- 学习webflux前需要学习三个基础:
- 函数式编程和lambda表达式
- Stream流编程
- Reactive stream 响应式流
- 接下来进入学习
一、函数式编程和lambda表达式
1. 什么是函数式编程
函数式编程是一种相对于命令式编程的一种编程范式,它不是一种具体的技术,而是一种如何搭建应用程序的方法论
2. 为什么要使用函数式编程
* 能让我们以一种更加优雅的方式进行编程
* 函数式编程与命令式编程相比
1)不同点:
关注点不同,命令式编程我们关注的是怎么样做,而函数式编程关注的是做什么。
2)优点:
可以使代码更加的简短,更加的好读。
3. lambda表达式初接触
具体看一个例子,求数组中的最大值,如果数据量太大,想要处理更高效,jdk8以前,只能自己创建线程池,自己拆分,而jdk8以后只需要加上parallel(),意思就是告诉它我要多线程的处理该数据,以此可以看到他的魅力
public class MinDemo {
public static void main(String[] args) {
int[] arr = {15,24,12,451,156};
int min = Integer.MAX_VALUE;
for (int a :
arr) {
if (a < min) {
min = a;
}
}
System.out.println(min);
//jdk8 lambda,parallel()多线程处理
int min2 = IntStream.of(arr).parallel().min().getAsInt();
System.out.println(min2);
}
4. 当然还有很多其他的特性,这里只简单介绍一下
-
jdk8接口新特性
- 接口里只有一个要实现的方法,单一责任制
- 新增默认方法
-
函数接口
- 只需要知道输入输出的类型
- 支持链式操作
-
方法引用
- 静态方法引用
- 非静态方法引用
- 构造方法引用
-
级联表达式和柯里化
- 级联表达式是返回函数的函数
- 柯里化把多个参数的函数转换为只有一个参数的函数
-
变量引用
- 引用外边的变量必须是final类型
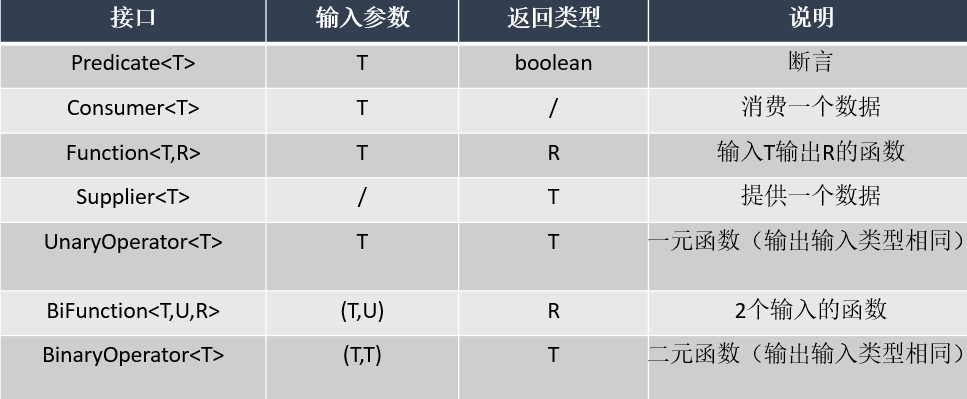
5. 以下是函数式编程常用的接口
二、 Stream流编程
1. 是什么,不是什么
是一个高级的迭代器,不是一个数据结构、不是一个集合、不会存放数据、关注的是怎么把数据高效处理
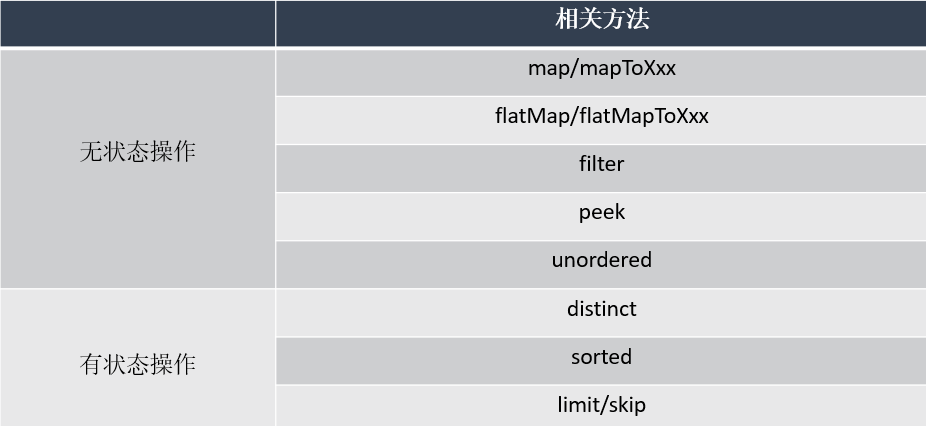
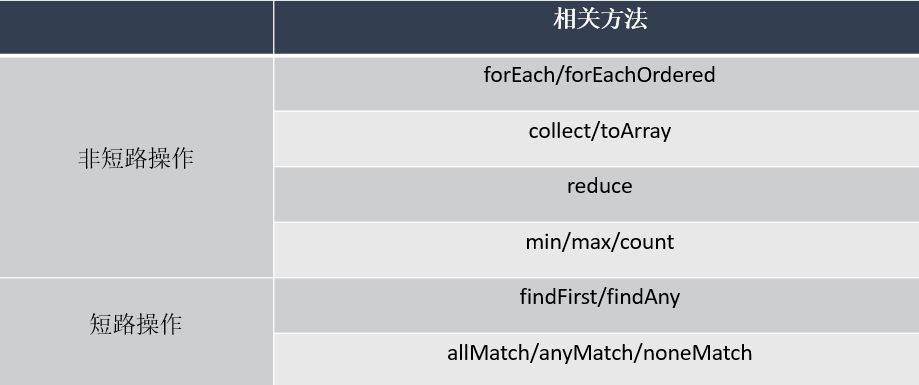
2. 创建/中间操作/终止操作
1) 创建

代码演示
List<String> list = new ArrayList<>();
// 从集合创建
list.stream();
list.parallelStream();
// 从数组创建
Arrays.stream(new int[] { 2, 3, 5 });
// 创建数字流
IntStream.of(1, 2, 3);
IntStream.rangeClosed(1, 10);
// 使用random创建一个无限流
new Random().ints().limit(10);
Random random = new Random();
// 自己产生流
Stream.generate(() -> random.nextInt()).limit(20);
2) 中间操作
String str = "my name is AlgerFan";
System.out.println("--------------filter------------");
// 把每个单词的长度调用出来
Stream.of(str.split(" ")).filter(s -> s.length() > 2)
.map(String::length).forEach(System.out::println);
System.out.println("--------------flatMap------------");
// flatMap A->B属性(是个集合), 最终得到所有的A元素里面的所有B属性集合
// intStream/longStream 并不是Stream的子类, 所以要进行装箱 boxed
Stream.of(str.split(" ")).flatMap(s -> s.chars().boxed())
.forEach(i -> System.out.println((char) i.intValue()));
System.out.println("--------------peek------------");
// peek 用于debug. 是个中间操作,和 forEach 是终止操作
Stream.of(str.split(" ")).peek(System.out::println)
.forEach(System.out::println);
System.out.println("--------------limit------------");
// limit 使用, 主要用于无限流
new Random().ints().filter(i -> i > 100 && i < 1000).limit(5)
.forEach(System.out::println);
3) 终止操作
String str = "my name is AlgerFan";
System.out.println("-------并行流parallel--------");
