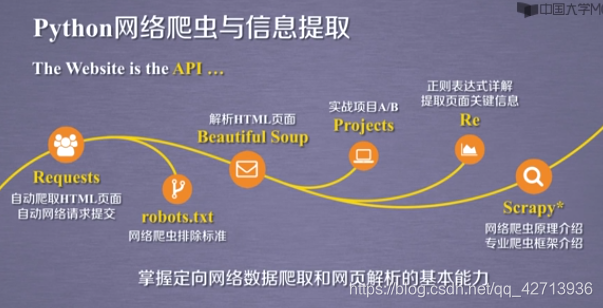
1 网络爬虫之前奏
1.1 网络爬虫课程内容导学
1.2 Python语言开发工具选择

本课主要使用以下4种:

python的IDLE是python自带的默认的常用的入门级编写工具
2 网络爬虫之规则
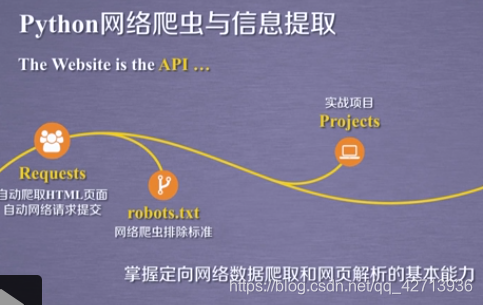
2.1 Requests库入门
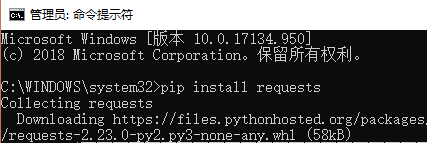
2.1.1 Requests的安装方法
Requests库(http://www.python-requests.org)是公认的最好的爬取第三方库,由2个特点:
- 简单
- 很简洁,甚至用一行代码就能从网页上获取相应的资源
安装方法:以管理员运行command
测试:

2.1.2 Requests库的get()方法

Python大小写敏感

使用request方法封装
Requests库一共提供7个常用方法,request方法是基本方法,其他6个方法提供调用request方法实现

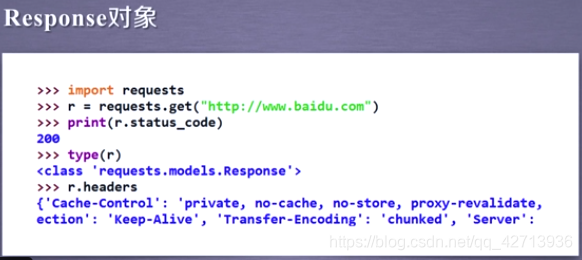
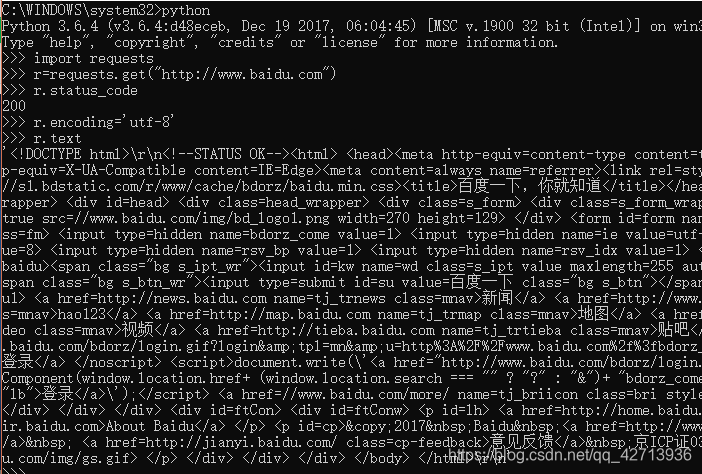
r.status_code:检测请求的状态码。如果是200,则说明返回成功。
r.headers:获得页面的头部信息
Response对象包括服务器返回的全部信息和向服务请求的request信息

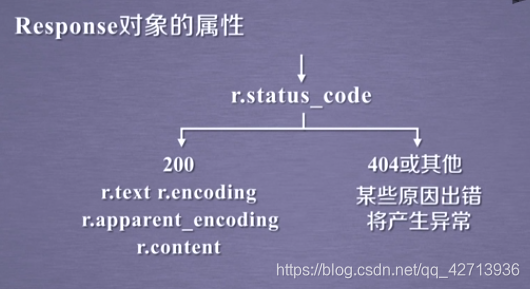


网络上的资源都有编码,如果没有编码就会导致无法可读
r.apparent_encoding比r.encoding更准确
2.1.3 爬取网页的通用代码框架
可以准确可靠的爬取
get不一定永远可以,因为网络连接有风险,异常处理很重要

