简介
LightGBM是微软开源的一套梯度boosting的框架,使用基于决策树的分布式的,高效的学习算法。是对GDBT的一种改进。
LightGBM在哪些地方进行了优化
- 基于Histogram的决策树算法
- 带深度限制的Leaf-wise的叶子生长策略
- 直方图做差加速
- 直接支持类别特征(Categorical Feature)
- Cache命中率优化
- 基于直方图的稀疏特征优化
- 多线程优化
基本原理
对GBDT来说,**对于每一个特征的每一个分裂点,都需要遍历全部数据来计算信息增益。**因此计算复杂度收到特征数量和数据量双重影响,造成处理大数据时十分耗时。解决这个问题的直接方法就是减少特征量和数据量,而且不影响精确度。有部分工作根据数据权重重采样来加速boosting的过程,
直方图算法-histogram
直方图算法(Histogram algorithm)的做法是把连续的浮点特征值离散化为k个整数(其实又是分桶的思想,而这些桶称为bin)比如
同时,将特征根据其所在的bin进行梯度累加。这样,遍历一次数据后,直方图累积了需要的梯度信息,然后可以直接根据直方图,寻找最优的切分点。


使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。
然后在计算上的代价也大幅降低,预排序算法每遍历一个特征值就需要计算一次分裂的增益,而直方图算法只需要计算k次(k可以认为是常数),时间复杂度从O(#data* #feature)优化到O(k * #features)。
直方图差加速
LightGBM另一个优化是Histogram(直方图)做差加速。一个容易观察到的现象:一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶。利用这个方法,LightGBM可以在构造一个叶子的直方图后,可以用非常微小的代价得到它兄弟叶子的直方图,在速度上可以提升一倍。

直方图算法小结
直方图算法的优点有
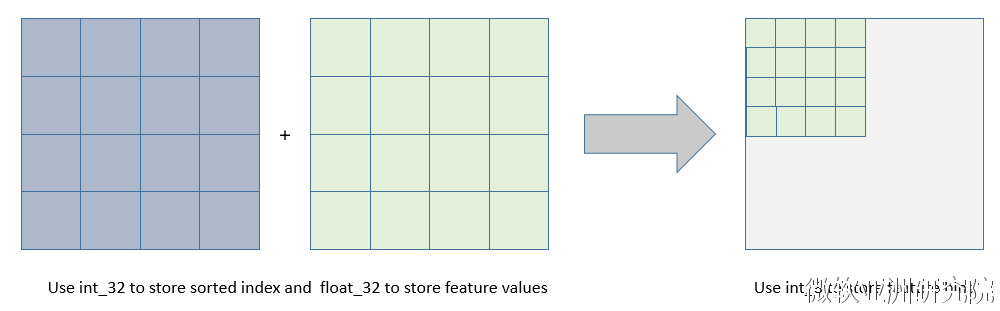
- 可以减少内存占用,比如离散为256个Bin时,只需要用8位整形就可以保存一个样本被映射为哪个Bin(这个bin可以说就是转换后的特征),对比预排序的Exact greedy算法来说(用int_32来存储索引+ 用float_32保存特征值),可以节省7/8的空间。
- 计算效率也得到提高,预排序的Exact greedy对每个特征都需要遍历一遍数据,并计算增益,复杂度为O(#feature×#data)。而直方图算法在建立完直方图后,只需要对每个特征遍历直方图即可,复杂度为O(#feature×#bins)。
- 提高缓存命中率,因为它访问梯度是连续的(直方图)。
- 此外,在数据并行的时候,直方图算法可以大幅降低通信代价。
当然也有不够精确的缺点:
Histogram算法并不是完美的。由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
带深度限制的Leaf-wise的叶子生长策略
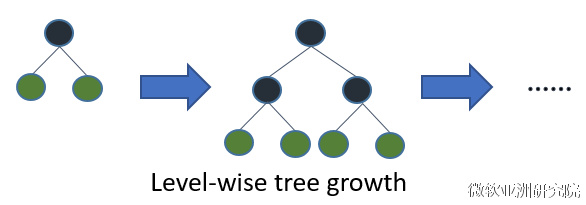
在Histogram算法之上,LightGBM进行进一步的优化。首先它抛弃了大多数GBDT工具使用的按层生长 (level-wise)
的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise)算法。**Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。**但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
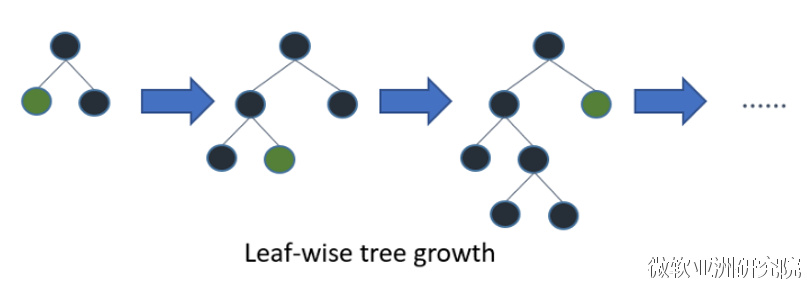
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
直方图算法改进
直方图算法仍有优化的空间,建立直方图的复杂度为O(#feature×#data),如果能降低特征数或者降低样本数,训练的时间会大大减少。以往的降低样本数的方法中,要么不能直接用在GBDT上,要么会损失精度。而降低特征数的直接想法是去除弱的特征(通常用PCA完成),然而,这些方法往往都假设特征是有冗余的,然而通常特征是精心设计的,去除它们中的任何一个可能会影响训练精度。因此LightGBM提出了GOSS算法和EFB算法。
Gradient-based One-Side Sampling(GOSS)
在AdaBoost中,权重向量w很好的反应了样本的重要性。而在GBDT中,则没有这样的直接权重来反应样本的重要程度。但是梯度是一个很好的指标,如果一个样本的梯度很小,说明该样本的训练误差很小,或者说该样本已经得到了很好的训练(well-trained)。
要减少样本数,一个直接的想法是抛弃那些梯度很小的样本,但是这样训练集的分布会被改变,可能会使得模型准确率下降。LightGBM提出 Gradient-based One-Side Sampling (GOSS)来解决这个问题。
GOSS的做法伪代码描述如下:

