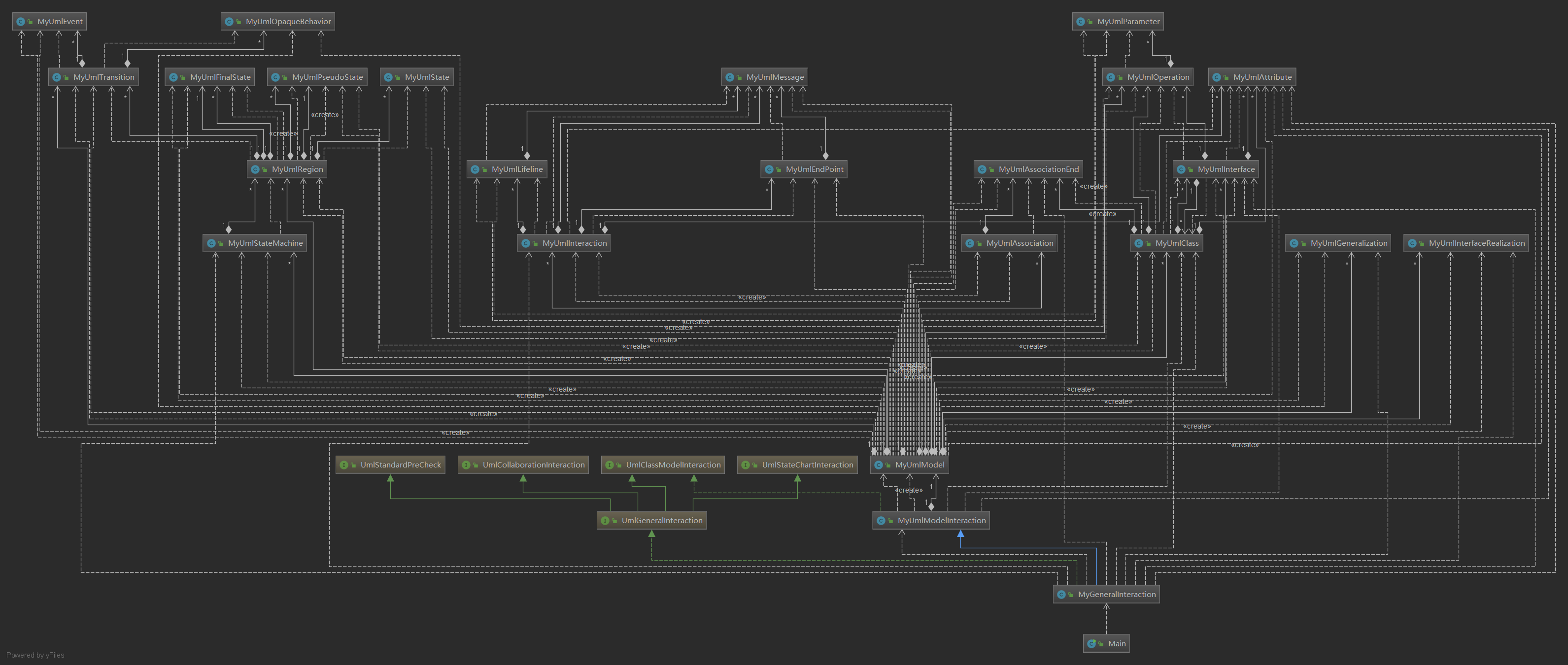
第二次作业是在第一次作业的基础上增加了顺序图和状态图的处理和查询,所以直接挪用第一次作业的代码不用改动,并在第二次作业中进行扩展即可。
实现细节
由于第二次作业是第一次作业的扩展,所以采用了继承的方式继承第一次作业的代码的功能,然后在处理输入上也是根据状态图和顺序图各元素之间的依赖关系按顺序进行处理。
public MyGeneralInteraction(UmlElement[] elements) { super(); this.idToIndex = new HashMap<>(); this.indexToId = new HashMap<>(); this.idToUmlClassOrInterface = new HashMap<>(); this.duplicated = new HashSet<>(); this.graph = new int[205][205]; this.idcount = 0; ArrayList<UmlElement> elementArrayList = new ArrayList<>(); this.initialModelInteraction(elements, elementArrayList); this.addStateMachine(elementArrayList); this.addRegion(elementArrayList); this.addStateElment(elementArrayList); this.addTransition(elementArrayList); this.addTransitionElement(elementArrayList); this.addInteractionElement(elementArrayList); this.addMessage(elementArrayList); initialIndex(); initialGraph(); floyd(); }
同时也由于要实现的功能很多且有行数限制,本应该在Model里面实现的功能我把它们挪到了交互类中,这是我本次作业架构的不合理之处,现在回头想想,更好的做法应该是在Model中再加多三个中间层,即类图、状态图、顺序图,这样的架构就更加完美和完善了。
然后回到作业要求。
(1)给定状态机模型中一共有多少个状态:getStateCount
先通过statemachine_name在MyUmlModel的nameToUmlStateMachine中找到对应的MyUmlStateMachine,并根据找到的情况来判断是否有状态机不存在或状态机存在多个的异常,如果成功找到,直接返回StateMachine中存的state的数目即可。
(2)给定状态机模型中一共有多少个迁移:getTransitionCount
先通过statemachine_name在MyUmlModel的nameToUmlStateMachine中找到对应的MyUmlStateMachine,并根据找到的情况来判断是否有状态机不存在或状态机存在多个的异常,如果成功找到,直接返回StateMachine中存的transition的数目即可。
(3)给定状态机模型和其中的一个状态,有多少个不同的后继状态:getSubsequentStateCount
先通过statemachine_name在MyUmlModel的nameToUmlStateMachine中找到对应的MyUmlStateMachine,并根据找到的情况来判断是否有状态机不存在或状态机存在多个的异常,如果成功找到,可以根据statename在对应的stateMachine中查找,并处理是否有状态不存在或状态存在多个的异常,然后根据statename在stateMachine的状态图中通过bfs找到后继状态即可,其中状态图是在处理transition输入的时候生成的。
