两轮面试题总结
1 前言
vivo是2020届秋招提前批第一批开始的企业,同时还有华为海思。小编有幸通过了网申,素质测评,在线笔试,然后两轮面试,成功拿到offer,现在把当时情况还原一波,希望对后续找工作的同学有所帮助~
面试岗位:机器学习算法工程师
base:北京
2 一轮面试题
面试是在一个五星级酒店,先在一个大厅等着被叫号,大概等了20分钟左右吧,到一个房间去参加一面。
2.1 活跃度预测下降如何定义y的
这个是属于我自己实习中的一个内容,面试官问这个问题说明比较看重实习的具体业务场景,解答如下:
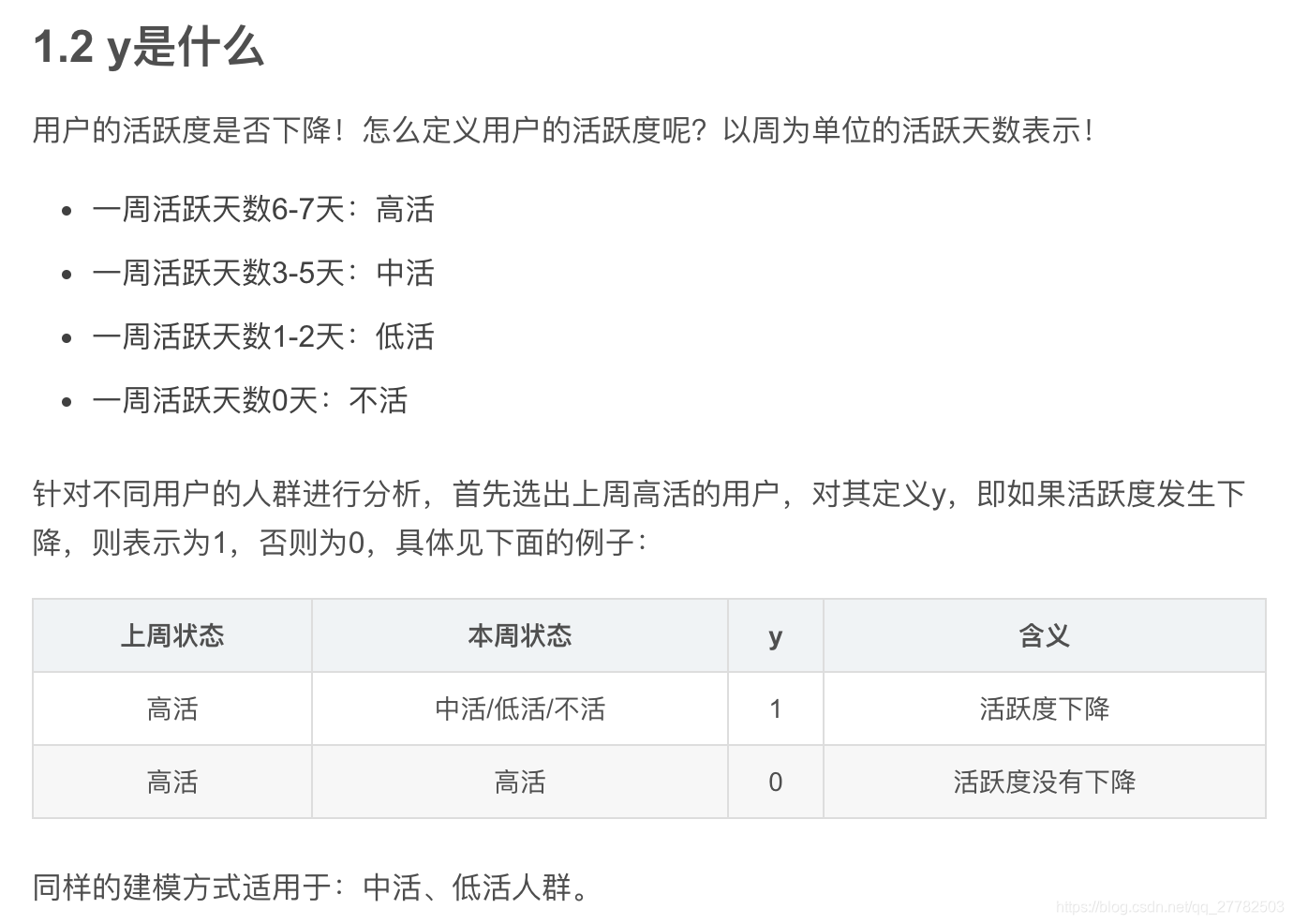
其实上述解答是我自己在面试之前就写好的一个博客中的部分内容,里面我把自己简历中有可能被面试官问的问题都列了出来,所以回答这个问题就得心应手了!
