面向对象设计与构造:OO课程总结
第一部分:UML单元架构设计
第一次作业
UML图
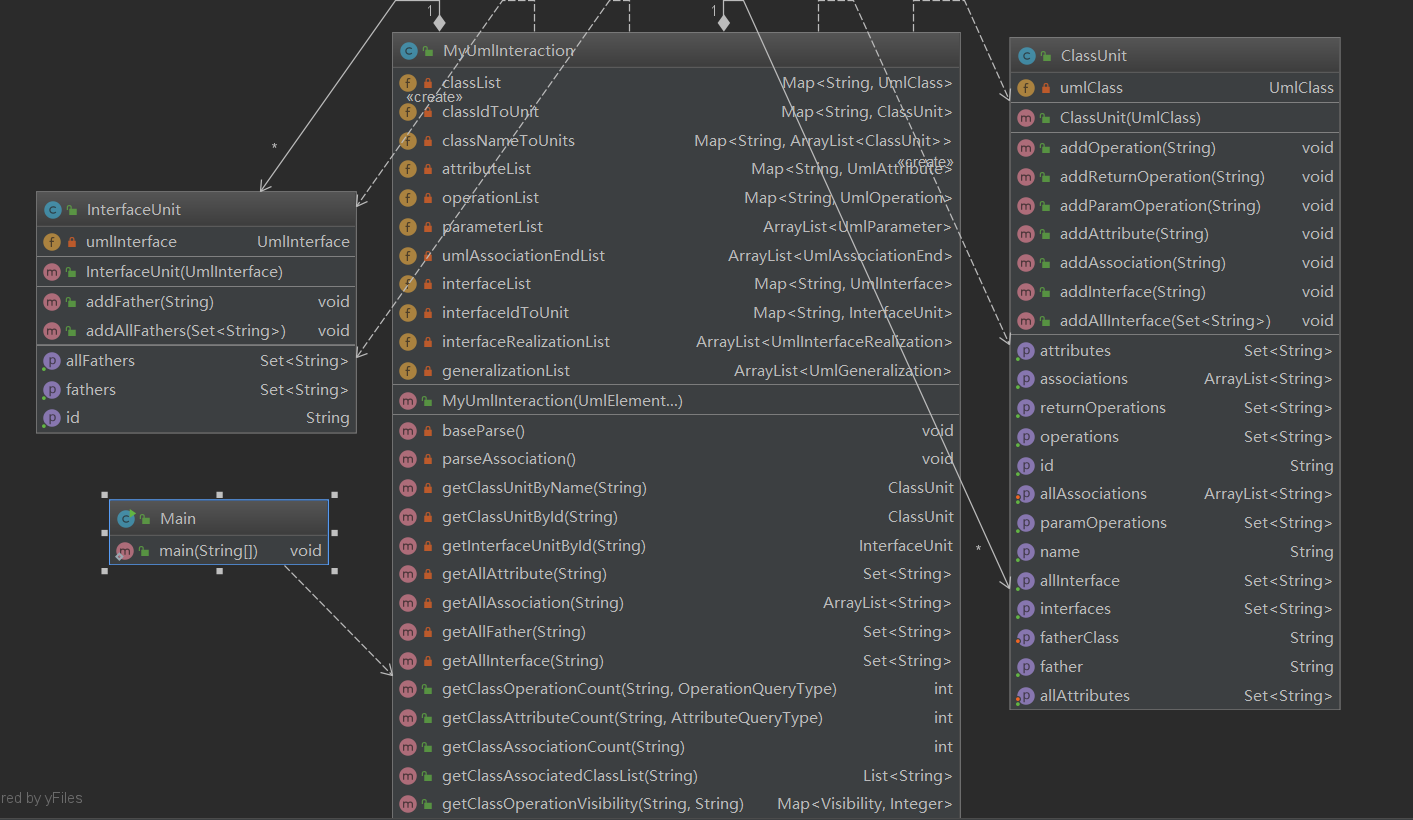
- MyUmlInteraction类实现接口方法,ClassUnit和InterfaceUnit管理UML图中的类和数据单元
- MyUmlInteraction类整合UML类图中的所有数据元素,并用Map建立相应的Id到UmlElement的映射
- ClassUnit除了记录自身的属性,关联和实现接口外,采用All-XXX的形式记录来自父类的上述元素继承和自身的上述元素
- InterfaceUnit分别记录了自身继承的父类接口和继承的所有父类接口
递归回溯
需要查询和记录父类的信息时,采用了递归回溯的思想,下面以getAllAttribute方法为例
//MyUmlInteraction.java
private Set<String> getAllAttribute(String classId) {
ClassUnit target = getClassUnitById(classId);
if (target.getId().equals(target.getFather())) {
return target.getAttributes();
}
if (target.getAllAttributes() == null) {
ClassUnit father = getClassUnitById(target.getFather());
target.setAllAttributes(getAllAttribute(father.getId()));
}
return target.getAllAttributes();
}
//ClassUnit.java
private Set<String> attributes = new HashSet<>();
private Set<String> allAttributes = null;
...