// 使用并行流
str.chars().parallel().forEach(i -> System.out.print((char) i));
System.out.println();
// 使用 forEachOrdered 保证顺序
str.chars().parallel().forEachOrdered(i -> System.out.print((char) i));
System.out.println();
System.out.println("-------collect收集到list--------");
// 收集到list
List<String> list = Stream.of(str.split(" "))
.collect(Collectors.toList());
System.out.println(list);
System.out.println("-------使用 reduce 拼接字符串--------");
// 使用 reduce 拼接字符串
Optional<String> letters = Stream.of(str.split(" "))
.reduce((s1, s2) -> s1 + "|" + s2);
System.out.println(letters.orElse(""));
System.out.println("-------带初始化值的reduce--------");
// 带初始化值的reduce
String reduce = Stream.of(str.split(" ")).reduce("",
(s1, s2) -> s1 + "|" + s2);
System.out.println(reduce);
System.out.println("-------计算所有单词总长度--------");
// 计算所有单词总长度
Integer length = Stream.of(str.split(" ")).map(s -> s.length())
.reduce(0, (s1, s2) -> s1 + s2);
System.out.println(length);
System.out.println("-------max 的使用--------");
// max 的使用
Optional<String> max = Stream.of(str.split(" "))
.max((s1, s2) -> s1.length() - s2.length());
System.out.println(max.get());
System.out.println("-------使用 findFirst 短路操作--------");
// 使用 findFirst 短路操作
OptionalInt findFirst = new Random().ints().findFirst();
System.out.println(findFirst.getAsInt());
- 并行流
以上已经接触了parallel()并行流,能够多线程的处理数据 - 收集器
示例代码:
// 测试数据
List<Student> students = Arrays.asList(
new Student("小明", 10, Gender.MALE, Grade.ONE),
new Student("大明", 9, Gender.MALE, Grade.THREE),
new Student("小白", 8, Gender.FEMALE, Grade.TWO),
new Student("小黑", 13, Gender.FEMALE, Grade.FOUR),
new Student("小红", 7, Gender.FEMALE, Grade.THREE),
new Student("小黄", 13, Gender.MALE, Grade.ONE),
new Student("小青", 13, Gender.FEMALE, Grade.THREE),
new Student("小紫", 9, Gender.FEMALE, Grade.TWO),
new Student("小王", 6, Gender.MALE, Grade.ONE),
new Student("小李", 6, Gender.MALE, Grade.ONE),
new Student("小马", 14, Gender.FEMALE, Grade.FOUR),
new Student("小刘", 13, Gender.MALE, Grade.FOUR));
// 得到所有学生的年龄列表
// s -> s.getAge() --> Student::getAge , 不会多生成一个类似 lambda$0这样的函数
Set<Integer> ages = students.stream().map(Student::getAge)
.collect(Collectors.toCollection(TreeSet::new));
System.out.println("所有学生的年龄:" + ages);
// 统计汇总信息
IntSummaryStatistics agesSummaryStatistics = students.stream()
.collect(Collectors.summarizingInt(Student::getAge));
System.out.println("年龄汇总信息:" + agesSummaryStatistics);
// 分块
