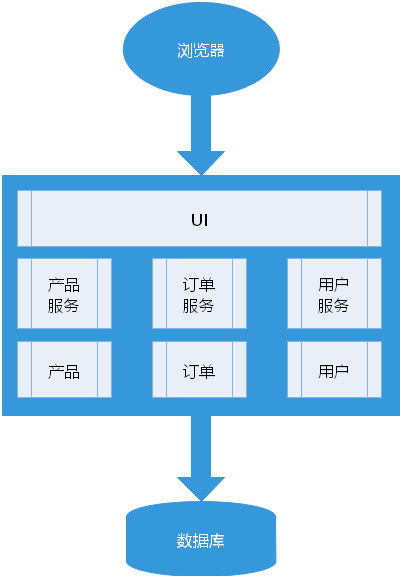
传统的开发模式
既所有的功能打包在一个 WAR 包里,基本没有外部依赖(除了容器),部署在一个 JavaEE 容器(Tomcat,JBoss,WebLogic)里,包含了 DO/DAO,Service,UI 等所有逻辑。
优点
- 开发简单,集中式管理
- 基本不会重复开发
- 功能都在本地,没有分布式的管理和调用消耗
缺点
- 效率低:开发都在同一个项目改代码,相互等待,冲突不断
- 维护难:代码功功能耦合在一起,新人不知道何从下手
- 不灵活:构建时间长,任何小修改都要重构整个项目,耗时
- 稳定性差:一个微小的问题,都可能导致整个应用挂掉
- 扩展性不够:无法满足高并发下的业务需求
微服务架构
有效的拆分应用,实现敏捷开发和部署
官方的定义
- 一系列的独立的服务共同组成系统
- 单独部署,跑在自己的进程中
- 每个服务为独立的业务开发
- 分布式管理
- 非常强调隔离性
大概的标准
- 分布式服务组成的系统
- 按照业务,而不是技术来划分组织
- 做有生命的产品而不是项目
- 强服务个体和弱通信( Smart endpoints and dumb pipes )
- 自动化运维( DevOps )
- 高度容错性
- 快速演化和迭代

微服务的实践
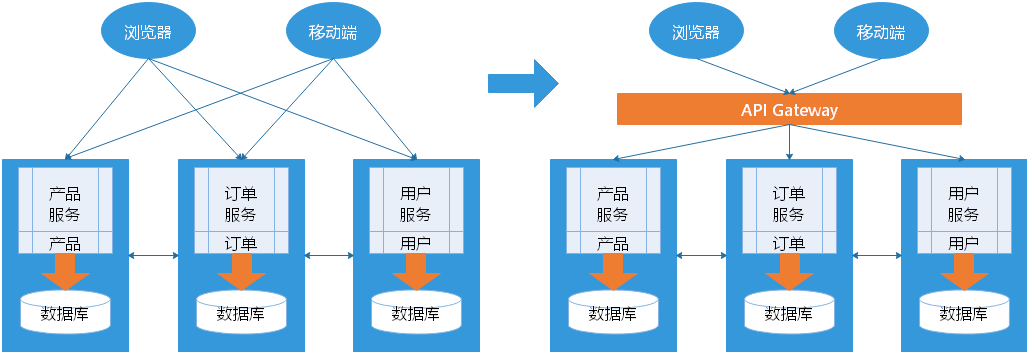
客户端如何访问这些服务
后台有 N 个服务,前台就需要记住管理 N 个服务,一个服务 下线、更新、升级,前台就要重新部署,这明显不服务我们拆分的理念,特别当前台是移动应用的时候,通常业务变化的节奏更快。
另外,N 个小服务的调用也是一个不小的网络开销。还有一般微服务在系统内部,通常是无状态的,用户登录信息和权限管理最好有一个统一的地方维护管理(OAuth)。不需要在N个服务上都记录会话。这种称为SSO单点登录
所以一般在后台 N 个服务和 UI 之间一般会一个代理或者叫 API Gateway,他的作用包括:
- 提供统一服务入口,让微服务对前台透明
- 聚合后台的服务,节省流量,提升性能
- 提供安全,过滤,流控等API管理功能
其实这个 API Gateway 可以有很多广义的实现办法,可以是一个软硬一体的盒子,也可以是一个简单的 MVC 框架,甚至是一个 Node.js 的服务端。他们最重要的作用是为前台(通常是移动应用)提供后台服务的聚合,提供一个统一的服务出口,解除他们之间的耦合,不过 API Gateway 也有可能成为 单点故障点或者性能的瓶颈。
每个服务之间如何通信
同步调用(两种方式)
- REST(框架:JAX-RS,Spring Boot) 对外REST,http通讯
- RPC(框架:Thrift, Dubbo) 对内RPC,远程过程调用(例如在产品服务中,直接new RPCUser()(用户服务对象))
