大部分文章这篇博客介绍的很详细:
https://blog.csdn.net/aBlueMouse/article/details/78710553
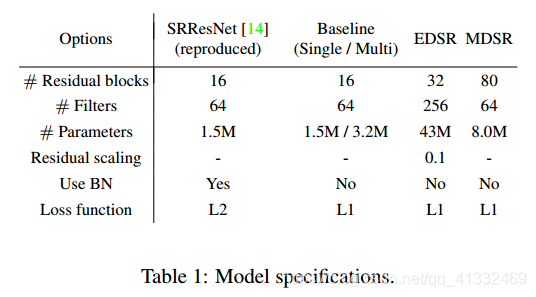
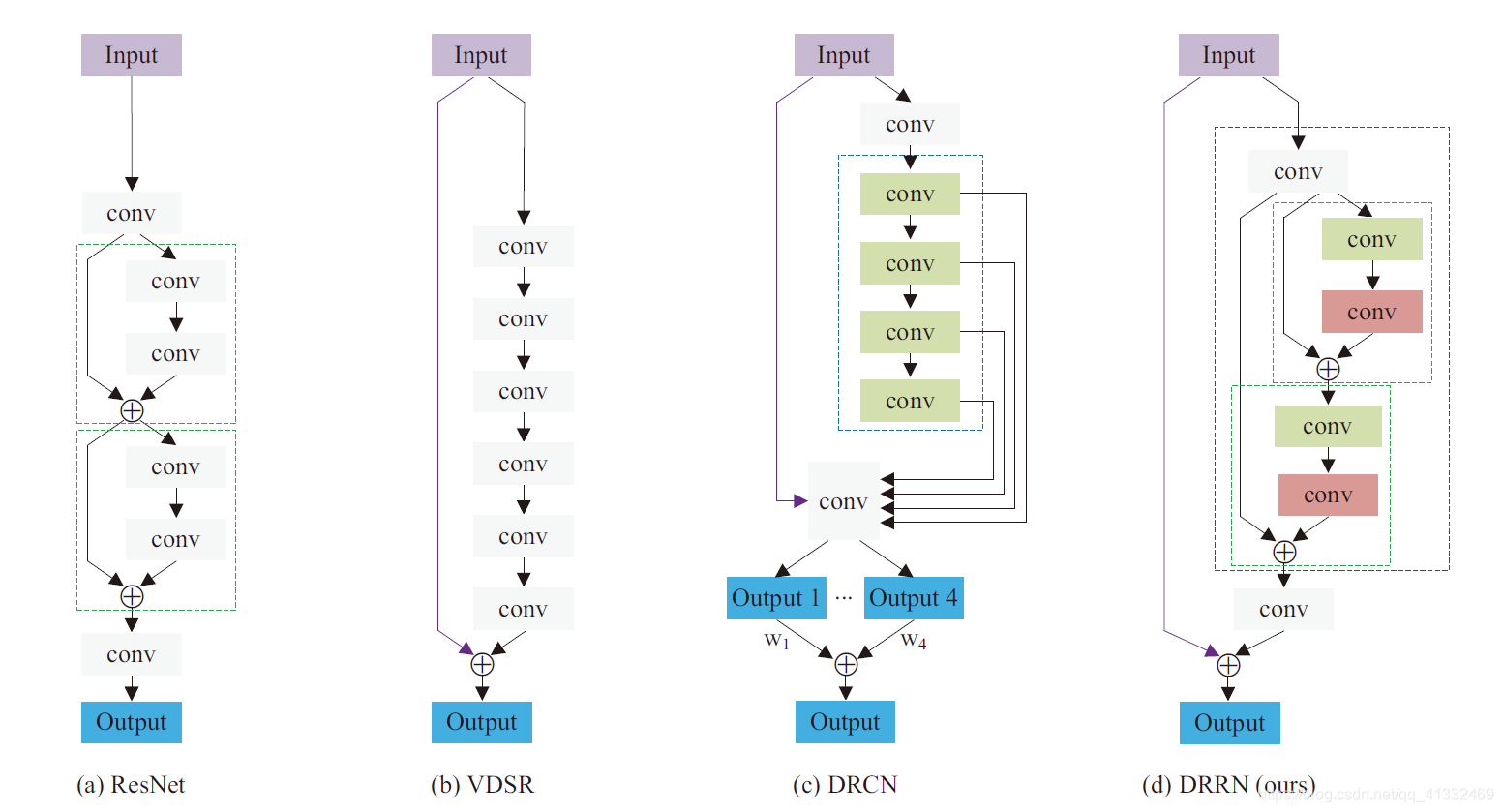
1、SRCNN(第一次将深度学习应用于SR,先插值放大,再三次卷积)
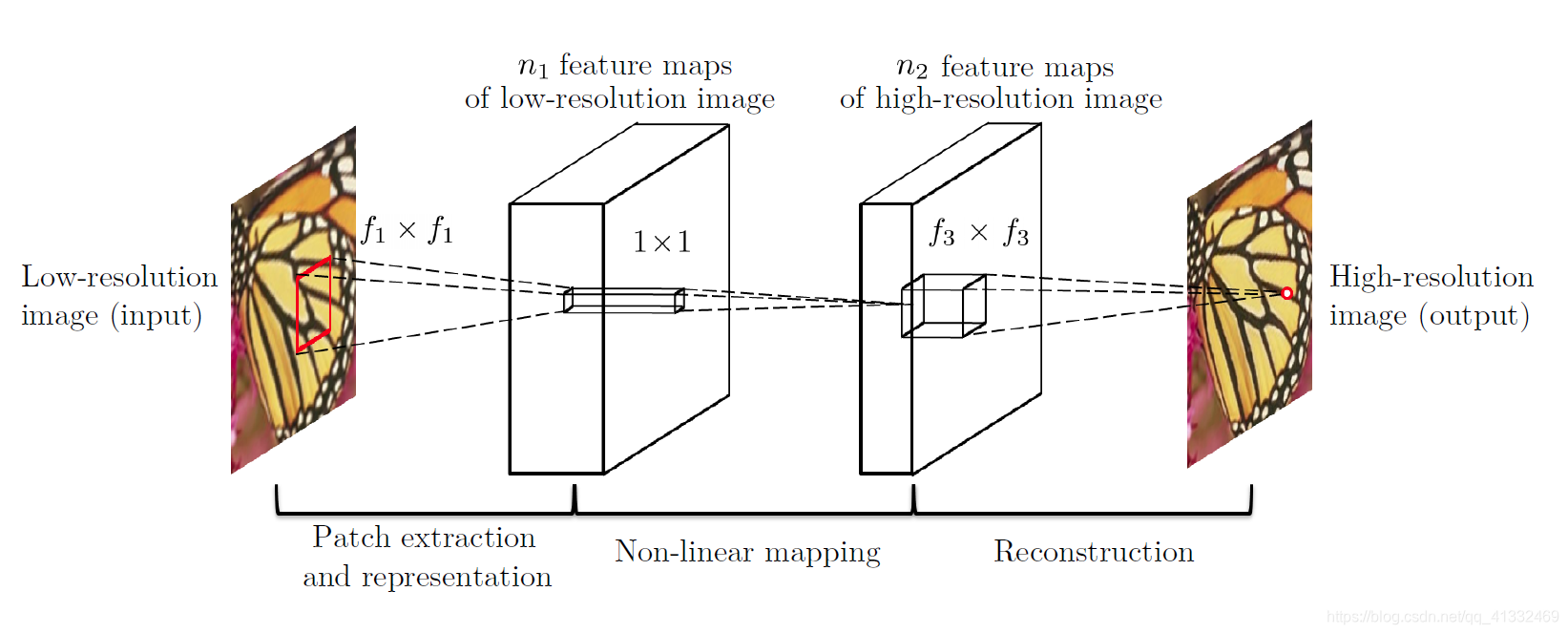
2、FSRCNN(对SRCNN提速,不需要插值放大,反卷积+小的卷积核)
