一、感知机数学原理
感知机基于随机梯度下降法的最优化算法,是二分类线性模型,输入为实例的特征向量,输出为分类结果,属于判别模型。感知机旨在求出可以将数据进行线性划分的超平面(注意,只能划分线性可分的数据集,此时误分类次数k是有上界的,即感知机算法收敛,若数据集不可分,则算法不收敛)。
github代码地址,持续更新
感知机算法基本步骤
输入:训练数据集( , ), 为特征向量, 为类别,学习率a
输出:参数w,b,感知机模型 f(x)=sign(wx+b)
1、选取初值 ,
2、在训练数据集随机选取一个数据点( , )
3、如果 ( + )小于等于0
更新参数 w= +a ,
b= +a
4、转到2,直至数据集没有误分类点
(1)感知机超平面函数
f(x)=sign(x*w+b)
其中sign当x大于等于0的时候为+1,小于0时为-1.
(2)感知机损失函数
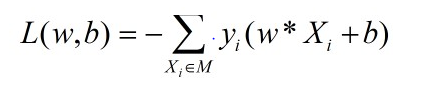
这里选取的是误分类点到超平面的总距离,采用随机梯度下降法优化损失函数,即将损失函数分别对w,b求导,求得其梯度,并进行参数更新,直至损失函数最小(非负)
二、sklearn实现(能实现线性可分数据集,多分类)
在sklearn函数make_classification下默认生成二分类的样本,主要参数
#n_samples:生成样本的数量
#n_features=2:生成样本的特征数
from sklearn.datasets import make_classification
from sklearn.linear_model import Perceptron
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
x,y = make_classification(n_samples=1200, n_features=2,n_redundant=0,n_informative=1,n_clusters_per_class=1)
x_data_train = x[:800,:]##x为特征
x_data_test = x[800:,:]
y_data_train = y[:800]##y为类别
y_data_test = y[800:]
#定义感知机
clf = Perceptron(fit_intercept=False,n_iter=50,shuffle=False,eta0=0.1,random_state=0)
#使用训练数据进行训练
clf.fit(x_data_train,y_data_train)
print(clf.coef_)#返回超平面参数w,b
y_pred=clf.predict(x_data_test)
#评估模型,采用score和classification_report,accuracy_score方法
acc = clf.score(x_data_test,y_data_test)
print(acc)
print (accuracy_score(y_data_test, y_pred))
classify_report = classification_report(y_data_test, y_pred)
print('classify_report : \n', classify_report)
感知机模型主要参数
n_iter :可以理解成梯度下降中迭代的次数
tol:float或None,若float,迭代将在(loss> previous_loss - tol)时停止。
eta0:float,学习率,(0,1)
感知机返回参数
coef_ : 权重[w1,w2,…]
intercept_ :常数b
备注
1、感知机的超平面函数与初值选取,数据点选取顺序有关
2、感知机存在对偶形式
3、对于数据集线性不可分的情况,需要对超平面进行约束,可采用svm(支持向量机)来划分超平面