首先我们要先知道我们的主机名
我配置的是四台虚拟机
一台NameNode,一台SencodryNameNode,SencodryNameNode节点上同时有着
DataNode ,还有两台DataNode 。
在linux上我们一般使用vi 来执行操作
也可以使用vim 使用vim需要下载 yum -y install vim*
vim使用比较舒服一点 ,所以我一般都是使用vim
我配置的主机名如下,主机名可以根据自己的需要配置
NameNode:node02
SencodryNameNode:node03
DataNode :node03
DataNode :node04
DataNode :node05
配置免密
为什么要配置免密?
因为我们的NameNode,SencodryNameNode和DataNode 之间联系的时候需要输入密码,
连接一次配置一次,所以·一次配置免密永久解决问题。
- 首先在各个节点之间运行命令: ssh-keygen -t rsa
然后一直回车出现以下界面皆可以了

产生他们的秘钥。 - 在NameNode也就是node02上执行命令
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node02
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node03
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node04
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node05
根据自己的主机名进行修改 @后自己的主机名
配置完成之后可以使用命令
ssh node04 看可不可以进入到node04中
如果进入,免密配置成功,之后输入exit退回node02
查看主机名
vim /etc/sysconfig/network
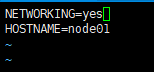
hostname 就是主机名 可以自己修改
同时需要修改 /etc/hosts里的文件
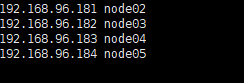
vim /etc/hosts
在最下方添加
前面是整个集群虚拟机的ip 后面是主机名 也就是上边的 hostname
发送文件
网络映射配置完成之后 ,也就是/etc/hosts
把文件发送给其他的节点
/etc/hosts 是绝对路径 如果采用相对路径,一定要切换到该路径下进行发送
scp /etc/hosts [email protected]:/etc
scp /etc/hosts [email protected]:/etc
scp /etc/hosts [email protected]:/etc
@之后的ip就是自己集群其他DataNode ,SencodryNameNode的ip地址
scp就是将某一个节点的文件发送到其他的节点上
修改完成之后 把自己防火墙关掉
切换到根目录 直接cd 回车就可以
chkconfig iptables off 之后重启虚拟机
命令 reboot
Hadoop完全分布式集群搭建jdk一定要安装
把压缩包上传到Linux中
可以使用 Xftp图形化软件直接操作

直接鼠标右键上传就可以了
建议在linux中自己写一个文件夹 来保存自己所安装的文件
我写在了 /opt 下
解压自己的jdk压缩包
tar -zxvf jdk1.8.0_121/ ,这个是我的压缩包的版本。你们可以根据自己下载的进行解压
尽量不要低于1.8
使用命令 vim /etc/profile中配置环境变量
opt/software/是自己jdk的路径
jdk1.8.0_121是自己的jdk版本
export JAVA_HOME=/opt/software/jdk1.8.0_121
export PATH=
JAVA_HOME/bin
请注意
.bashrc 是用户变量
/etc/profile是系统变量
跟自己windows上的环境变量差不太多


配置完成之后
一定要使用
source /etc/profile
使文件生效 一定要使用这个命令
生效之后再把该jdk发送到其他节点上
同上
我的jdk在/opt/software/下
scp /opt/software/jdk1.8.0_121/ [email protected]:/etc
scp /opt/software/jdk1.8.0_121/ [email protected]:/etc
scp /opt/software/jdk1.8.0_121/ [email protected]:/etc
下面就开始配置hadoop的文件了
跟上面操作一样,先上传hadoop压缩包
进行解压:tar -zxvf hadoop-2.6.5.tar.gz
切换路径

修改配置信息

-
slaves --DataNoded节点
vim slaves 把里面的内容修改为DataNoded的主机名
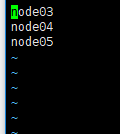
-
vim hdfs-site.xml

<property> <name>dfs.replication</name> //设置备份个数 <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> //secondaryNamenode <value>node03:50090</value>/ </property> 切记:注解不要粘上去3.vim core-site.xml

fs.defaultFS //namenode
hdfs://node02:9000
hadoop.tmp.dir //namenode启动后产生的信息
/var/abc/hadoop/local
切记:注解不要粘上去 -
vi yarn-env.sh

修改java_home的路径,修改为绝对路径
如果格式化错误的话把所有的以env.sh结尾的文件的java_home路径都修改为绝对路径
5.格式化
切换路径 :

格式化


6.启动完全分布式集群
切换到sbin目录
在bin目录下切换 cd …/sbin
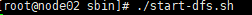

7.上浏览器查看
自己的主节点ip(NameNode)加上:50070
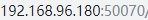
效果:


liveNode节点存活数为3就可以了.
伪分布式集群搭建:
https://blog.csdn.net/CSDN_bird/article/details/91543200
(如有问题可以私信我,自己原创可能不太准确,希望看官谅解)
(一起进步,一起学习,谢谢!)