之前的文章里面谈到过,我从R转到Python上,一个很大的不习惯就是R的数据结构比较简单,但是Python的数据类型比较多,很容易就令人头脑混乱。但是今天学习了一下Udacity的课程,顿时就清楚多了。
Python最基础的数据类型包括数组、列表、字典比较常见的。而Numpy和Pandas的数据类型是在基础数据类型上建立,彼此相关,又彼此不同。
Numpy里面最基本的就是一维的对象np代指,这点我认为和列表list基本没有什么不同,很多操作(比如各种的for循环)在list上实现,同时也完全可以在numpy对象实现。但是numpy之所以是numpy,最重要的一点就是numpy向量化操作的特点,这点和R语言里面还是比较类似,当然Matlab几乎也是向量化操作。比较基础的就是加减乘除的运算,当然还有一点比较容易被忽略的就是np对象和if条件的使用。
例如 a=np.array([1,2,3,4,-1,-2,-3,-4]) ,b=np.array([-1,3,9,0,-2,9,3,-5)],想要找到a,b里面到底有多少个对元素在相同位置上正负号一致?
这里我要挖个坑,未来可能会做更多的练习,会把我遇上的情况分享一下。
Pandas里面最基本的对象叫做Series。Series 和 np 有很多相类点,例如position 索引、切片、循环(for),以及一些基础函数X.mean(),X.max(),X.argmax()。用法几乎是一致的。要说最大的不同点,我认为就是索引。Pandas的索引有两种模式,一种是位置索引,例如a[0]、或者是a.iloc[0],iloc的意思是integer-location based indexing for selection by position ,还有一种是key索引(我自己这么叫的),例如a.loc['title'] ,loc的意思是 label-location based indexer for selection by label。这两种不同的索引暴露了Series的本质,就是pandas对象本质上是字典和列表的混合,这点很重要。
OK,这里做一个小结:np对象最重要特点向量化运算,pandas对象最重要特点是字典和列表混合。
But,我在学习过程中还是有很多numpy & pandas 衍生出来的问题。嗯,今天就碰到了!
Q1:有些函数忘记到底是应用在pd 还是 np 上?
A1:本来是想要去doc里面查查,一个个对比看看。现在想着索性还是先了解一下两个库里面常用的函数或者属性。
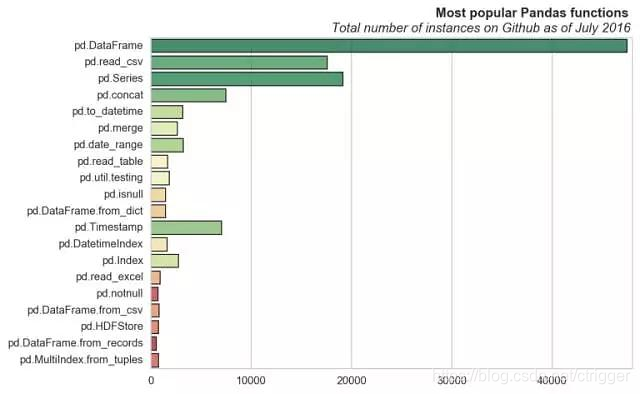
pandas常用属性
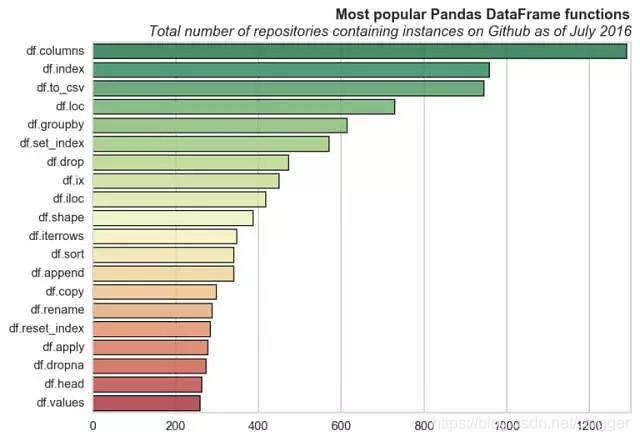
dataframe 常用属性
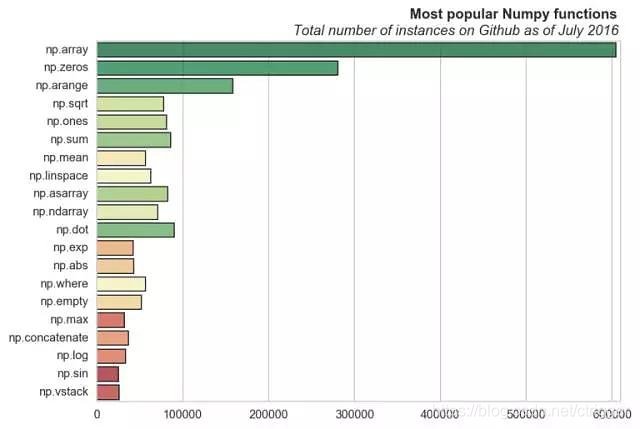
numpy 常用属性
可以这么理解,pandas常用的属性基本都是数据操作类的;而numpy基本上都是数据基础运算的,还有一个神级Lib Scipy 里面的常用函数是统计&优化类的。
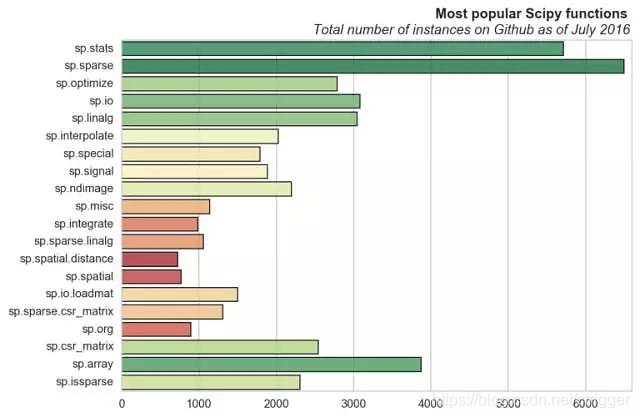
scipy 常用函数
eg.分组统计、缺失值处理都是pd的管辖,生成随机数等是numpy的管辖。
今天学了.dropna , .fillna 都是pd的属性。
说实话,目前并没有体会出numpy有什么卓越的优越性,这个等我慢慢体会,这也需要是一篇文章!
来源:https://www.douban.com/note/635632989/