用神经网络解决回归问题
机器学习的问题分为两大类:
- 回归问题
- 分类问题
对于输出值是连续型的,称为回归问题。
对于输出只是有限个离散值的,称为分类问题。
今天看的视频教程中,是用神经网络来解决一个简单的回归问题。
直接上代码
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
#fake data
x = torch.unsqueeze(torch.linspace(-1,1,100),dim=1)#这句话是把x本来是个一维的数据进行升维
y = x.pow(2) + 0.2*torch.rand(x.size()) #把 x^2乘2的数据加上一个随机噪声。 rand应该是生成0-1之间的一个均匀分布
x,y = Variable(x),Variable(y) #老版本的包装代码。自动微分变量
#plt.scatter( x.data.numpy(),y.data.numpy() )#打印散点图
#plt.show()
class Net(torch.nn.Module): #继承torch.nn.Moudle这个模块,可以调用这个模块的接口
def __init__(self, n_features,n_hidden,n_output ): #搭建计算图的一些变量的初始化
super(Net,self).__init__() #将self(即自身)转换成Net类对应的父类,调用父类的__init__()来初始化
self.hidden = torch.nn.Linear( n_features,n_hidden )
self.predict = torch.nn.Linear( n_hidden,n_output )
def forward(self,x): #前向传播,搭建计算图的过程
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net = Net(1,10,1) #初始时的参数只是多少,貌似没有赋值?或者说默认是全零?
print(net)
plt.ion() #matplotlib变成一个实时打印的状态
plt.show()
optimizer = torch.optim.SGD( net.parameters(),lr = 0.5 ) #随机梯度下降算法
loss_func = torch.nn.MSELoss(); #代价函数,应该是二次代价函数。
for t in range(100):
prediction = net(x)
loss = loss_func( prediction, y )
optimizer.zero_grad() #清空上一部的梯度值,否则应该会累加上去。
loss.backward() #反向传播就散梯度值
optimizer.step() #用计算得到的梯度值,来更新神经网络里面的各个参数
if t % 5 == 0:
plt.cla() #清楚上幅图的散点
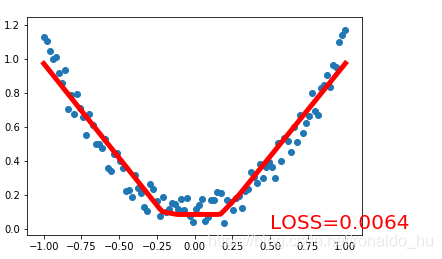
plt.scatter( x.data.numpy(),y.data.numpy() ) #原始数据的散点图
plt.plot(x.data.numpy(),prediction.data.numpy(),'r-',lw=5)
plt.text( 0.5, 0,'LOSS=%.4f'% loss.data.numpy(),fontdict={'size':20,'color': 'red'} )
plt.pause(0.1)
plt.ioff()
plt.show()
代码分析
构造伪数据
x = torch.unsqueeze(torch.linspace(-1,1,100),dim=1)#这句话是把x本来是个一维的数据进行升维
y = x.pow(2) + 0.2*torch.rand(x.size())
torch.linspace函数,显然是从-1到1,中间等分100个点,然后形成一个数组,
unsqueeze这个函数的意义在于将一维的数组进行升维的操作,
即从[],变到[[]].
y 等于说是x^2的值,同时加上一个随机波动的值,这样得到一组伪数据。
定义一个神经网络类
class Net(torch.nn.Module): #继承torch.nn.Moudle这个模块,可以调用这个模块的接口
def __init__(self, n_features,n_hidden,n_output ): #搭建计算图的一些变量的初始化