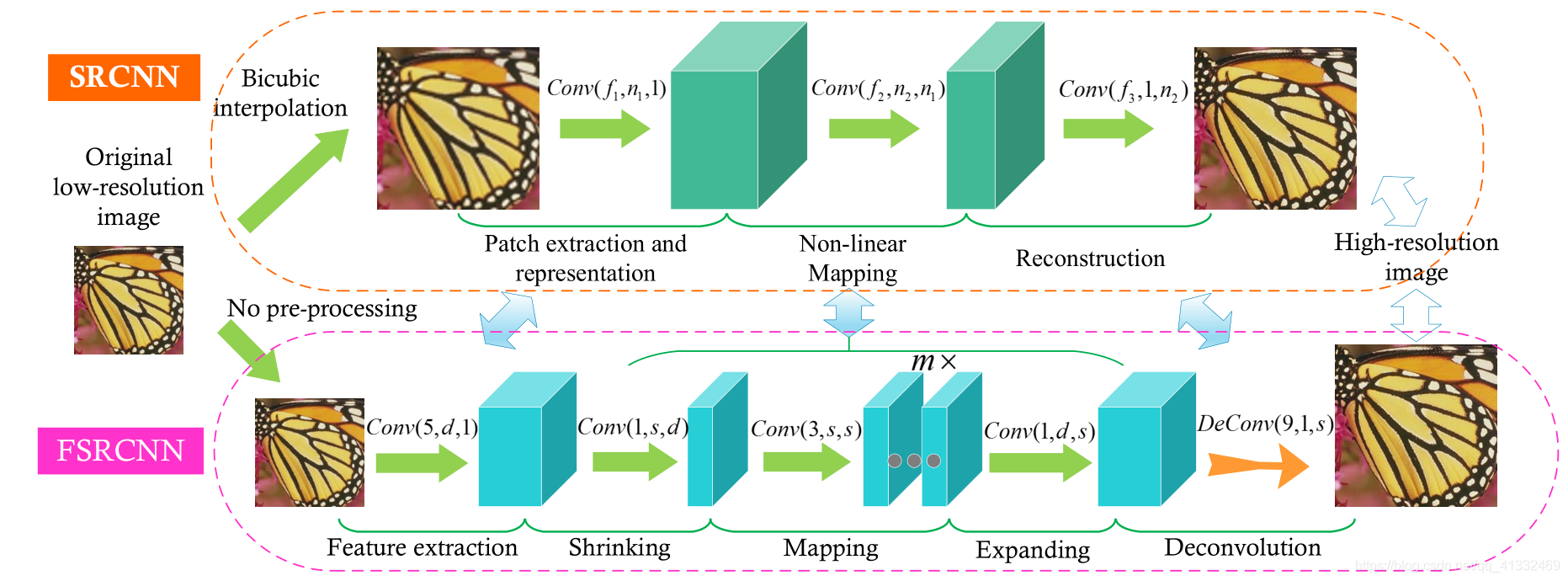
3、ESPCN(亚像素卷积层)
这篇论文采用了一种新的上采样方式,后边好几篇性能比较好的论文都是采用这种方法上采样,效果应该会比反卷积效果好
Resnet问世,借鉴renet的思想,开始学习HR和LR的残差部分,取得了不错的效果,后续优秀网络都有用到残差的思想。
4、VDSR(全局残差学习)
5、DRCN(全局残差学习+单权重的递归学习+多目标优化)
6、DRRN(多路径模式的局部残差学习+全局残差学习+多权重的递归学习)