public int bfs(String state) { String stateId = this.nameToState.get(state).get(0); int start = getStateIndex(stateId); int[] visited = new int[idcount]; int ans = 0; ArrayBlockingQueue<Integer> visitQueue = new ArrayBlockingQueue<Integer>(idcount); visitQueue.add(start); while (!visitQueue.isEmpty()) { int vnode = visitQueue.poll(); for (int i = 0; i < idcount; i++) { if (stateGraph[vnode][i] > 0 && visited[i] == 0) { visited[i] = 1; ans++; visitQueue.add(i); } } } return ans; }
关于UML顺序图的查询指令
(4)给定UML顺序图,一共有多少个参与对象:getParticipantCount
先通过umlinteraction_name在MyUmlModel的nameToUmlInteraction中找到对应的MyUmlInteraction,并根据找到的情况来判断是否有顺序图不存在或顺序图存在多个的异常,如果成功找到,直接返回该顺序图中的Lifeline个数即可。
(5)给定UML顺序图,一共有多少个交互消息:getMessageCount
先通过umlinteraction_name在MyUmlModel的nameToUmlInteraction中找到对应的MyUmlInteraction,并根据找到的情况来判断是否有顺序图不存在或顺序图存在多个的异常,如果成功找到,直接返回该顺序图中的Message个数即可。
(6)给定UML顺序图和参与对象,有多少个incoming消息:getIncomingMessageCount
先通过umlinteraction_name在MyUmlModel的nameToUmlInteraction中找到对应的MyUmlInteraction,并根据找到的情况来判断是否有顺序图不存在或顺序图存在多个的异常,如果成功找到,在根据lifeline_name判断该顺序图中是否有不存在Lifeline或者Lifeline有多个的异常,如果没有,则直接返回对应Lifeline的incomingMessage的个数即可,其中该个数在处理输入的message时已统计好。
模型有效性检查
(7)R001:针对下面给定的模型元素容器,不能含有重名的成员(UML002)
直接检查MyUmlModel中Class的存储容器,对每一个Class进行属性与属性之间、属性与关联对端之间、关联对端与关联对端之间的重名检查即可。
(8)R002:不能有循环继承(UML008)
(9)R003:任何一个类或接口不能重复继承另外一个接口(UML009)
这两条规则可以采用同样的办法去判断,先在处理Class和Interface的输入时为它们编号,然后处理完generalization和interfaceRealization的输入之后,遍历generalization和interfaceRealization构建Class和Interface之间的有向图,通过Floyd算法,得出Class和Interface之间的连通矩阵。如果出现循环继承,则表明该类(接口)自身可达,只需检查连通矩阵中的对角线即可。若出现重复继承,则在Floyd过程中,A到B之间会出现多条路径,当有第二条路径出现时,把A记录下来,A就是出现循环继承的类(接口),Floyd结束后,在把记录下来的类(接口)所有的子类记录下来即可得到重复继承的类(接口)。
