Query q = NumericRangeQuery.newLongRange("idField", 1L, 10L, true, true);
对数值类型建索引的时候,会把数值转换成多个 lexicographic sortable string ,然后索引成 trie 字典树结构。
例如:假设num1 拆解成 a ,ab,abc ;num2 拆解成 a,ab,abd 。
【图1】:
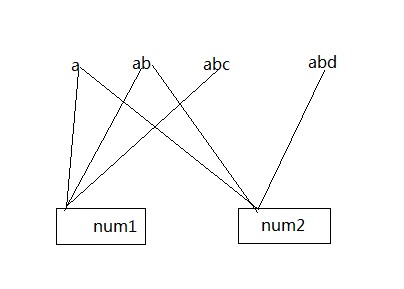
通过搜索ab 可以把带ab 前缀的num1,num2 都找出来。在范围查找的时候,查找范围内的数值的相同前缀可以达到一次查找返回多个doc 的目的,从而减少查找次数。
下面讲解一下 :数值类型的索引和范围查询的工作原理。
1:数值的二进制表示方式
以long 为例:符号位+63位整数位,符号位0表示正数 1表示负数。
对于正数来说低63位越大这个数越大,对于负数来说也是低63位越大。
如果对符号位取反。则long.min -- long.max 可表示为:0x0000,0000,0000,0000 -- 0xFFFF,FFFF,FFFF,FFFF
经过这样的转换后, 是不是从字符层面就已经是从小到大排序了?
2:如何拆分前缀
以0x0000,0000,0000,F234为例,每次右移4位。
1:0x0000,0000,0000,F23 与 0x0000,0000,0000,F230 --0x0000,0000,0000,F23F 范围内的所有数值的前缀一是一致的
2:0x0000,0000,0000,F2 与 0x0000,0000,0000,F200 ——0x0000,0000,0000,F2FF 范围内的所有数值的前缀一致
3:0x0000,0000,0000,F 与 0x0000,0000,0000,F000 --0x0000,0000,0000,FFFF 范围内的所有数值的前缀一致
....
0x0
如果用右移几位后的值做key,可以代表一个相应的范围。key可以理解成数值的前缀
3:对大范围折成小范围
Lucene 在查询时候的法做法是对大范围折成小范围,然后每个小范围分别用前缀进行查找,从而减少查找次数。
4:数值类型的索引的实现
先设定一个PrecisionStep (默认4),对数值类型每次右移(n-1)* PrecisionStep 位。
每次移位后,从左边开始每7位存入一个byte,组成一个byte[],
并且在数组第0位插入一个特殊byte,标识这次的偏移量。
每个byte[]可以转成一个lexicographic sortable string。
lexicographic sortable string 的字符按字典序排列后,和偏移量,数值的大小顺序是一致的。——这个是NumericRangeQuery 范围查找的关键!
long 类型一共64位,如果precisionStep=4,则会有16个lexicographic sortable string。
相当于16个前缀对应一个long数值,再用lucene 的倒序索引,最终索引成类似【图1】 的那种索引结构。
拆分的关键代码:
org.apache.lucene.util.NumericUtils 类的 longToPrefixCodedBytes() 方法
public static void longToPrefixCodedBytes(final long val, final int shift, final BytesRefBuilder bytes) {
if ((shift & ~0x3f) != 0) // ensure shift is 0..63
throw new IllegalArgumentException("Illegal shift value, must be 0..63");
//计算byte[]的大小,每位七位存入一个byte
int nChars = (((63-shift)*37)>>8) + 1; // i/7 is the same as (i*37)>>8 for i in 0..63
//最后还有第0位存偏移量,所以+1
bytes.setLength(nChars+1); // one extra for the byte that contains the shift info
bytes.grow(BUF_SIZE_LONG);
//标识偏移量,shift
bytes.setByteAt(0, (byte)(SHIFT_START_LONG + shift));
//把符号位取反
long sortableBits = val ^ 0x8000000000000000L;
//右移shift位,第一次shifi传0,之后按precisionStep递增
sortableBits >>>= shift;
while (nChars > 0) {
// Store 7 bits per byte for compatibility
// with UTF-8 encoding of terms
//每7位存入一上byte ,前面第一位为0——在utf8中表示ascii码.并加到数组中。
bytes.setByteAt(nChars--, (byte)(sortableBits & 0x7f));
sortableBits >>>= 7;
}
}5:范围查询
大致思想是从范围的两端开始拆分。先把低位的值拆成一个区间,再移动PrecisionStep到下一个高位又并成一个区间。
最后把小区间里每个值,按移动的次数,用和索引的同样方式转成lexicographic sortable string.进行查找。
代码:
org.apache.lucene.util.NumericUtils 类的 splitRange() 方法
private static void splitRange(
final Object builder, final int valSize,
final int precisionStep, long minBound, long maxBound
) {
if (precisionStep < 1)
throw new IllegalArgumentException("precisionStep must be >=1");
if (minBound > maxBound) return;
for (int shift=0; ; shift += precisionStep) {
// calculate new bounds for inner precision
final long diff = 1L << (shift+precisionStep),
mask = ((1L<<precisionStep) - 1L) << shift;
final boolean
hasLower = (minBound & mask) != 0L,
hasUpper = (maxBound & mask) != mask;
final long
nextMinBound = (hasLower ? (minBound + diff) : minBound) & ~mask,
nextMaxBound = (hasUpper ? (maxBound - diff) : maxBound) & ~mask;
final boolean
lowerWrapped = nextMinBound < minBound,
upperWrapped = nextMaxBound > maxBound;
if (shift+precisionStep>=valSize || nextMinBound>nextMaxBound || lowerWrapped || upperWrapped) {
// We are in the lowest precision or the next precision is not available.
addRange(builder, valSize, minBound, maxBound, shift);
// exit the split recursion loop
break;
}
if (hasLower)
addRange(builder, valSize, minBound, minBound | mask, shift);
if (hasUpper)
addRange(builder, valSize, maxBound & ~mask, maxBound, shift);
// recurse to next precision
minBound = nextMinBound;
maxBound = nextMaxBound;
}
}例如:1001,0001-1111,0010 分步拆分成
1: 1001,0001-1001,1111 ( 第0次偏移后 0x91-0x9F 有15个term )
和 1111,0000 -1111,0010 ( 第0次偏移后 0xF0-0F2 有3个term )
2: 1002,0000 – 1110,1111 右移一次后(0x11- 0x15 有5个term )
查找23个lexicographic sortable string.就可以覆盖整个区间。