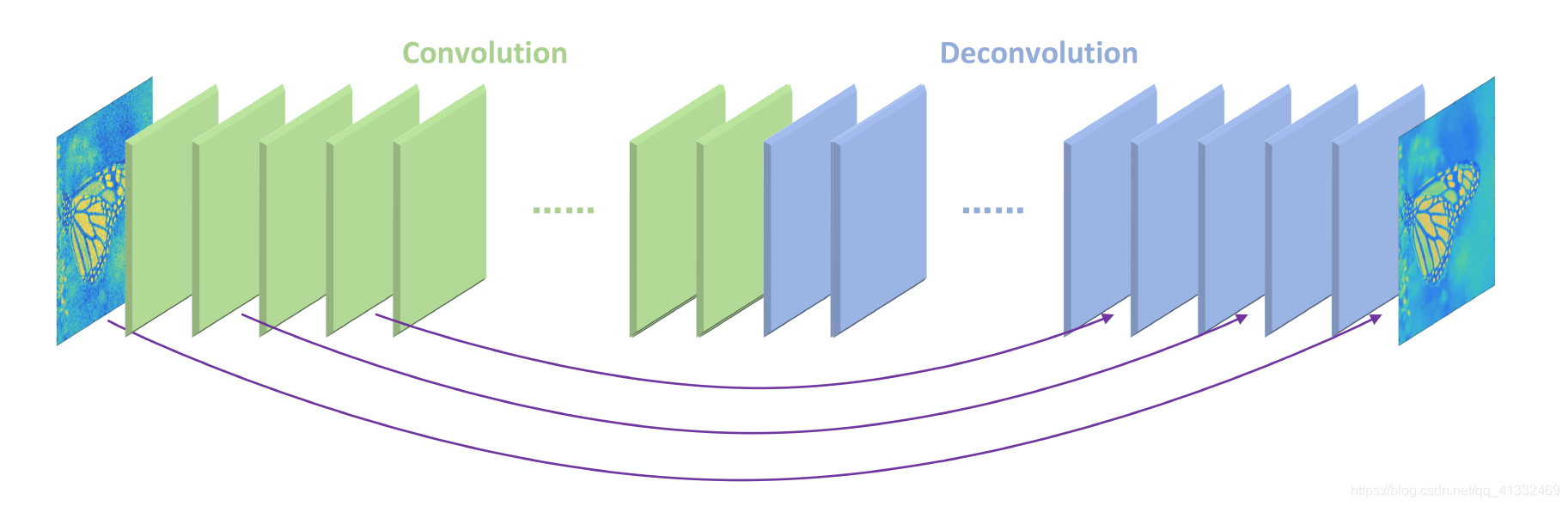
7、RED(对称的卷积层-反卷积层)
8、LapSRN
论文中作者先总结了之前的方法存在有三点问题。
(1)是有的方法在输入图像进网络前,需要使用预先定义好的上采样操作(例如bicubic)来获得目标的空间尺寸,这样
的操作增加了额外的计算开销,同时也会导致可见的重建伪影。而有的方法使用了亚像素卷积层或者反卷积层这样的操作来替换预先定义好的上采样操作,这些方法的网络结构又相对比较简单,性能较差,并不能学好低分辨率图像到高分辨率图像复杂的映射。(2)是在训练网络时使用 l_{2} 型损失函数时,不可避免地会产生模糊的预测,恢复出的高分辨率图片往往会太过于平滑。