同步调用比较简单,一致性强,但是容易出调用问题,性能体验上也会差些,特别是调用层次多的时候。一般 REST 基于 HTTP,更容易实现,更容易被接受,服务端实现技术也更灵活些,各个语言都能支持,同时能跨客户端,对客户端没有特殊的要求,只要封装了 HTTP 的 SDK 就能调用,所以相对使用的广一些。RPC 也有自己的优点,传输协议更高效,安全更可控,特别在一个公司内部,如果有统一个的开发规范和统一的服务框架时,他的开发效率优势更明显些。就看各自的技术积累实际条件,自己的选择了。
异步消息调用
- Kafka
- Notify
- MessageQueue
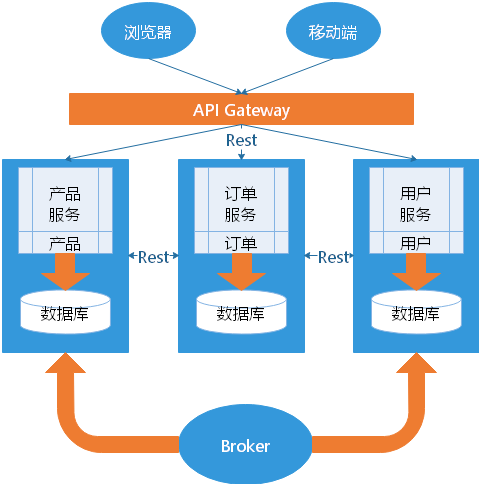
异步消息的方式在分布式系统中有特别广泛的应用,他既能减低调用服务之间的耦合,又能成为调用之间的缓冲,确保消息积压不会冲垮被调用方,同时能保证调用方的服务体验,继续干自己该干的活,不至于被后台性能拖慢。不过需要付出的代价是一致性的减弱,需要接受数据 最终一致性;还有就是后台服务一般要实现 幂等性,因为消息送出于性能的考虑一般会有重复(保证消息的被收到且仅收到一次对性能是很大的考验);最后就是必须引入一个独立的 Broker,Broker服务器起到一个消息缓冲作用。所有的消息先经过Broker,在由Broker传递给处理服务器,处理。有Broker,表示对消息的持久化,需要对消息的准确处理。像Kafka,不需要Broker,只追求速度。一般用于日志处理。
如此多的服务,如何实现?
在微服务架构中,一般每一个服务都是有多个拷贝,一方面来做负载均衡,另一方面,当其中一个服务下线,不会影响整个服务的运行。一个服务随时可能下线,也可能应对临时访问压力增加新的服务节点。服务之间如何相互感知?服务如何管理?
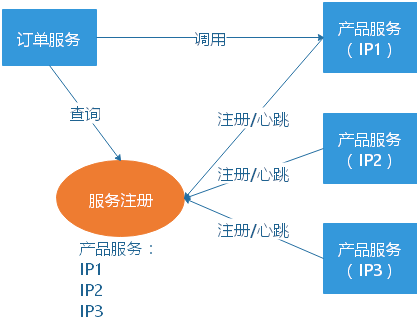
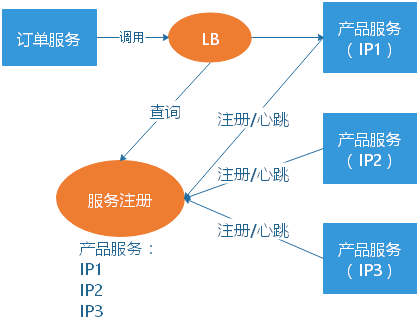
这就是服务发现的问题了。一般有两类做法,也各有优缺点。基本都是通过 Zookeeper(框架) 等类似技术做服务注册信息的分布式管理。当服务上线时,服务提供者将自己的服务信息注册到 ZK(或类似框架),并通过心跳(类似ping)维持长链接,实时更新链接信息。服务调用者通过 ZK 寻址,根据可定制算法,找到一个服务,还可以将服务信息缓存在本地以提高性能。当服务下线时,ZK 会发通知给服务客户端。
基于客户端的服务注册与发现
优点是架构简单,扩展灵活,只对服务注册器依赖。缺点是客户端要维护所有调用服务的地址,有技术难度,一般大公司都有成熟的内部框架支持,比如 Dubbo。
基于服务端的服务注册与发现
优点是简单,所有服务对于前台调用方透明,一般在小公司在云服务上部署的应用采用的比较多。
服务挂了,如何解决?
前面提到,Monolithic 方式开发一个很大的风险是,把所有鸡蛋放在一个篮子里,一荣俱荣,一损俱损。而分布式最大的特性就是网络是不可靠的。通过微服务拆分能降低这个风险,不过如果没有特别的保障,结局肯定是噩梦。所以当我们的系统是由一系列的服务调用链组成的时候,我们必须确保任一环节出问题都不至于影响整体链路。相应的手段有很多:
- 重试机制
- 限流
- 熔断机制
- 负载均衡
- 降级(本地缓存,停止部分服务,包整程序整体可以运行)