Map<Boolean, List<Student>> genders = students.stream().collect(
Collectors.partitioningBy(s -> s.getGender() == Gender.MALE));
System.out.println("男女学生列表:" + genders);
// 分组
Map<Grade, List<Student>> grades = students.stream()
.collect(Collectors.groupingBy(Student::getGrade));
System.out.println("学生班级列表:" + grades);
// 得到所有班级学生的个数
Map<Grade, Long> gradesCount = students.stream().collect(Collectors
.groupingBy(Student::getGrade, Collectors.counting()));
System.out.println("班级学生个数列表:" + gradesCount);
测试结果
所有学生的年龄:[6, 7, 8, 9, 10, 13, 14]
年龄汇总信息:IntSummaryStatistics{count=12, sum=121, min=6, average=10.083333, max=14}
男女学生列表:{false=[[name=小白, age=8, gender=FEMALE, grade=TWO], [name=小黑, age=13, gender=FEMALE, grade=FOUR], [name=小红, age=7, gender=FEMALE, grade=THREE], [name=小青, age=13, gender=FEMALE, grade=THREE], [name=小紫, age=9, gender=FEMALE, grade=TWO], [name=小马, age=14, gender=FEMALE, grade=FOUR]], true=[[name=小明, age=10, gender=MALE, grade=ONE], [name=大明, age=9, gender=MALE, grade=THREE], [name=小黄, age=13, gender=MALE, grade=ONE], [name=小王, age=6, gender=MALE, grade=ONE], [name=小李, age=6, gender=MALE, grade=ONE], [name=小刘, age=13, gender=MALE, grade=FOUR]]}
学生班级列表:{FOUR=[[name=小黑, age=13, gender=FEMALE, grade=FOUR], [name=小马, age=14, gender=FEMALE, grade=FOUR], [name=小刘, age=13, gender=MALE, grade=FOUR]], ONE=[[name=小明, age=10, gender=MALE, grade=ONE], [name=小黄, age=13, gender=MALE, grade=ONE], [name=小王, age=6, gender=MALE, grade=ONE], [name=小李, age=6, gender=MALE, grade=ONE]], THREE=[[name=大明, age=9, gender=MALE, grade=THREE], [name=小红, age=7, gender=FEMALE, grade=THREE], [name=小青, age=13, gender=FEMALE, grade=THREE]], TWO=[[name=小白, age=8, gender=FEMALE, grade=TWO], [name=小紫, age=9, gender=FEMALE, grade=TWO]]}
班级学生个数列表:{FOUR=3, ONE=4, THREE=3, TWO=2}
- 运行机制
演示一个测试代码
Random random = new Random();
// 随机产生数据
Stream<Integer> stream = Stream.generate(random::nextInt)
// 产生300个 ( 无限流需要短路操作. )
.limit(300)
// 第1个无状态操作,print(s)执行耗时操作5s
.peek(s -> print("peek: " + s))
// 第2个无状态操作
.filter(s -> {
print("filter: " + s);
return s > 1000000;
})
// 有状态操作
/*.sorted((i1, i2) -> {
print("排序: " + i1 + ", " + i2);
return i1.compareTo(i2);
})*/
// 又一个无状态操作
.peek(s -> {
print("peek2: " + s);
});
// 终止操作
stream.count();
分析以上代码,发现Stream创建了一个256长度的数组
- 所有操作是链式调用, 一个元素只迭代一次
- 每一个中间操作返回一个新的流. 流里面有一个属性sourceStage
指向同一个 地方,就是Head - Head->nextStage->nextStage->… -> null
- 有状态操作会把无状态操作阶段,单独处理
- 并行环境下, 有状态的中间操作不一定能并行操作.