(3)是在重建高分辨率图像时,如果只用一次上采样的操作,在获得大倍数(8倍以上)的上采样因子时就会比较困难。而且在不同的应用时,需要训练不同上采样倍数的模型。针对这三点问题,作者提出了LapSRN,网络结构如下图所示。
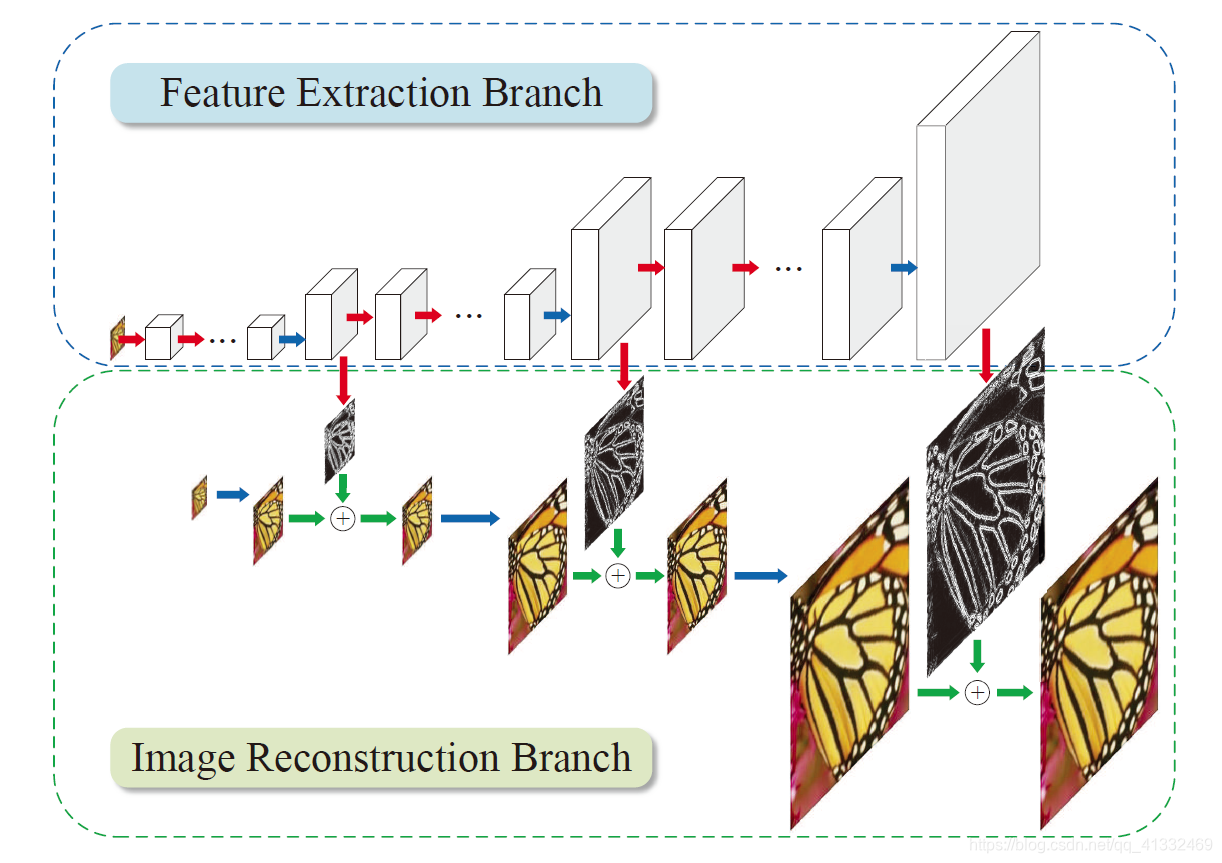
提出了拉普拉斯金字塔超分辨率网络(LapSRN)来逐步重建高分辨率图像的子带残差。在每一级金字塔中,模型将低分辨率特征图作为输入,预测高频残差,并使用反卷积进行上采样到更精细的水平。