即:
- 根据梯度的绝对值将样本进行降序排序
- 选择前a×100%的样本,这些样本称为A
- 剩下的数据(1−a)×100% 的数据中,随机抽取b×100%的数据,这些样本称为B
- 在计算增益的时候,放大样本B中的梯度(1−a)/b 倍
- 关于g,在具体的实现中是一阶梯度和二阶梯度的乘积,见Github的实现( LightGBM/src/boosting/goss.hpp)
使用GOSS进行采样,使得训练算法更加的关注没有充分训练(under-trained)的样本,并且只会稍微的改变原有的数据分布。
原有的在特征j值为d处分数据带来的增益可以定义为:
其中:
- O为在决策树待分裂节点的训练集
- and
而使用GOSS后,增益定义为:
其中:
Exclusive Feature Bundling(EFB)
一个有高维特征空间的数据往往是稀疏的,而稀疏的特征空间中,许多特征是互斥的。所谓互斥就是他们从来不会同时具有非0值(一个典型的例子是进行One-hot编码后的类别特征)。
LightGBM利用这一点提出Exclusive Feature Bundling(EFB)算法来进行互斥特征的合并,从而减少特征的数目。做法是先确定哪些互斥的特征可以合并(可以合并的特征放在一起,称为bundle),然后将各个bundle合并为一个特征。
这样建立直方图的时间将从O(#feature × #data)变为O(#bundle×#data),而#bundle<<#feature,这样GBDT能在精度不损失的情况下进一步提高训练速度。
那么,问题来了:
- 如何判断哪里特征应该放在一个Bundle中?
- 如何将bundle中的特征合并为一个新的特征?
Greedy bundle
对于第1个问题,将特征划分为最少数量的互斥的bundle是NP问题(可以根据图着色问题来证明)。
因此,同样采用近似算法。我们可以构建一张图,图上的顶点代表特征,若两个特征不互斥,则在他们之间连一条边。
更进一步的,通常有少量的特征,它们之间并非完全的独立,但是绝大多数情况下,并不会同时取非0值。若构建Bundle的算法允许小的冲突,就能得到更少数的bundle,进一步提高效率。可以证明,随机的污染一部分特征则最多影响精度 , γ为最大的特征冲突率,也是在速度和精度之间达到平衡的有效手段。
因此,LightGBM的构建bundle算法描述如下(算法3):

即:
- 构造带权图G,边的权重代表两个feature之间冲突的数量
- 对特征按度降序排序
- 按顺序对排好序的特征进行遍历,对于当前特征i,查看是否能加入已有的bundle(冲突要小),若不行,则新建一个bundle
上述的算法复杂度为 ,当特征数很大的时候,仍然效率不高。
算法3可以进一步优化:不建立图,直接按特征的非0值的个数进行排序。(这也是一种贪心,非0值越多,越可能冲突)。
Merge Exclusive Features
现在来回答第2个问题,我们已经有了一个个的bundle,如何将bundle中的特征合并为一个新的特征呢?
回想起在直方图算法中,我们将连续的特征变为一个个离散的bins值,这是以特征为粒度的,即一个特征一张直方图。而合并后,一个很关键的点是合并后原本不同特征的值要有所体现,这样在新的特征中遍历直方图才能相当于遍历原来好几个直方图,从而找到切分点。
这可以通过对原始特征的值添加偏移来实现,从而将互斥的特征放在不同的bins中。例如,一个Bundle中有两个特征A和B,A∈[0,10), B∈[0,20),可以给特征B添加偏移量10,使得B的值域范围变为B∈[10,30),然后,A和B就可以合并成值域为[0,30]新特征。这就是Merge Exclusive Features(MEF)算法。
伪代码描述如下:

通过MEF算法,将许多互斥的稀疏特征转化为稠密的特征,降低了特征的数量,提高了建直方图的效率。
并行计算
XGBoost的并行主要集中在特征并行上,而LightGBM的并行策略分特征并行,数据并行以及投票并行。
参考资料
- Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. “LightGBM: A Highly Efficient Gradient Boosting Decision Tree”. In Advances in Neural Information Processing Systems (NIPS), pp. 3149-3157. 2017.
- 『我爱机器学习』集成学习(四)LightGBM
- 开源 | LightGBM:三天内收获GitHub 1000 星