- parallel/ sequetial 这2个操作也是中间操作(也是返回stream)
但是他们不创建流, 他们只修改 Head的并行标志
三、Reactive stream 响应式流
- Reactive stream是jdk9新特性,提供了一套API,就是一种订阅发布者模式
- 被压,背压是指在异步场景中,发布者发送事件速度远快于订阅者的处理速度的情况下,一种告诉上游的发布者降低发送速度的策略,简而言之,背压就是一种流速控制的策略。
举个例子:假设以前是没有水龙头的,只能自来水厂主动的往用户输送水,但是不知道用户需要多少水,有了Reactive stream,就相当于有了水龙头,用户可以主动的请求用水,而自来水厂也知道了用户的需求
示例代码(需要jdk9以上版本的支持)
import java.util.concurrent.Flow.Subscriber;
import java.util.concurrent.Flow.Subscription;
import java.util.concurrent.SubmissionPublisher;
public class FlowDemo {
public static void main(String[] args) throws Exception {
// 1. 定义发布者, 发布的数据类型是 Integer
// 直接使用jdk自带的SubmissionPublisher, 它实现了 Publisher 接口
SubmissionPublisher<Integer> publiser = new SubmissionPublisher<Integer>();
// 2. 定义订阅者
Subscriber<Integer> subscriber = new Subscriber<Integer>() {
private Subscription subscription;
@Override
public void onSubscribe(Subscription subscription) {
// 保存订阅关系, 需要用它来给发布者响应
this.subscription = subscription;
// 请求一个数据
this.subscription.request(1);
}
@Override
public void onNext(Integer item) {
// 接受到一个数据, 处理
System.out.println("接受到数据: " + item);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 处理完调用request再请求一个数据
this.subscription.request(1);
// 或者 已经达到了目标, 调用cancel告诉发布者不再接受数据了
// this.subscription.cancel();
}
@Override
public void onError(Throwable throwable) {
// 出现了异常(例如处理数据的时候产生了异常)
throwable.printStackTrace();
// 我们可以告诉发布者, 后面不接受数据了
this.subscription.cancel();
}
@Override
public void onComplete() {
// 全部数据处理完了(发布者关闭了)
System.out.println("处理完了!");
}
};
// 3. 发布者和订阅者 建立订阅关系
publiser.subscribe(subscriber);
// 4. 生产数据, 并发布
// 这里忽略数据生产过程
for (int i = 0; i < 1000; i++) {
System.out.println("生成数据:" + i);
// submit是个block方法
publiser.submit(i);
}
publiser.submit(111);
publiser.submit(222);
publiser.submit(333);
// 5. 结束后 关闭发布者
// 正式环境 应该放 finally 或者使用 try-resouce 确保关闭
publiser.close();
// 主线程延迟停止, 否则数据没有消费就退出
Thread.currentThread().join(1000);
}
}
四、Webflux响应式编程
先来一张图,这是spring文档的一张截图,介绍了spring如今的两种开发模式,MVC和webflux两种开发模式,可见webflux的重要性

1. 初识SpringWebFlux
webflux 是spring5推出的一种响应式Web框架,它是一种非阻塞的开发模式,可以在一个线程里处理多个请求(非阻塞),运行在netty环境,也可以可以运行在servlet3.1之后的容器,支持异步servlet, 可以支持更高的并发量
2. 异步servlet
- 我们知道同步servlet阻塞了Tomcat容器的线程,当一个网络请求到我们的Tomcat容器之后,容器会给每个请求启动一个线程去处理,线程里面会调用一个servlet去处理,当使用同步servlet时,业务代码花多长时间,你的线程就要等待多长时间,这就是堵塞(同步和异步是服务器后台才有异步这个概念,对于浏览器来说所有的请求都是异步,前台都要花费业务逻辑时间)
- 异步servlet的主要作用是它不会堵塞Tomcat容器的servlet线程,它可以把一些耗时的操作放在一个独立的线程池,那么我们的servlet就可以立马返回,处理下一个请求,以此就可以达到高并发。