该方法不需要双三次插值作为预处理步骤,因此大大降低了计算复杂度。使用强大的Charbonnier损失函数对深度监督的LapSRN进行训练,并实现高质量的重建。
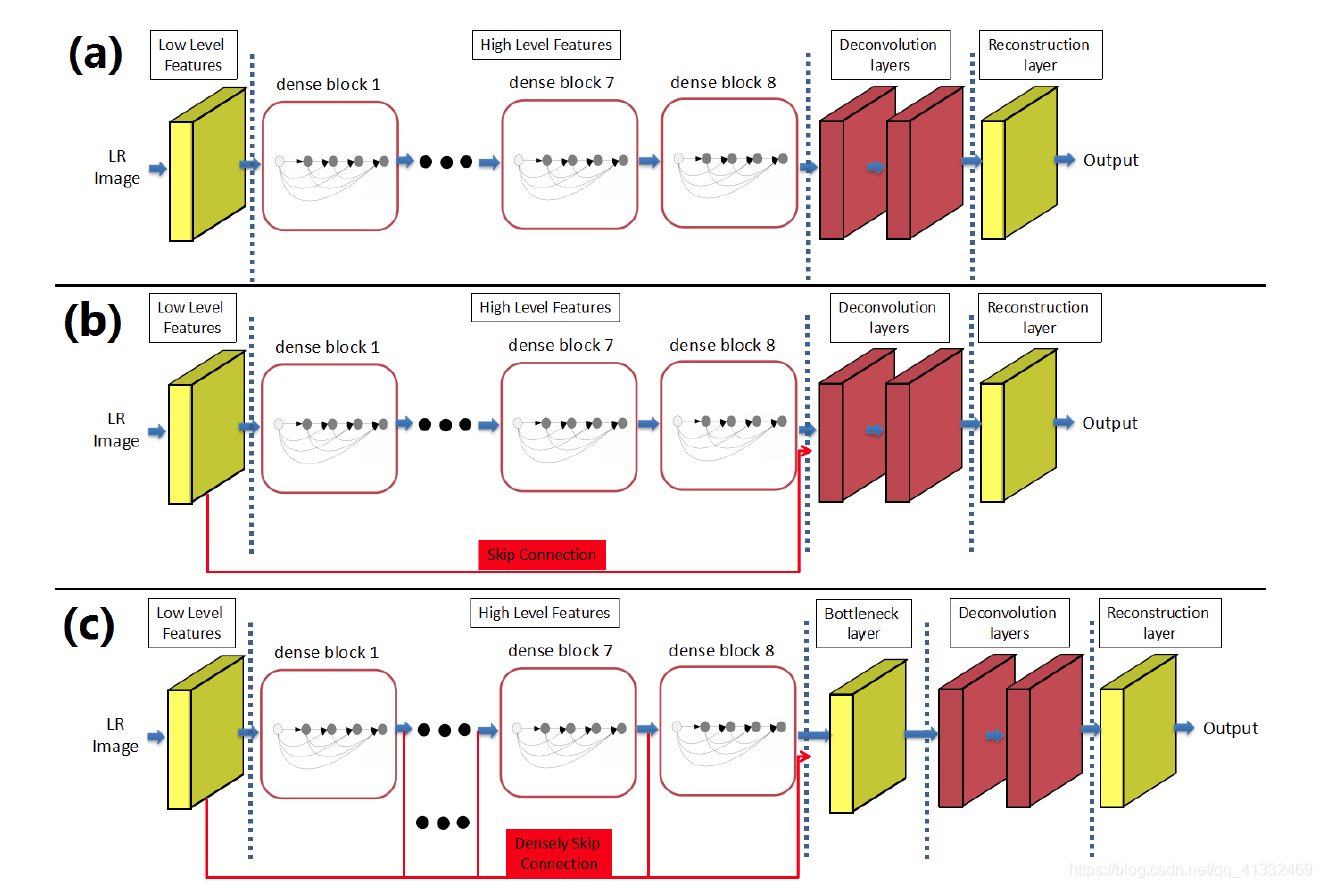
9、SRDenseNet(引入dense block)
10、SRGAN(SRResNet)(引入GAN和感知损失)
11、EDSR(2017年冠军模型,改进SRResNet)
以下对两篇有代表性的文章做详细介绍
SRGAN
问题:当我们超分辨率在大尺度因子时,如何恢复更精细的纹理细节?
