代码如下:


val conf = new SparkConf().setAppName("testMysqlToHiveJdbc") .setMaster("local") val spark = SparkSession.builder() .config(conf) .enableHiveSupport() .getOrCreate() ////定义Propertites,确定链接MySQL的参数 val mysqlProperties = new java.util.Properties() //MySQL的jdbc链接 val mysqlConnectionUrl = "jdbc:mysql://localhost:3306/rest" //定义检索语句,用于MySQL链接 val mysqlTableName = """(select t.*, case when id<4000000 and id >=0 then 1 when id<8000000 and id >=4000000 then 2 when id<12000000 and id >=8000000 then 3 when id<16000000 and id >=12000000 then 4 when id<20000000 and id >=16000000 then 5 else 6 end par from usppa_twitter_data t) tt""" // val mysqlTableName = "usppa_twitter_data" mysqlProperties.put("driver","com.mysql.jdbc.Driver") //确定driver mysqlProperties.put("user","root") //用户名 mysqlProperties.put("password","1234") //密码 mysqlProperties.put("fetchsize","10000") //批次取数数量 mysqlProperties.put("lowerBound","1") //确定分区 mysqlProperties.put("upperBound","7") //确定分区 mysqlProperties.put("numPartitions","6") //分区数量 mysqlProperties.put("partitionColumn","par") //分区字段 //读取数据 val re = spark.read.jdbc(mysqlConnectionUrl, mysqlTableName,mysqlProperties) //写入Hive表中 re.toDF().write.mode("overwrite").saveAsTable("testwarehouse.testtt")
代码中,lowerbound和upperbound有两种情况需要考虑。
1) 分区字段值可以穷举出来,如年份。
引用外网:https://www.percona.com/blog/2016/08/17/apache-spark-makes-slow-mysql-queries-10x-faster/
如下,lowerbound和upperbound会按照年份进行数据分区,这里的分区指的是并行的executors。
val jdbcDF = spark.read.format("jdbc").options(
| Map("url" -> "jdbc:mysql://localhost:3306/ontime?user=root&password=mysql",
| "dbtable" -> "ontime.ontime_sm",
| "fetchSize" -> "10000",
| "partitionColumn" -> "yeard", "lowerBound" -> "1988", "upperBound" -> "2015", "numPartitions" -> "48"
| )).load()
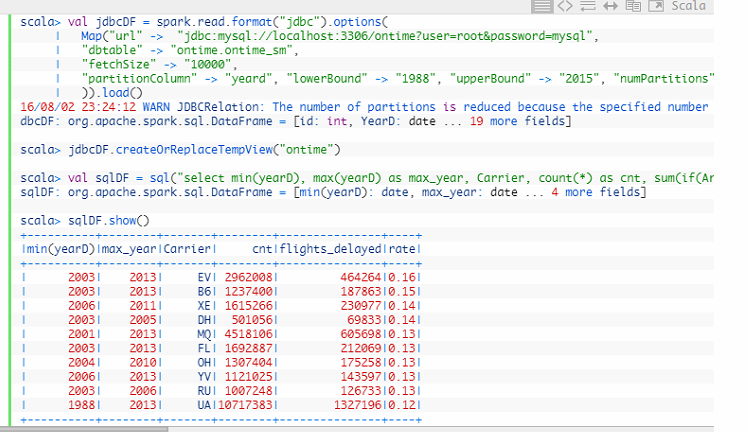
分区后,SQL会拆分成多个SQL:

2)分区字段不固定,如自动增长的ip,这时候lowerbound和upperbound在id数值之间,分区是一个估算值
容易产生问题,每个executor的数据分布不均,导致OOM,源码带看。
使用方式如下:

CREATE OR REPLACE TEMPORARY VIEW ontime USING org.apache.spark.sql.jdbc OPTIONS ( url "jdbc:mysql://127.0.0.1:3306/ontime?user=root&password=", dbtable "ontime.ontime", fetchSize "1000", partitionColumn "id", lowerBound "1", upperBound "162668934", numPartitions "128" );
68{N1WMVFA.png)