前言
本文是笔者的读书笔记。若有缘,欢迎批评指正补充。
面向:
- 略知程序编译的过程,但不是很清楚每一步的细节
- 还不能熟练使用调试器
- 想更深入了解编程语言和程序的背后发生了什么
- 没事闲来看看技术文章的人
本文不包含:
- 程序优化的方案
- 程序的设计方式
- 编写实用软件的技巧
基础知识:
- 已经掌握了“常规”的C语言的编写技能
- 知道一些“常见”的计算机名词和它们的含义
- 通过查询文档(man ,Google)可以大致了解未知API的使用
代码
本文使用如下的代码(hello.c)。
1 #include <stdio.h> 2 3 int main(int argc, char *argv[]) { 4 5 asm volatile("# printf begin"); 6 7 printf("Hello, world! %d %s\n", argc, argv[0]); 8 9 asm volatile("# printf end"); 10 11 return 0; 12 }
为了方便阅读生成后的汇编代码,我们可以在想观察的函数调用前后加上特定的标识,这样只需要从生成后的汇编代码中查找这些字符串就能定位了。
另外,编译使用gcc,命令如下:
$ gcc hello.c -Wall -g -O0 -S -o hello.s $ gcc hello.s -o hello.out $ objdump -d hello.out > hello.asm
这里列出在笔者的环境下最后生成的 hello.asm 的 main 函数的部分。
当然也可以阅读 .s 文件,只看 CPU 执行的指令部分的话,两者的内容是一样的。
000000000000064a <main>: 64a: 55 push %rbp 64b: 48 89 e5 mov %rsp,%rbp 64e: 48 83 ec 10 sub $0x10,%rsp 652: 89 7d fc mov %edi,-0x4(%rbp) 655: 48 89 75 f0 mov %rsi,-0x10(%rbp) 659: 48 8b 45 f0 mov -0x10(%rbp),%rax 65d: 48 8b 10 mov (%rax),%rdx 660: 8b 45 fc mov -0x4(%rbp),%eax 663: 89 c6 mov %eax,%esi 665: 48 8d 3d 98 00 00 00 lea 0x98(%rip),%rdi # 704 <_IO_stdin_used+0x4> 66c: b8 00 00 00 00 mov $0x0,%eax 671: e8 aa fe ff ff callq 520 <printf@plt> 676: b8 00 00 00 00 mov $0x0,%eax 67b: c9 leaveq 67c: c3 retq 67d: 0f 1f 00 nopl (%rax)
解析
官方文档
Intel 公开的 Intel 64 和 IA-32 架构手册可以在这个网站找到:
https://software.intel.com/en-us/articles/intel-sdm
官方网站同时还公布了扩展指令集的文档、性能优化文档等等。
寄存器
x86 架构中,以 e 开头的是 32 位寄存器,以 r 开头的是 64 位寄存器。
上面的汇编代码中出现的寄存器都属于 GPR(General-purpose Register),也就是说程序可以自由操作这些寄存器的值,所以在使用方法上和内存并没有什么区别。
在上面的汇编命令中,用括号标起来的寄存器(比如 (%rax) ),代表这个寄存器的值所指向的内存地址里面保存着的值。
用C语言来说明的话就是 *(int *)rax 。
而如果在括号前面还有数值的话,就代表这个寄存器的值加减那个数值之后所指向的内存地址里面保存着的值。
比如 -0x10(%rbp) 的意思是,内存中 rbp 的值减 16(注意是 16 进制)的位置所储存的值。
同样用C语言来说明的话就是 *(int *)((char *)rbp - 0x10) 。
上面用C语言的解释可能不准确。
具体来说, mov 并没有指定数据的大小,也就是说具体是拷贝 32 位还是 64 位的数据取决于第一个参数,也就是数据源的寄存器的大小。