在这篇文章中,将生成对抗网络(Generative Adversarial Network, GAN)用在了解决超分辨率问题上。文章提到,训练网络时用均方差作为损失函数,虽然能够获得很高的峰值信噪比(psnr),但是恢复出来的图像通常会丢失高频细节(因为它针对一个一个像素优化,而如高层纹理细节的能力非常有限),导致图像向更加平滑的方向发展(产生边缘伪影),使人不能有好的视觉感受。
SRGAN利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感。感知损失是利用卷积神经网络提取出的特征,通过比较生成图片经过卷积神经网络后的特征和目标图片经过卷积神经网络后的特征的差别,使生成图片和目标图片在语义和风格上更相似。
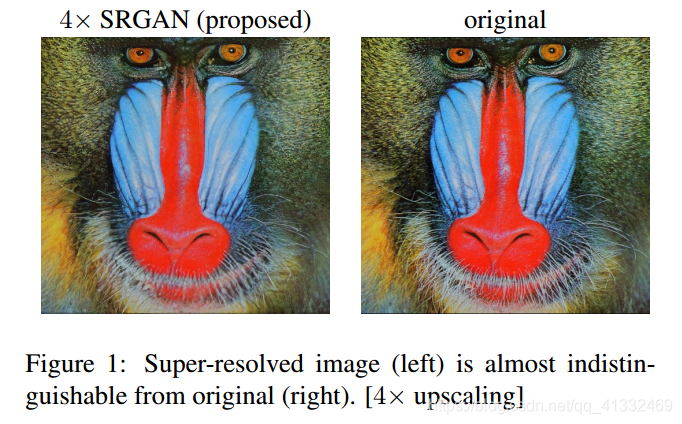
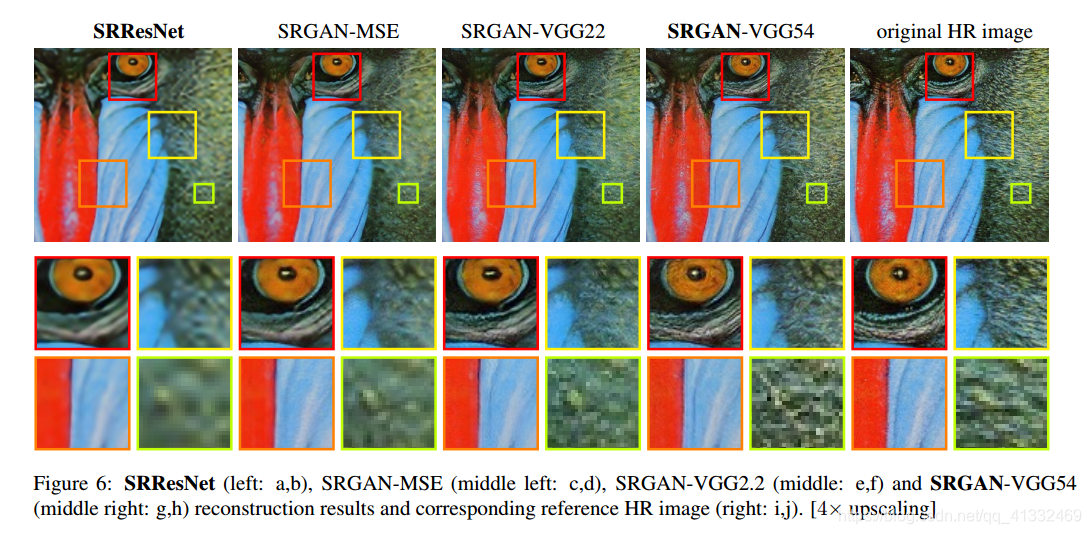
 如图可以看出来:
如图可以看出来:
采用MSE损失的SRResNet的psnr很高,图像更平滑,但自然细节纹理表现很差;
SRGAN虽然psnr不高 ,但相对来说,细节纹理表现要好一点。
GAN网络结构
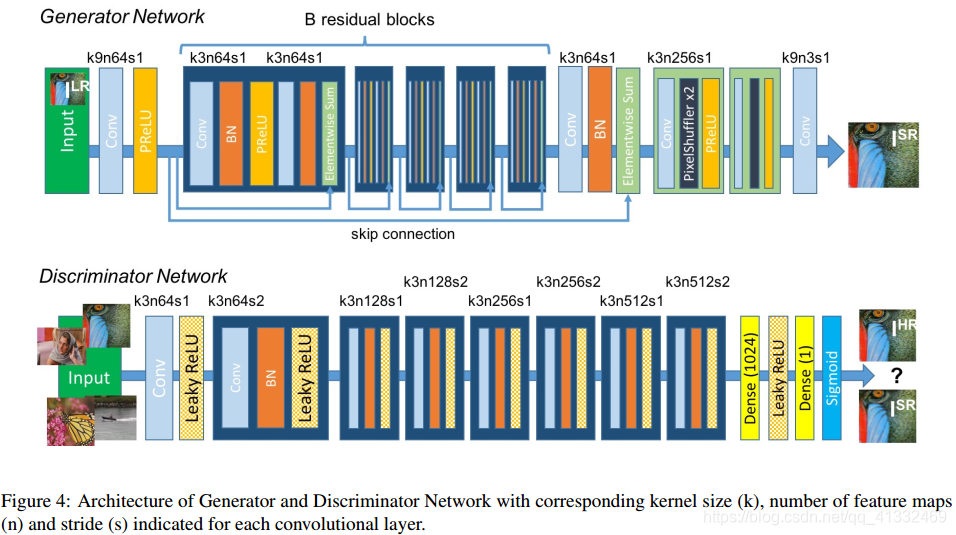 Generator network的作用是尽可能的产生一张高分辨率的图片,在生成网络部分(SRResNet)部分包含多个残差块,每个残差块中包含两个3×3的卷积层,卷积层后接批规范化层(batch normalization, BN)和PReLU作为激活函数,两个2×亚像素卷积层(sub-pixel convolution layers)被用来增大特征尺寸。