public void setAllAttributes(Set<String> attributes) {
allAttributes = new HashSet<>();
allAttributes.addAll(attributes);
allAttributes.addAll(this.attributes);
}
public Set<String> getAllAttributes() {
return allAttributes;
}- 该方法完成的功能:返回Id为classId的类所包含的所有属性
- 第一个if语句判断此时classId对应的类是否为顶层类(在ClassUnit中fatherClass的Id全部初始化为自身的Id)
- 如果该类不是顶层类,需要找到所有父类包含的所有属性。allAttributes如果为null表示查询该类所有属性的操作还未进行,需要递归查找父类的所有属性,并添加进allAttributes数据结构中;allAttributes不为null说明已经记录好了该类所有属性,直接返回数据结构即可
第二次作业
架构与代码实现
说实话我感觉第二次作业工程量巨大,为了保证扩展性,要维护大量的数据结构
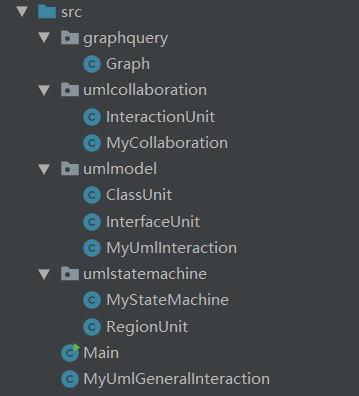
有向图图查询
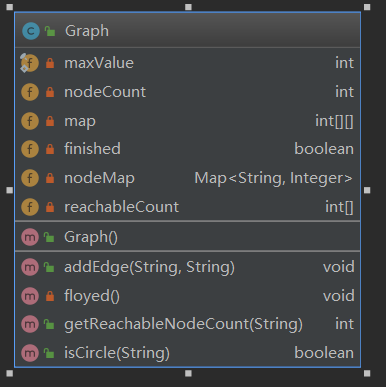
addEdge:有向图加边,传入的两个String为类或接口的Id,nodeMap建立Id到node编号映射
public void addEdge(String fromId, String toId) { if (!nodeMap.containsKey(fromId)) { nodeMap.put(fromId, nodeCount++); } if (!nodeMap.containsKey(toId)) { nodeMap.put(toId, nodeCount++); } map[nodeMap.get(fromId)][nodeMap.get(toId)] = 1; }floyed:图更新算法
getReachableNodeCount:寻找该结点后续可达结点