2.2 GBDT和Xgboost的区别
这个问题比较常规,我当时大概想到的点有以下几个:
- 导数信息的利用。GBDT是一阶导,XGBoost是二阶导
- 叶子节点分裂方式。XGBoost是level-wise,而LightGBM是Leaf-wise,容易过拟合,但可以设置深度来控制
- 目标函数是否有正则项。XGBoost是有的,一个是叶子节点数,一个是分数(面试官说权重,意思一样),而GBDT是没有的(面试官说其实叶子节点数,树的深度也可以算,但ok)
- XGBoost对于数据的特征值采用了预排序的方法,存放在一个block里面,然后可以在特征维度进行并行计算(计算增益),而GBDT没有。
- 基分类器:GBDT是采用CART,而XGBoost可以有多种选择。
我大概就想到了上述5点,然后面试官提醒了我一个,说,缺失值?嗨呀,然后我就想起来了!并补充了一点:
- GBDT对于缺失值是没有自动处理方式的,必须预先处理缺失值!嘿,这时候,脑子一转,顺便把缺失值的处理方式也说了啊!于是又说了三大类处理缺失值的方法:补数据;删数据;模型拟合的方法! 但是XGBoost可以实现自动补缺失值!无需提前处理!
说完,面试官好像还比较满意?然后就下一个问题了!
小结:其实这个问题,自己在之前的博客:- 机器学习 | 集成学习 中就有所总结哈,截图如下:

2.3 做了一个算法题。覆盖数组的问题
太难了!我佛了!
可以参考:
- https://blog.csdn.net/xia842655187/article/details/51944829
- https://blog.csdn.net/q547550831/article/details/51582082
- https://blog.csdn.net/qq_41289920/article/details/81020461
- https://blog.csdn.net/virus2014/article/details/51217026
- https://blog.csdn.net/nashviller/article/details/7383814
2.4 过拟合的原因是什么?
这个问题自己回答的不太好!只答出了太多自变量和决策树,总结一下,具体有下面几种原因:
- 训练集和测试集的分布不一样。
- 训练集噪音过大。样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系
- 建模时的“逻辑假设”到了模型应用时已经不能成立了。 任何预测模型都是在假设的基础上才可以搭建和应用的,常用的假设包括:假设历史数据可以推测未来,假设业务环节没有发生显著变化,假设建模数据与后来的应用数据是相似的,等等。如果上述假设违反了业务场景的话,根据这些假设搭建的模型当然是无法有效应用的。
- 参数太多、模型复杂度高
- 决策树模型。如果我们对于决策树的生长没有合理的限制和修剪的话,决策树的自由生长有可能每片叶子里只包含单纯的事件数据(event)或非事件数据(no event),可以想象,这种决策树当然可以完美匹配(拟合)训练数据,但是一旦应用到新的业务真实数据时,效果是一塌糊涂。
- 神经网络模型。
- 比如权值学习迭代次数足够多(Overtraining)。拟合了训练数据中的噪声和训练样例中没有代表性的特征。
- 或者是由于对样本数据,可能存在隐单元的表示不唯一,即产生的分类的决策面不唯一.随着学习的进行, BP算法使权值可能收敛过于复杂的决策面,并至极致.。
上面回答了过拟合的原因,那究竟什么是过拟合?以及过拟合又该如何去处理呢?
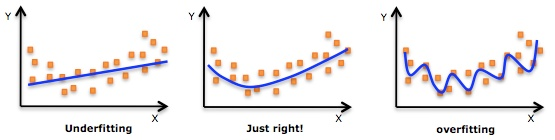
究竟什么是过拟合,知乎的回答花样百出,简直秀翻天!稍微总结一下:
一个比较常见的图片:
一个总结比较好的表格:
| 训练集上模型表现 | 测试集上模型表现 | 结论 |
|---|---|---|
| 不好 | 不好 | 欠拟合 |
| 好 | 不好 | 过拟合 |
| 好 | 好 | 完美-适度拟合 |
所以归纳一下:过拟合就是一个模型在训练集在表现很好,却在测试集上不能很好地拟合数据!即泛化性不好。
那解决过拟合的方法有哪些呢?