通过代码比较一下同步servlet与异步servlet
同步servlet
@WebServlet(urlPatterns = "/SyncServlet")
public class SyncServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public SyncServlet() {
super();
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
long t1 = System.currentTimeMillis();
// 执行业务代码
doSomeThing(request, response);
System.out.println("sync use:" + (System.currentTimeMillis() - t1));
}
private void doSomeThing(HttpServletRequest request,
HttpServletResponse response) throws IOException {
// 模拟耗时操作
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
response.getWriter().append("done");
}
}
异步servlet
@WebServlet(asyncSupported = true, urlPatterns = { "/AsyncServlet" })
public class AsyncServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
public AsyncServlet() {
super();
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
long t1 = System.currentTimeMillis();
// 开启异步
AsyncContext asyncContext = request.startAsync();
// 执行业务代码,放入一个线程池里
CompletableFuture.runAsync(() -> doSomeThing(asyncContext,
asyncContext.getRequest(), asyncContext.getResponse()));
System.out.println("async use:" + (System.currentTimeMillis() - t1));
}
private void doSomeThing(AsyncContext asyncContext,
ServletRequest servletRequest, ServletResponse servletResponse) {
// 模拟耗时操作
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
servletResponse.getWriter().append("done");
} catch (IOException e) {
e.printStackTrace();
}
// 业务代码处理完毕, 通知结束
asyncContext.complete();
}
}
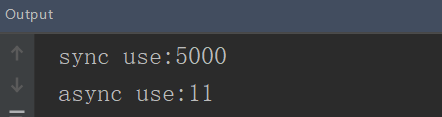
- 通过以上两段代码控制台的打印结果可以看出,异步servlet把耗时操作放在一个独立的线程池,那么我们的servlet就可以立马返回,处理下一个请求。
3. CRUD完整示例
-
通过下图可以看出MVC和wenflux的区别

-
以下通过一个例子了解一下webflux开发
- 实体类
@Document(collection = "user")
@Data
public class User {
@Id
private String id;
@NotBlank
private String name;
@Range(min=10, max=100)
private int age;
}
- Controller层
@RestController
@RequestMapping("/user")
public class UserController {
private final UserRepository repository;
public UserController(UserRepository repository) {
this.repository = repository;
}
/**
* 以数组形式一次性返回数据
*/
@GetMapping("/")
public Flux<User> getAll() {
return repository.findAll();
}
/**
* 以SSE形式多次返回数据
*/
@GetMapping(value = "/stream/all", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<User> streamGetAll() {
return repository.findAll();
}
/**
* 新增数据
*/
@PostMapping("/")
public Mono<User> createUser(@Valid @RequestBody User user) {
// spring data jpa 里面, 新增和修改都是save. 有id是修改, id为空是新增