笔者分析后认为,652 处的 mov 会拷贝 32 位的数据,而 655 处的 mov 会拷贝 64 位的数据。
还有需要注意的一点是,比如 rax 和 eax 其实并不是两个独立的寄存器。 eax 所指的是 rax 的下面 32 位。
同时还有 ax , ah , al 。
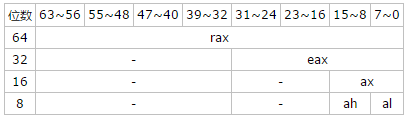
栈
编译器把 rsp (32 位的寄存器是 esp )专门用作了堆栈指针(SP,stack pointer)。
x86 的 SP 是向更小的方向伸展的,也就是说减小 rsp 的值就等于拿到了这部分的栈空间。
另外, rsp 必须对齐到 16 字节(即 rsp 的值必须是 16 的倍数)。
但是在 main 的里面并没有类似的命令。
笔者在 start 的部分找到了对齐的命令,汇编如下:
0000000000000540 <_start>: 540: 31 ed xor %ebp,%ebp 542: 49 89 d1 mov %rdx,%r9 545: 5e pop %rsi 546: 48 89 e2 mov %rsp,%rdx 549: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp 54d: 50 push %rax 54e: 54 push %rsp 54f: 4c 8d 05 9a 01 00 00 lea 0x19a(%rip),%r8 # 6f0 <__libc_csu_fini> 556: 48 8d 0d 23 01 00 00 lea 0x123(%rip),%rcx # 680 <__libc_csu_init> 55d: 48 8d 3d e6 00 00 00 lea 0xe6(%rip),%rdi # 64a <main> 564: ff 15 76 0a 20 00 callq *0x200a76(%rip) # 200fe0 <__libc_start_main@GLIBC_2.2.5> 56a: f4 hlt 56b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
观察 564 处的命令可以猜出这段指令应该是在 main 之前被执行的。
而 549 处的命令应该就是对齐 rsp 的命令了(把 rsp 的最后4位变成0,也就是16的倍数了)。
函数调用
在 32 位架构中,函数调用时的参数都会放在栈空间当中(似乎也有放在寄存器里面的扩展)。
而在 64 位架构中,由于寄存器的数量变多了( r8 ~ r15 ),很多情况下可以直接把参数放在寄存器里。
原书中采用的是 32 位架构下的汇编代码,而笔者分析的是 64 位的汇编代码,因此函数调用的步骤有了不小的差异。
下面大多都是笔者个人的分析。
“把参数放在寄存器里”这个条件对于主函数应该也同样适用。
主函数的参数(有两个)应该分别储存在了 edi 和 rsi 当中。第一个是 int 类型,在这里是 32 位的,所以被放在了 edi 里面。而指针的数组(就是指针)在 64 位架构下肯定是 64 位的,所以被储存在了 rsi 当中。
而在下面的步骤里,由于要调用 printf 函数,所以需要先把 edi 和 rsi 的值保存到栈中。这样才能修改这些寄存器的值。所以程序先将 SP 的值减小了 16,扩充了 16 字节的栈空间。
接下来,程序就把两个参数都储存到了栈里面。
而再接下来的一连串命令,先是储存了 argv[0] 到了 rdx 当中,又把 argc 储存到了 esi 当中,最后又把格式化用的字符串(的地址)储存到了 rdi 当中。
这个格式化用的字符串是写在执行程序里面的,可以从取地址的时候用到了 rip 寄存器(用来存储 PC 的 64 位寄存器)这一点来推断。这也是为什么这种字符串在执行时是不能被改变的。
接下来就是函数调用的命令。而后返回。
nop 是什么都不做的意思(no-operation)。这里填入 nop 是为了让后面的函数对齐到 16 字节处(67d 向后数 3 个刚好是 680,也就是对齐到了 16 字节)。
笔者认为,破坏了 edi 和 rsi 却没有从栈里面复原是因为后面没有用到这些值。对此猜测并没有做更深一步的检验。
总结
在这一部分,笔者学习了寄存器的基本用途,函数调用的模式。
经过这一天的洗礼,笔者现在可以以 CPU 大约五十亿分之一的速度来理解程序了,耶。