- 减小模型的复杂度。
- 增加训练集。训练集越多,模型过拟合的概率就越小。
- 正则化。对模型复杂度进行惩罚。L1范数使得模型留下更少的变量,L2范数会使得模型更多变量系数为0。【后面出一篇关于各种范数的推文!】
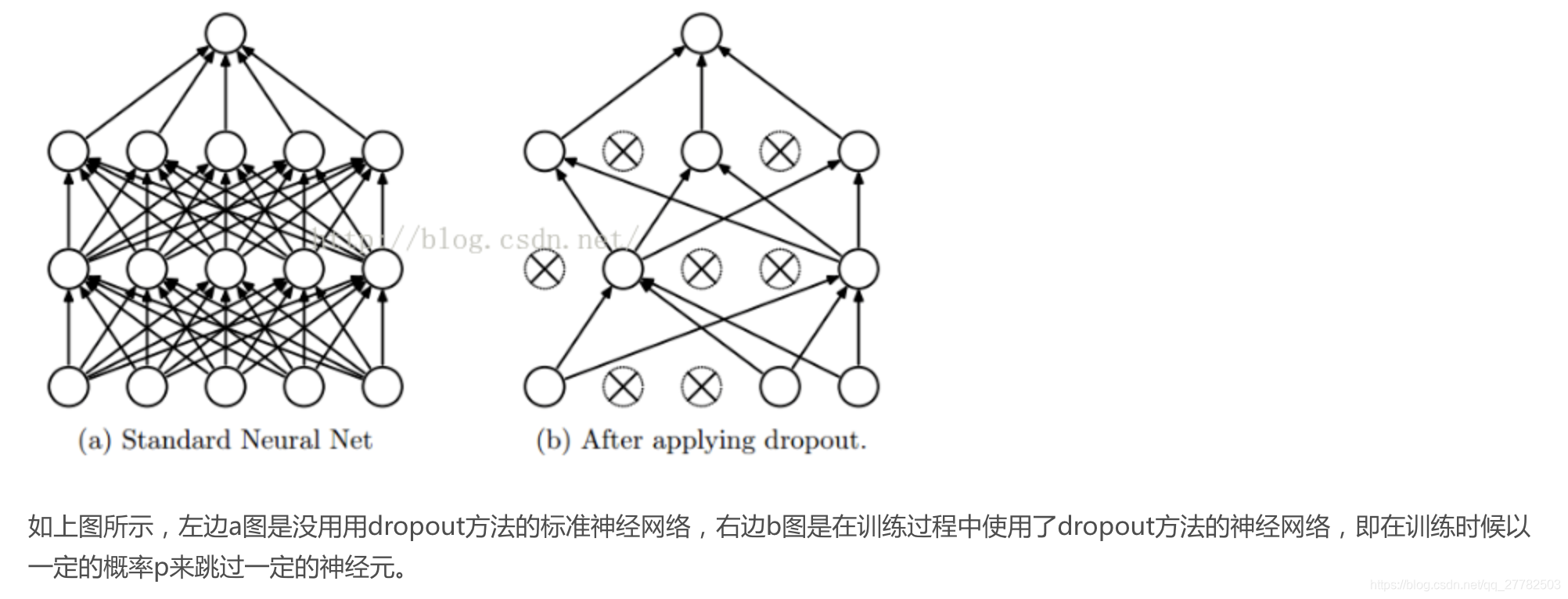
- dropout。这个方法在神经网络里面很常用。dropout方法是ImageNet中提出的一种方法,通俗一点讲就是dropout方法在训练的时候让神经元以一定的概率不工作。具体见下图:
- early stopping。一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。【后面写一篇文章讲early stopping 平安笔试也出现了这题】
- ensemble方法。集成学习算法也可以有效的减轻过拟合。Bagging通过平均多个模型的结果,来降低模型的方差。Boosting更多能减小偏差。
- 重新清洗数据。数据清洗从名字上也看的出就是把“脏”的“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
- 交叉验证 。详情见之前写的推文:机器学习 | 交叉验证
3 二轮面试题
一面结束后,通过后的小伙伴就会被叫到另一个房间去等待,叫号准备二面,之前还以为二面是更加厉害的技术大佬,但是HR面试哈!
- 介绍网易项目 大概几个人 持续多久 分工怎么样
- 职业规划
- 父母干嘛的?支持你在哪个城市?
- 为什么写博客?
- 网易新闻项目和风控项目更喜欢哪个
- 评价你自己的性格
- 你有什么兴趣爱好
- 为什么17-18之间gap了一年
上面其实是HR面试,结合知乎搜索的一些情况,小编尝试总结一下面试hr常问的问题。【单独开一个博客】
4 问面试官问题
- 介绍下vivo的业务场景
- 作为学生 之后想从事机器学习类工作有什么建议?面试官:找到自己的兴趣点!
5 小结
虽然拿到vivo秋招提前批的offer是一件很开心的事情,而且还是sp,虽然不是ssp但也还可以了,不过还是得继续努力,知道自己几斤几两哈,继续写博客看书练编程,秋招加油!