Generator network的作用是尽可能的产生一张高分辨率的图片,在生成网络部分(SRResNet)部分包含多个残差块,每个残差块中包含两个3×3的卷积层,卷积层后接批规范化层(batch normalization, BN)和PReLU作为激活函数,两个2×亚像素卷积层(sub-pixel convolution layers)被用来增大特征尺寸。
Discriminator network的作用是判断Generator生成的图片是高分辨率图片的概率,在判别网络部分包含8个卷积层,随着网络层数加深,特征个数不断增加,特征尺寸不断减小,选取激活函数为LeakyReLU,最终通过两个全连接层和最终的sigmoid激活函数得到预测为自然图像的概率。
损失函数
整体损失函数:
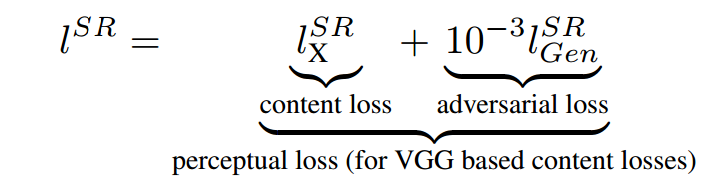
内容损失
(1)均方损失(MSE)
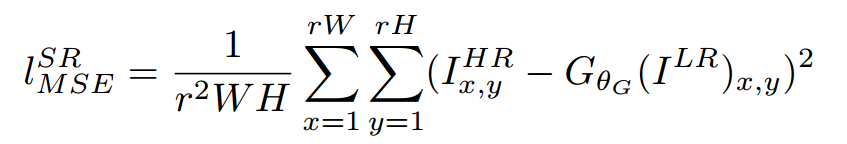 (2)基于训练好的以ReLU为激活函数的VGG模型的损失函数
(2)基于训练好的以ReLU为激活函数的VGG模型的损失函数
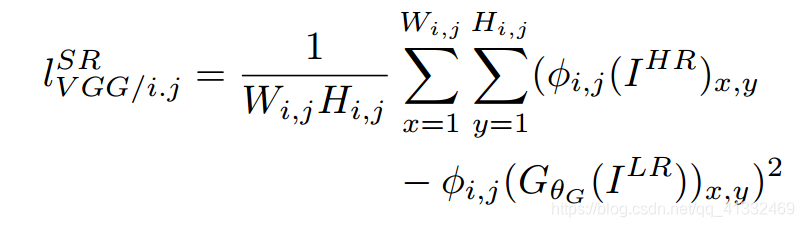
对抗损失
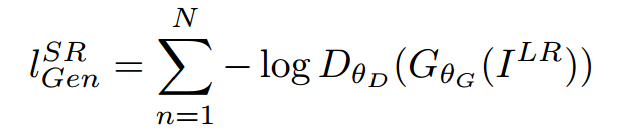
MSE loss与VGG loss对比
