1,支持向量机概念简介
分类作为数据挖掘领域中一项非常重要的任务,它的目的是学会一个分类函数或分类模型(或者叫做分类器),而支持向量机本身便是一种监督式学习的方法,它广泛的应用于统计分类以及回归分析中。
支持向量机(Support Vector Machine,SVM)是90年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。SVM(support vector machine)简单的说是一个分类器,并且是二类分类器。 Vector:通俗说就是点,或是数据。 Machine:也就是classifier,也就是分类器。
SVM要解决的问题:
(1)找到决策边界并决定最好的决策边界

(2)对于很难分类的特征数据进行分类(核函数变换)
(3)计算复杂度
2,支持向量机算法推导
2.1 决策边界
选出来离雷区最远的边界线(雷区就是边界上的点,要Large Margin),范围越大,分类效果越好,算法的泛化能力越强。

2.2 距离的计算

平面代表边界,w是平面的法向量。计算点x到平面的距离,x’和x’‘是平面上的点,可以将垂线的长度转化为xx’在法向量方向上的投影,然后消去x’。
2.3 数据标签定义
数据集:(X1,Y1)(X2,Y2)… (Xn,Yn);X为样本,Y为标签,n为样本数(注意:Y为样本的类别: 当X为正例,Y>0时候 Y = +1 当X为负例,Y<0时候 Y = -1)
决策方程:
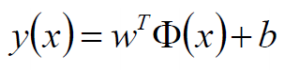
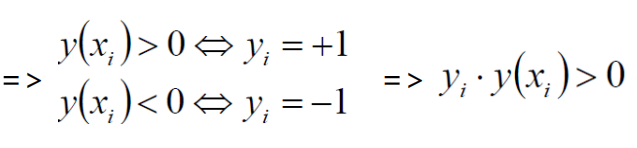
2.4 优化的目标
将点到直线的距离化简得(去绝对值,y的绝对值为1):
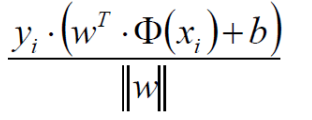
优化的目标:找到一个条线(w和b),使得离该线最近(min)的点能够最远(max):
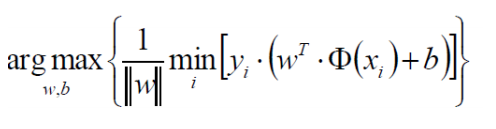
放缩变换:对于决策方程(w,b)可以通过放缩(等比例放大或缩小)使得其结果值|Y|>= 1:
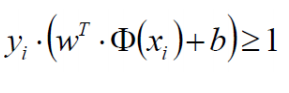
之前我们认为恒大于0,现在严格了些。在上述约束条件下,现在目标函数只需要考虑下式:
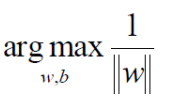
将求解极大值问题转换成极小值问题(引入1/2,以方便求导计算):
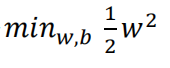
并且w需满足以下约束条件:
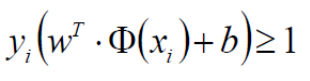
2.5 目标函数的求解
2.5.1 拉格朗日乘子法
对于带约束的优化问题有:
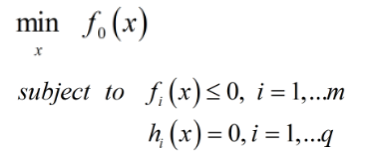
原式转换:
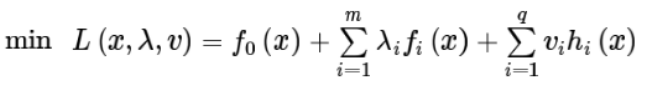
将目标函数代入得:
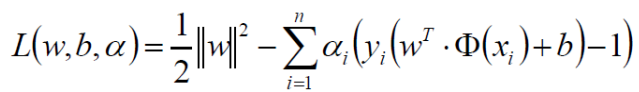
2.6 SVM求解
分别对w和b求偏导,分别得到两个条件(由于对偶性质,KKT):
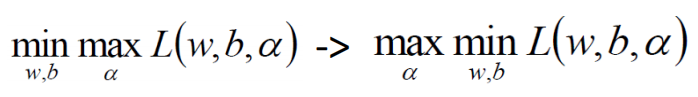
对w求偏导:
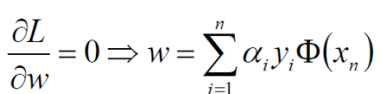
对b求偏导:
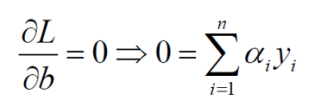
带入原式:
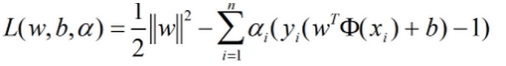
 继续对ɑ求极大值:
继续对ɑ求极大值:

极大值转换成求极小值:
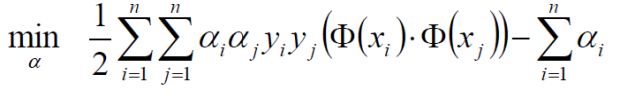
其中约束条件为:
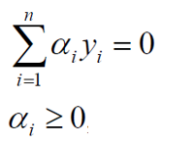
3,SVM求解实例
数据:3个点,其中正例 X1(3,3) ,X2(4,3) ,负例X3(1,1)
求解:
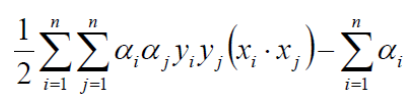
约束条件:
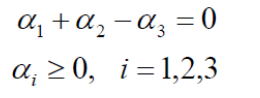
将数据代入上式:
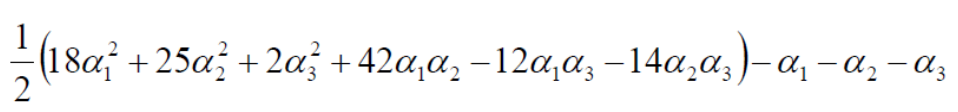 由于:
由于:
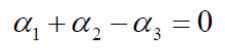
化简可得:
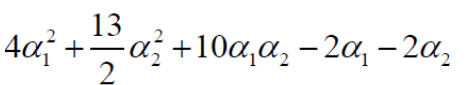
分别对ɑ1和ɑ2求偏导,令偏导等于0可得:
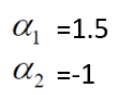
ɑ2并不满足约束条件(ɑi>=0),所以解应在边界上(令ɑ1=0或ɑ2=0)。
 将ɑ结果带入求解:
将ɑ结果带入求解:
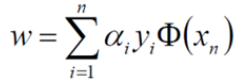
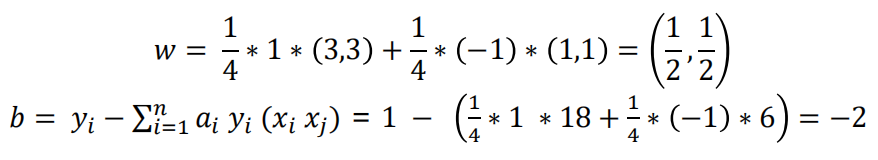 平面方程为:
平面方程为:
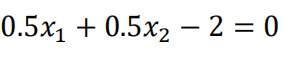
在图像显示为:

当ɑi=0时,样本点xi对决策边界的构成无影响。即边界上的样本点(ɑi不为0,支持向量)构成了最终结果。
支持向量:真正发挥作用的数据点,ɑ值不为0的点(只要支持向量不变,样本点的数量多少不会影响最终结果)。

4,,软间隔
软间隔(soft-margin):有时候数据中有一些噪音点,如果考虑它们得到的决策边界就不太好了。之前的方法要求要把两类点完全分得开,这个要求有点过于严格了,我们引入松弛因子解决上述问题。

松弛因子的表达式:
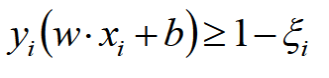
新的目标函数:
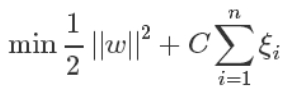
其中,C是我们需要指定的一个参数。当C趋近于很大(需要很小的松弛因子)时:意味着分类严格不能有错误;当C趋近于很小时:意味着可以有更大的错误容忍。
软间隔算法的求解:
 5,低维不可分问题
5,低维不可分问题
5.1 核变换:既然低维的时候不可分,可找到一种变换的方法将它映射到高维。
 5.2 低维不可分问题实例
5.2 低维不可分问题实例
假设有两个数据x=(x1,x2,x3);y=(y1,y2,y3),此时在三维空间很难对其线性划分。通过对特征进行一系列的组合操作将原始数据映射到九维空间,f(x)=(x1x1,x1x2,x1x3,x2x1,x2x2,x2x3,x3x1,x3x2,x3x3),由于需要计算内积,所以新的数据在九维空间,需要计算<f(x),f(y)>的内积,需要花费(n^2)。
例如令x=(1,2,3),y=(4,5,6),则f(x)=(1,2,3,2,4,6,3,6,9),f(y)=(16,20,24,20,25,36,24,30,36)故<f(x),f(y)>=16+40+72+40+100+180+72+180+324=1024。如果将维数扩大到很大的一个数,计算量将会很大。但是可以发现:K(x,y)=(4+10+18)^ 2 =1024 。 即K(x,y)= (<x,y>)^2=<f(x),f(y)>
使用核函数的好处在于,可以在低维空间去完成高维空间样本内积的计算(本质上并没有对原始数据进行映射只是假设是这样的,实际还是在低维空间中做计算(先内积再映射),只是计算的结果和对应高维空间的计算结果相同)
5.3 高斯核函数(接近无限维的变换)
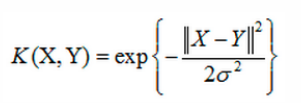
线性支持向量机(线性核函数)和非线性支持向量机(高斯核函数):