public int getReachableNodeCount(String id) { if (!nodeMap.containsKey(id)) { return 0; //未加入有向图中说明id对应的类或接口无继承或被继承关系 } if (!finished) { //finish为graph的全局变量,因为图建立好以后只需跑一次floyed算法 floyed(); finished = true; } int nodeId = nodeMap.get(id); if (reachableCount[nodeId] != maxValue) { //如果已经统计过一次直接返回结果 return reachableCount[nodeId]; } int answer = 0; for (int i = 0; i < nodeCount; i++) { if (map[nodeId][i] != maxValue) { //map[i][j]均初始化为maxValue answer++; } } reachableCount[nodeId] = answer; return answer; }isCircle:是否存在自身到自身的循环。这里主要看
map[id][id]是否为maxValue,如果不是则存在自环
时序图和状态图
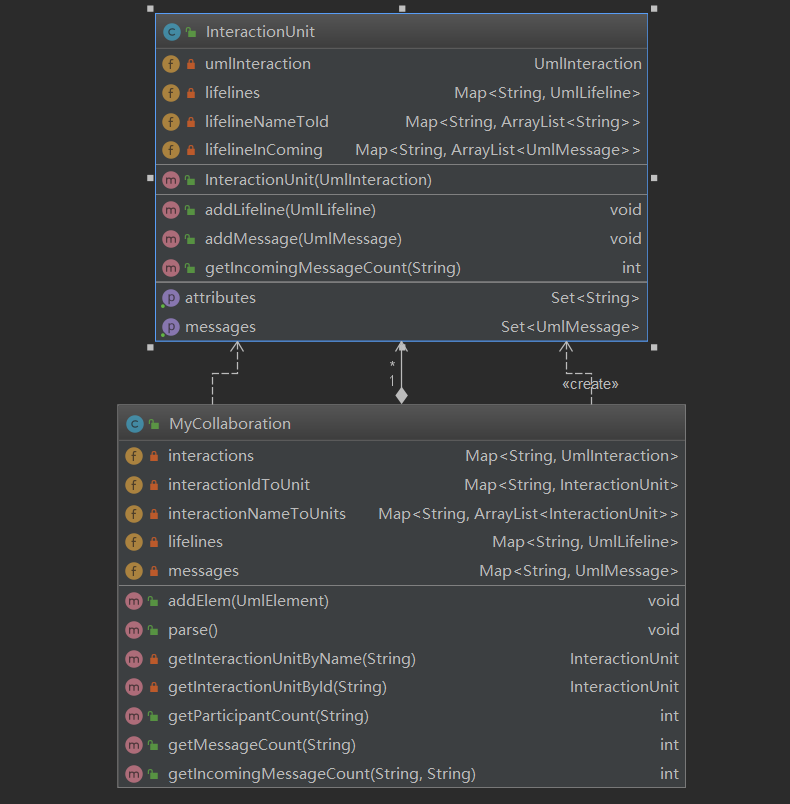
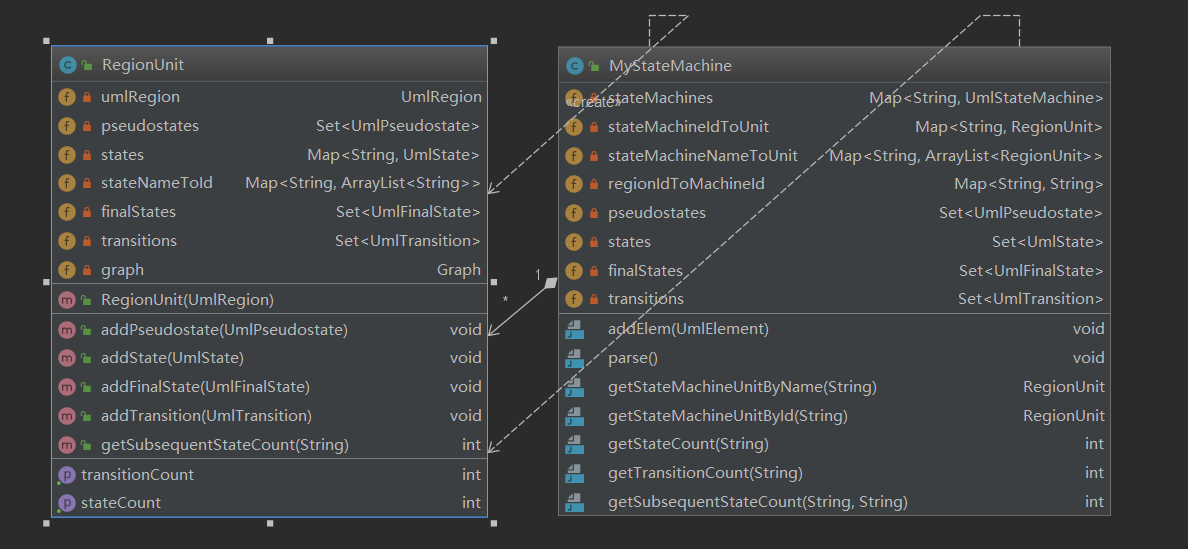
- 记录数据结构,提供查询接口即可
- 状态图中的getSubsequentStateCount方法实现采用了有向图查询类
类图
保留第一次作业实现的功能
重复继承的检查
public void checkForUml009() throws UmlRule009Exception { Set<UmlClassOrInterface> answer = new HashSet<>(); //检查类是否重复实现接口 for (String i : classList.keySet()) { ArrayList<String> temp1 = getAllImplementedInterfaces(i); Set<String> temp2 = new HashSet<>(temp1); if (temp1.size() != temp2.size()) { answer.add(classList.get(i));//类实现的所有接口列表中存在重复元素 } } //检查接口是否重复继承接口 for (String i : interfaceList.keySet()) { ArrayList<String> temp1 = getAllInterfaceFathers(i); Set<String> temp2 = new HashSet<>(temp1); if (temp1.size() != temp2.size()) { answer.add(interfaceList.get(i));//接口继承的所有接口列表中存在重复元素 } } if (answer.size() != 0) { throw new UmlRule009Exception(answer); } }- 主要的思路是使用Arraylist和Set去查重,getAll-XXX方法均返回
Arraylist<String>
- 主要的思路是使用Arraylist和Set去查重,getAll-XXX方法均返回
循环继承的检查采用有向图的自环检查即可
第二部分:课程收获
本来觉得,这十五次作业我只是在一味地设计与编码,并没有将某次架构深入极致或收获颇丰。但回过头来想想,我发现这更像是一种体验,好像自己的设计能力是比无头苍蝇好一点了,代码也敲得快了,各种工具也会用了,JML和UML也会写会画了。虽然不知道影响多大,但也算熬过了本次巅峰体验
架构
表达式求导,规格和UML单元在我看来,更多的是在做数据结构的事情:如何封装数据,如何解析数据,如何设计查询和修改的接口。所以对于实际问题,我的思路逐渐成型:
- 明确需要管理和维护的数据,封装成类并提供相应查询和修改接口
- 根据对数据的操作是否具有共性,确定在类内部实现还是抽象为操作类(如UML作业中的循环继承和后继状态实际上可抽象为有向图的解析,而对于寻找类所有属性实际上为数据内容的集合,在类中实现即可)
电梯单元在我看来,更多的是在维护线程安全,因此我的做法是:
- 画流程图(非常重要,甚至涉及架构的正确性)
- 流程图实质上是状态图,所以要求状态的完备性,确保所有的输入对应到的所有后继状态
- 在流程图找到可能会起冲突的临界区,用矩形框圈起来标识
- 分析冲突区域,找到起冲突的数据单元,隔离相应的增删查改操作
- 画流程图(非常重要,甚至涉及架构的正确性)
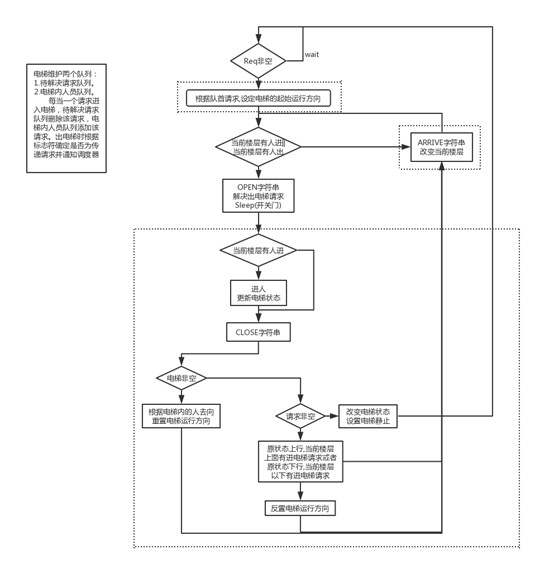
- 划分数据单元,将线程相关与数据相关进行隔离(通俗地说,维护数据的类就不要有run方法)
关于OO方法理解的进演
什么,oo方法?肝!