EDSR
(1)EDSR最有意义的模型性能提升是去除掉了SRResNet多余的模块,从而可以扩大模型的尺寸来提升结果质量。
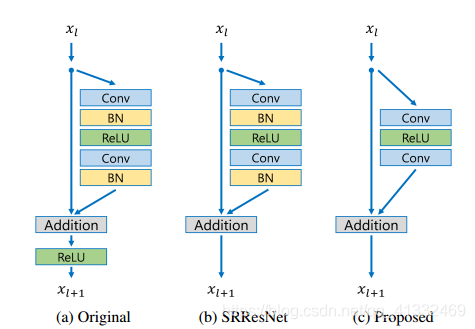
EDSR在结构上与SRResNet相比,就是把批规范化处理(batch normalization, BN)操作给去掉了。文章中说,原始的ResNet最一开始是被提出来解决高层的计算机视觉问题,比如分类和检测,直接把ResNet的结构应用到像超分辨率这样的低层计算机视觉问题,显然不是最优的。由于批规范化层消耗了与它前面的卷积层相同大小的内存,在去掉这一步操作后,相同的计算资源下,EDSR就可以堆叠更多的网络层或者使每层提取更多的特征,从而得到更好的性能表现。EDSR用L1范数样式的损失函数来优化网络模型。在训练时先训练低倍数的上采样模型,接着用训练低倍数上采样模型得到的参数来初始化高倍数的上采样模型,这样能减少高倍数上采样模型的训练时间,同时训练结果也更好。
EDSR总体结构:
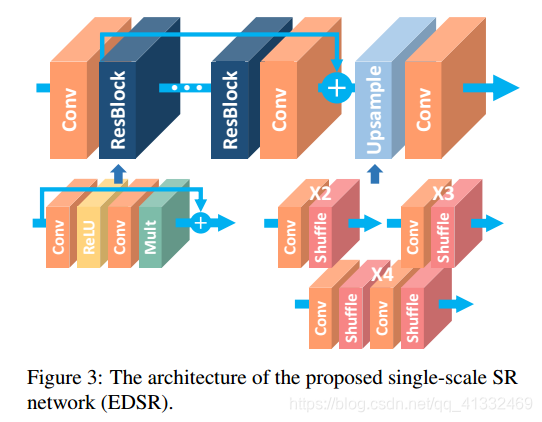
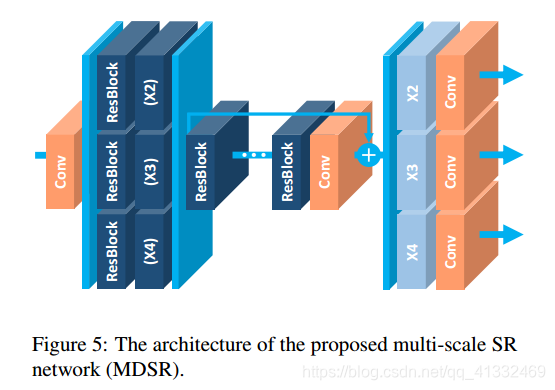
(2)提出了一种新的多尺度超分辨率系统(MDSR)和训练方法,可以在一个模型中重建不同尺度因子的高分辨率图像。
MDSR的中间部分还是和EDSR一样,只是在网络前面添加了不同的预训练好的模型来减少不同倍数的输入图片的差异。在网络最后,不同倍数上采样的结构平行排列来获得不同倍数的输出结果。
结果