// 根据实际情况是否置空id
user.setId(null);
CheckUtil.checkName(user.getName());
return this.repository.save(user);
}
/**
* 根据id删除用户 存在的时候返回200, 不存在返回404
*/
@DeleteMapping("/{id}")
public Mono<ResponseEntity<Void>> deleteUser(
@PathVariable("id") String id) {
// deletebyID 没有返回值, 不能判断数据是否存在
// this.repository.deleteById(id)
return this.repository.findById(id)
// 当你要操作数据, 并返回一个Mono 这个时候使用flatMap
// 如果不操作数据, 只是转换数据, 使用map
.flatMap(user -> this.repository.delete(user).then(
Mono.just(new ResponseEntity<Void>(HttpStatus.OK))))
.defaultIfEmpty(new ResponseEntity<>(HttpStatus.NOT_FOUND));
}
/**
* 修改数据 存在的时候返回200 和修改后的数据, 不存在的时候返回404
*/
@PutMapping("/{id}")
public Mono<ResponseEntity<User>> updateUser(@PathVariable("id") String id,
@Valid @RequestBody User user) {
CheckUtil.checkName(user.getName());
return this.repository.findById(id)
// flatMap 操作数据
.flatMap(u -> {
u.setAge(user.getAge());
u.setName(user.getName());
return this.repository.save(u);
})
// map: 转换数据
.map(u -> new ResponseEntity<User>(u, HttpStatus.OK))
.defaultIfEmpty(new ResponseEntity<>(HttpStatus.NOT_FOUND));
}
/**
* 根据ID查找用户 存在返回用户信息, 不存在返回404
*/
@GetMapping("/{id}")
public Mono<ResponseEntity<User>> findUserById(
@PathVariable("id") String id) {
return this.repository.findById(id)
.map(u -> new ResponseEntity<User>(u, HttpStatus.OK))
.defaultIfEmpty(new ResponseEntity<>(HttpStatus.NOT_FOUND));
}
/**
* 根据年龄查找用户
*/
@GetMapping("/age/{start}/{end}")
public Flux<User> findByAge(@PathVariable("start") int start,
@PathVariable("end") int end) {
return this.repository.findByAgeBetween(start, end);
}
/**
* 根据年龄查找用户
*/
@GetMapping(value = "/stream/age/{start}/{end}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<User> streamFindByAge(@PathVariable("start") int start,
@PathVariable("end") int end) {
return this.repository.findByAgeBetween(start, end);
}
/**
* 得到20-30用户
*/
@GetMapping("/old")
public Flux<User> oldUser() {
return this.repository.oldUser();
}
/**
* 得到20-30用户
*/
@GetMapping(value = "/stream/old", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<User> streamOldUser() {
return this.repository.oldUser();
}
}
- Repository层
@Repository
public interface UserRepository extends ReactiveMongoRepository<User, String> {
/**
* 根据年龄查找用户
*/
Flux<User> findByAgeBetween(int start, int end);
@Query("{'age':{ '$gte': 20, '$lte' : 30}}")
Flux<User> oldUser();
}
- 以上代码没有进行校验,当然没有校验的代码是不能用的,校验代码我就不放了,想了解的GitHub上有完整代码。