重提SOLID原则
- SRP(单一责任原则):避免类的功能重合和一个类做太多事
- 什么是类的功能重合?调度器类在根据当前状态分配任务,电梯类自身调度任务干什么?
- 一个有效代码超过300行的类,实则是类的层次划分不够明晰,该抽象抽象,该写包写包(譬如UML单元作业,ClassUnit单元可以写在MyUmlInteraction类里面,但没有必要)
- OCP(开放封闭原则):对扩展开放,对修改封闭
- 上一次的架构要考虑扩展性,已经写好的代码没有特殊需求就不要改变(譬如UML第一次作业getAllAttributes方法返回类型为
Set<String>,第二次作业改为ArrayList<String>才实现了重复继承的检查。这个例子实际上说明了一个问题:应保留原始数据,在具体的对外查询接口内再处理) - 基于扩展中的继承问题,直接在类里添加代码实现新功能或创建子类实现新功能视功能的复杂度而定
- 上一次的架构要考虑扩展性,已经写好的代码没有特殊需求就不要改变(譬如UML第一次作业getAllAttributes方法返回类型为
- LSP(里氏替换原则):所有引用基类的地方必须能透明地使用其子类的对象
- 子类可以扩展父类的功能,但不能改变父类原有的功能。我们用继承不就是用父类中的重复代码吗?
- 子类在替换掉父类后必须不能影响到原程序的运行状态。这里就涉及到多态的问题了
ISP(接口分离原则):避免接口的责任重合和一个接口做太多事情
- 接口分离的难点在于对方法的抽象,遗憾的是我们的作业大多是根据官方接口去实现程序
DIP(依赖倒置原则):模块之间尽可能依赖于抽象实现
- 简而言之,多采用基于抽象类的代码设计模式,其实我们的作业设计也差不多采用这种模式
- 本学期课程我很少用设计模式去进行架构,看来需要更多的实践才行啊 ~
测试
愿以后的工作没有互测,不做社畜,少受社会的毒打,不用霸王洗发水
生成测试数据
- 从功能说明入手。例如JML单元,查询最短路构造自环等情况
- 从架构细节入手。主要是检查架构的完备性,以及架构各部分的逻辑正确性
测试实践
- IDEA源代码打包jar→测试数据in.txt→输出结果out.txt→脚本对拍(fc对比文件差异)
jprofiler:查看CPU占用,线程生命周期,堆栈使用情况。分析程序的性能
JML检查工具系列:针对规格化程序设计的规格语言测试,生成测试样例
Junit:单元测试,针对某一方法进行单独测试
第三部分:课程建议
一,精简理论课内容,从架构难点深入讲解
- 理论课的PPT实在是缺少场景例子,尤其涉及架构的理论知识冗余,各种名词晦涩难懂
- 一遇到具体如何架构的地方感觉就会浅尝则止,庞大的代码工作量无法预留更多时间进行架构上的探索
- 理论课的内容完全可以收录许多精品贴(比如对各种UMLElement元素的解析)
二,实验上机后放出实验内容,给出标程
- 实验上机的内容实属良品,尤其是画UML图等很考察我们在短时间内进行初步架构设计的能力
- 不放标程,不让我们回头寻思一番,实验分数没有意义
三,指导书需要更加明确,对有争议的地方及时更新
- 重点在刚刚结束的第十四次作业,指导书的质量在逐渐下滑(就事论事)
- 这里说的及时更新应该是在周六晚前解决大部分疑问,重点是不影响架构设计的进程
四,建立良好的测试数据库机制(下届)
- 测试数据库的准入前提应是你为数据库的贡献可量化,测试数据的抓取应做到随机与限量
- 建议单独开设如何构造覆盖性更优的测试数据讨论专栏