private void floyd() { for (int i = 0; i < idcount; i++) { for (int j = 0; j < idcount; j++) { if (graph[i][j] == 0) { graph[i][j] = maxNum; } } } for (int k = 0; k < idcount; k++) { for (int i = 0; i < idcount; i++) { for (int j = 0; j < idcount; j++) { if (graph[i][j] < maxNum && graph[i][k] + graph[k][j] < maxNum) { duplicatedList.add(i); duplicated.add( idToUmlClassOrInterface.get(indexToId.get(i))); } if (graph[i][j] > graph[i][k] + graph[k][j]) { graph[i][j] = graph[i][k] + graph[k][j]; } } } } for (int i = 0; i < duplicatedList.size(); i++) { int index = duplicatedList.get(i); for (int j = 0; j < idcount; j++) { if (graph[j][index] < maxNum) { duplicated.add( idToUmlClassOrInterface.get(indexToId.get(j))); } } } }
BUG分析
本次作业强测错了一个点,原因是忘记判断类中的属性重名问题了。指导书上虽然解释了除了以上三条检查规则以外都可以在JDK 8上实现,但是由于经过第一次作业的洗礼,同学们容易形成惯性思维,再加上第二条规则说检查重名时是“类和关联对端之间不能有重名”,这个会产生歧义,就究竟是只有类和关联对端的重名检查呢,还是另外包括属性之间 、对端之间的检查呢?由于上述原因,同学们在第二次作业可能不会处理属性重名问题, 希望下次指导书可以出得更明确点。
四单元中架构设计及OO理解方法的演进
第一单元
第一单元的作业是实现多项式的求导,由于是刚刚接触Java语言和面向对象编程方式,还不是很熟悉,所以前三次作业基本都是按照面向过程的方法来写,即按照逻辑顺序,处理输入→实现求导→输出结果。并没有对每个对象进行建类然后划分层次,也有觉得使用面向对象编程对每个对象例如因子、项和多项式建类的话,会导致代码行数很多,由于之前尽量把代码写少的习惯,所以也没有按照每个对象一个类的方法去编写代码。
第二单元
第二单元的作业是以电梯为例子实现多线程,在这个单元中我们学习了多线程的编写模式包括生产者-消费者模式和工人模式,同时也学习了维护线程安全的锁与wait-notify机制。在这次作业中我分别就请求、乘客、请求队列共享对象(实际上相当于调度器)和电梯建了类,请求线程专门处理输入,然后把请求放在调度器中;电梯负责把乘客送到目的地,然后不断向调度器询问请求;调度器通过判断电梯的运行情况和请求的输入情况决定是否给予请求和中止电梯运行。在这次作业中我对一个类专门负责一个功能有了理解。
第三单元
第三单元的作业是根据JML实现一个Path的管理功能,在这个单元官方提供了输入输出接口给我们,让我们摆脱了处理WF的问题,更加专注于代码的架构和设计实现,而且JML是一门契约型语言,只要架构正确,完成JML要求的代码也一定是正确的,这使我们的代码的正确性得到极大提高。在这个单元中,每一次作业都是对上一次作业的扩展,也让我对OO的继承有了更深的理解。
第四单元