Timeout:发出URL请求到获得内容整个过程的异常
ConnectTimeout:只是连接远程服务器

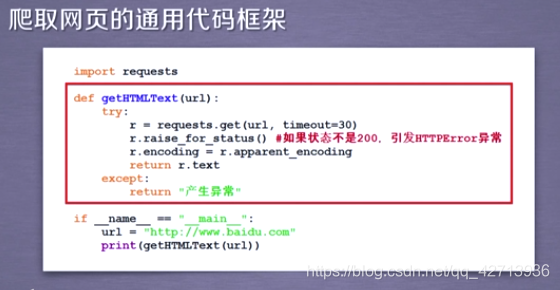

通用代码框架使得爬取变得更稳定更有效更可靠
2.1.4 HTTP协议及Requests库方法
HTTP协议

用户发起请求,服务器响应。
无状态请求是第一次和第二次之间没有关联
应用层协议指该协议工作于tcp协议之上(?)


即相当于文件的路径,只不过是存在Internet上的

即Requests库提供的6个函数

HTTP协议通过URL对资源做定位,通过常用的6个方法对资源管理,每一次操作都是独立无状态的
在HTTP协议的世界里,网络通道和服务器都是黑盒子,他能看到的就是URL和对URL做相应操作

Requests库方法(post()、put())


用很少的流量获取网络资源的概要信息
Request的post()方法传的类型不同,得到的结果不同:
1.
2.

2.1.2 Requests库主要方法解析
request


OPTIONS:向服务获取一些服务器能跟客服端打交道的参数,不与获取资源直接相关,所以用的比较少


向服务器提交数据

也是比较常见的提交数据的

定制HTTP头
Chrome/10:代表Chrome的第10个版本
可模拟任何浏览器向服务器发出访问



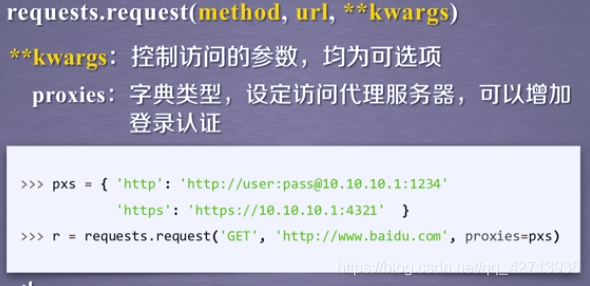
隐藏用户用户爬取网页的原IP地址

get

head

post

put

patch

delete
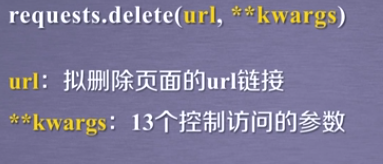
总结
为什么要这样设计?后6个方法时,由于某些方法要常用到某些参数,所以就把这些参数作为显示定义的参数量放到参数,其他放到可选参数里
最常使用get方法,向服务器爬取内容而不提交内容
2.1.3 总结

使用get爬虫
使用head获得较大资源的概要


import requests
import time
def getHTMLText(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
except:
print("failed")
if __name__=="__main__":
start=time.perf_counter()
for i in range(100):
getHTMLText("http://www.baidu.com")
end=time.perf_counter()
print("用时%.5f秒"%(end-start))

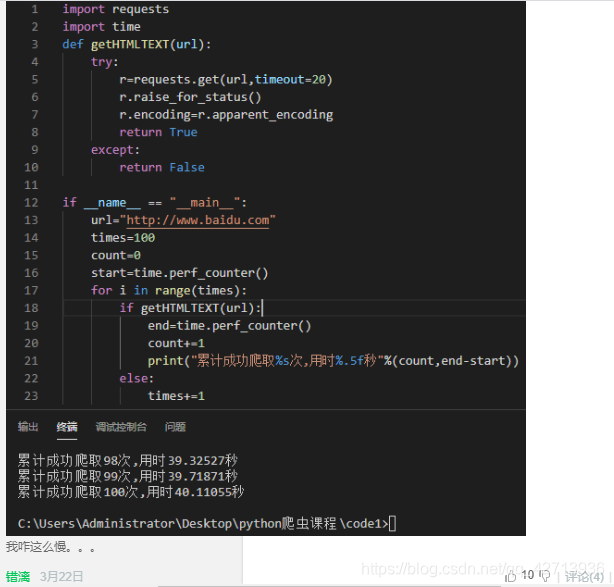
我没有考虑它是否成功的爬取了100次。。。
2.2 网络爬虫的“盗亦有盗”
2.2.1 网络爬虫引发的问题





2.2.2 Robots协议


不允许以“?”“popm目录下的html文件”。。。

无robots协议就是说可以任意爬取
2.2.3 Robots协议的遵守方式



即访问次数小
2.3 Requests库网络爬虫实战(5个实例)
以爬虫视角看待网络内容
2.3.1 京东商品页面的爬取
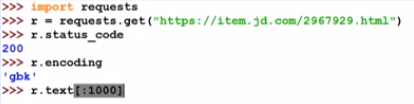
r.encoding:从HTTP的头部分就可以解析出编码信息,京东提供了编码
import requests
import time
def getHTMLText(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text[:1000])
except:
print("failed")
if __name__=="__main__":
getHTMLText("https://item.jd.com/100006349587.html")
居然跳出的是登陆