第四单元的作业是让我们完成UML图的简单解析,同样课程组提供了输入输出接口,我们只需要考虑设计和实践即可。在这次作业中我才真正领会到OO的精华所在,即分门别类、各司其职。在作业指导书中助教建议我们去看看官方包的源码,经过阅读之后我发现官方包中真的是对每一个UMLElement进行建类,然后这些子类都统一拥有父类UMLElement,于是在前面对继承的理解和对分门别类的理解的基础上,这个单元的作业我自认为是写得最OO的一次。我对每个元素不管作业用不用到都建了一个类,然后还在作业的基础上考虑了代码的扩展性,比如作业要求只输入一个UMLModel,但是我对UMLModel建了一个类管理UMLElement,这样我的代码就支持多个UMLModel的输入了,再比如作业要求UMLClass不会出现多继承,但是我在MyUmlClass中用的HashMap存储继承的父类,并在相关访问方法中支持多继承,所以我的代码也支持多继承输入的扩展。这样处理虽然代码总体上多了很多,但是架构会很清晰,每个类都能各司其职,妙不可言。
测试理解与实践演进
第一单元
第一单元的自我测试,由于采用了正则表达式的方法,所以采用了形式验证的方式,只要正则表达式正确,就能处理正确的输入和错误的输入,同时在正确的输入的基础上,只需要检查实现细节,就能得知自己代码的正确性,所以自我构造的数据不是很多。同时debug的时候可以使用单步调试非常的方便。
第一单元的互测是基于对源代码的阅读理解,这样虽然找到BUG的几率很高,但是时间花费的成本也很高,有点得不偿失的感觉。虽然有同学分享了自动生成测试数据的工具和用脚本自动运行代码的方法,但是最终还是没有在本地实现。
第二单元
第二单元的自我测试是构造边界数据去测试了,尤其是实现换乘的时候,由于官方提供了输入输出接口,对于就不存在WF的问题了,在构造测试数据的时候主要检查线程安全和能否正常结束线程。但是由于在多线程中,线程运行的不确定性,多线程不好使用单步调试,此时用最原始和传统的printf大法是最有效的。
第二单元的互测也是构造数据去测试,尤其是线程安全和压力测试。
第三单元
在第三单元,由于输入比较好构造,我和舍友用C语言分别写了对拍器和数据构造器,然后在java代码中采用文件输入和输入的形式,实现了半自动化的测试,并且在半自动化的测试中找到自己代码的一个BUG。
第三单元的互测自然也是随机生成数据提交,不过由于这次作业是由JML要求的,所以只要代码满足JML规格,就不会出现BUG,因此在互测中也没有找到同组的BUG。
第四单元
第四单元的测试是自己用starUML构造数据,然后通过官方的java包解析生成输入进行测试。这次作业的输入不好自动构造,所以测试的数据不多,但是UML图的结构相对固定,所以构造边界测试数据也很方便。
总的来说,测试的时候最好的做法就是每完成一个功能或者函数就进行测试,测试的工具自然是使用Junit。不过在写作业时总感觉时间不够,所以实际上完成一个功能进行测试时,是直接输入样例数据而不是使用Junit。同时我们也应该掌握单步调试和Printf调试的基本方法,这样才能写出更加安全稳定的代码。
课程收获
总的来说经过这个学期OO的虐待之后,收获还是挺丰富的。首先了解了IDEA这个强大的工具的基本使用,然后还学习到了Java语言的基本应用,以及多线程的实现,还有JML规格语言在工程之中的运用,最后还学习了UML模型在设计架构中的使用。
最重要的是学习到了OO的思想——一切皆对象,让我以后在写代码中会更加主动的去思考架构和设计,而不是拿到要求就面向过程开始写代码。
(1)第一单元对于WF的要求非常奇怪,比如第二次作业+++1不合法,第三次作业+++1突然又合法了,而且第一单元在 处理这种输入格式的时候就会占用很多时间,让同学没有时间去思考架构和面向对象实现的方式,对于OO入门来说 不合理。
(2)第二单元的时候线程安全部分可以挪到第一次作业来讲,因为第一次作业就要我们实现线程,而如果没有线程安全 的知识的话,初次写线程会调进线程安全的坑。
(3)OO理论课和实验课的时间可以安排分开,上午讲课下午就上机未免过于仓促,或者可以在每次实验的上一周布置实