2.3.2 亚马逊商品页面的爬取
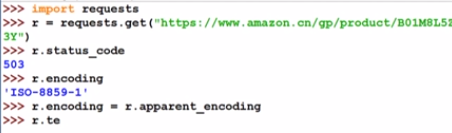

能爬回来东西说明就不是网络的问题
也就是说网站拒绝了爬虫的请求
response对象r包含了request请求
所以要修改头部信息

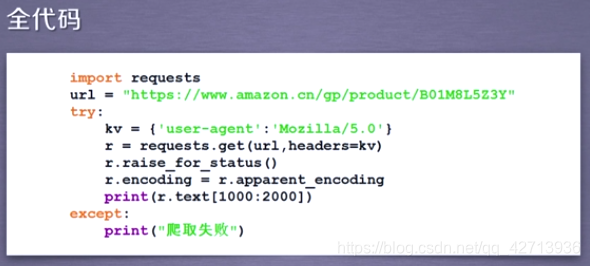
2.3.3 百度360搜索关键词提交

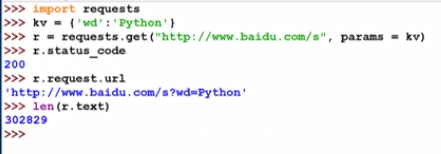
解析内容以后讲

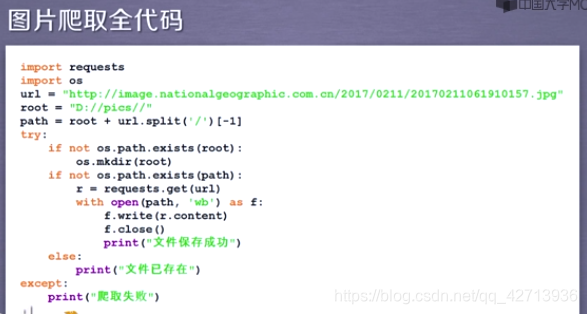
2.3.4 网络图片的爬取和存储

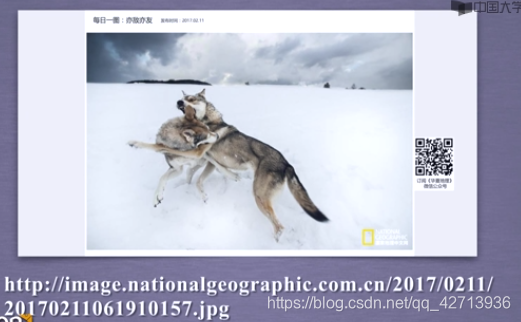
图片是二进制形式,如何保存为文件?
- 自定义名字
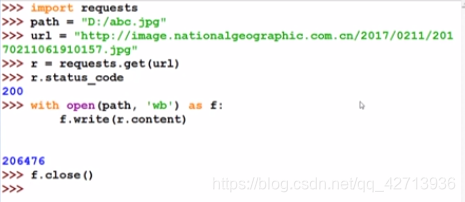
- 原名字
2.3.5 IP地址归属地的自动查询
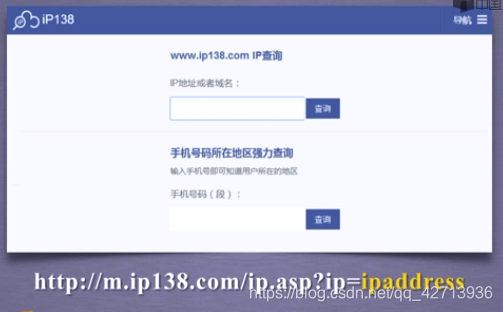
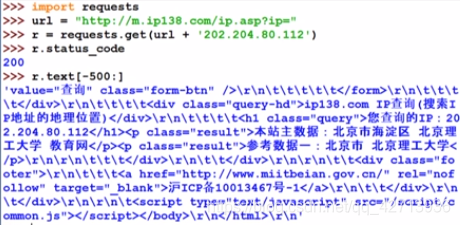
尽量约束r.text的大小,如r.text[-500:],否则会影响idle的使用
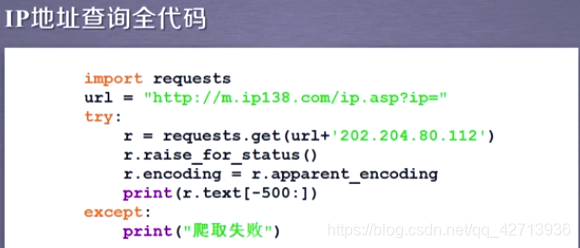
只要知道按下按钮后向后台提交的url的形式,就可以代码模拟提交