super(Net,self).__init__() #将self(即自身)转换成Net类对应的父类,调用父类的#__init__()来初始化
self.hidden = torch.nn.Linear( n_features,n_hidden )
self.predict = torch.nn.Linear( n_hidden,n_output )
def forward(self,x): #前向传播,搭建计算图的过程
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
这个类是继承自torch.nn.Module的
首先看构造函数
super(Net,self).init()
这是调用父类的构造函数,来进行初始化
self.hidden = torch.nn.Linear( n_features,n_hidden )
self.predict = torch.nn.Linear( n_hidden,n_output )
nn.Linear生成一个线性模型,wx +b这种形式的一个计算模型,n_features是输入的个数,
n_hidden是隐藏层的个数。
假如n_features为2,n_hidden为3,应该对应的一个计算模型如下:
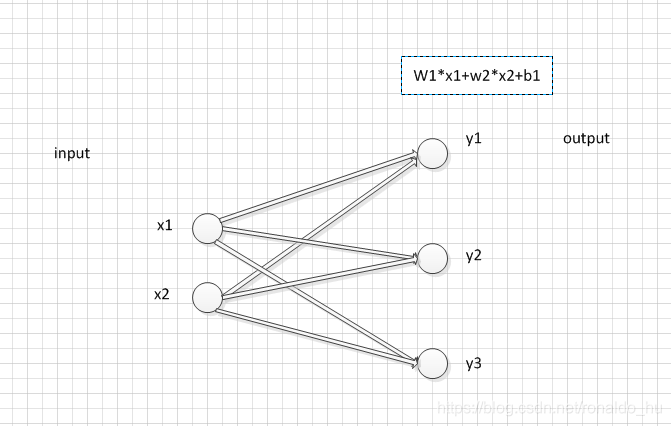
self.hidden,self.predict 这个成员应该就定义了类似于上图这种线性的运算模型。
但是在__init__()函数里面并没有运算过程,所以不会创建计算图节点。真正创建
DAG节点的函数是forward(x)函数,
def forward(self,x): #前向传播,搭建计算图的过程,输入值为x, 经过下面的运算得到一个返回值就是y。
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
当前向传播的时候,输入的x变量,
self.hidden(x)就会调用刚才建立的计算模型,搭建一个算法节点,同时与X的依赖关系也确定了F.relu是个激励函数,这种激励函数听说在近几年的深度神经网络学习很流行,慢慢替代了sigmoid函数了
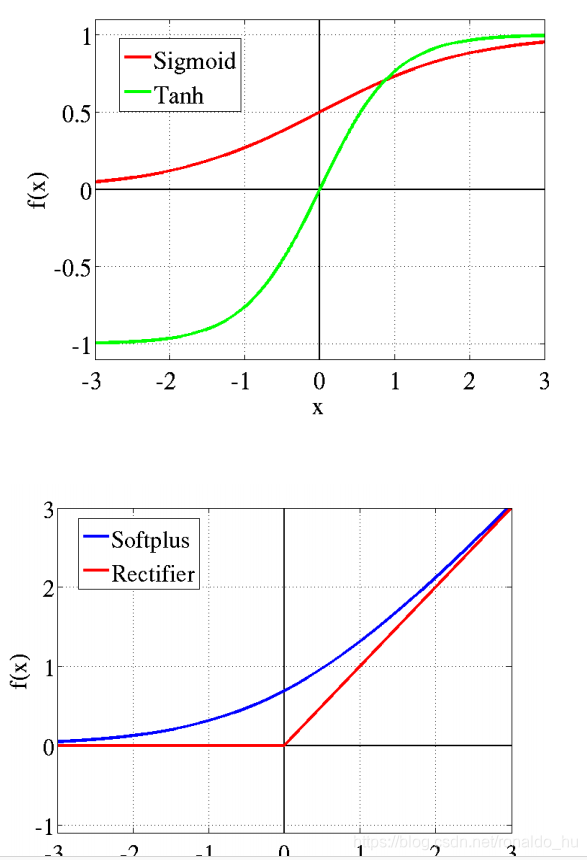
上图是几种激励函数的对比。relu函数最简单了,小于0的值全部为0,大于0的为x,最简单的却最流行。有点意思。
x = self.predict(x)
return x
又经过了一层线性模型的映射,这次没有再加上一个relu函数。返回x,这个x是就是预测值y
。哪里会调用forward函数构建计算图呢?
应该是这句话
prediction = net(x),这句话应该会调用forward。
优化算法与目标函数
net = Net(1,10,1) #初始化神经网络模型,输入层个数为1,隐藏层为10,输出个数为1.初始时的参数值是多少,貌似没有赋值?或者说默认是全零?
print(net)
optimizer = torch.optim.SGD( net.parameters(),lr = 0.5 ) #随机梯度下降算法,注意传入了net.parameters(),说明,optimizer已经关联上了神#经网络的参数
loss_func = torch.nn.MSELoss(); #代价函数,应该是二次代价函数。
new =Net(1,10,1)
这里是创建一个输入层个数为1,隐藏层神经元个数为10,输出层个数为1的一个神经网络。这会调用__init__函数,实际上计算图是没有生成的,只是把神经网络大致给搭出来
optimizer = torch.optim.SGD( net.parameters(),lr = 0.5 )
设置一个一个优化算法。这里选择的是随机下降算法,之前学过,有点忘了,大致的含义就是:实际梯度下降应该每次迭代都应该用所有的数据来计算一次,但是呢,那个计算量太大了,或者说一次没办法知道所有的数据。所以改为每次都用一个数据来进行反向传播,这种方法就叫做随机梯度下降,这种方法几年前学过原理,有点忘了,以后再复习,还得注意到optimizer已经和神经网络的参数net.parameter()挂钩了,以后它做的所有操作,都会影响到net.parameter.当然主要是zeros_grad()以及step(),前者用来每次将参数的梯度值进行清零操作,后者用每次计算的梯度值来调整参数值。
loss_func = torch.nn.MSELoss( );
代价函数一般都用这个,(y’-y)^2。这个值越小越好,我们就是要通过迭代,找到一组合适的参数,使得这个代价函数最小。
反向传播,调整参数
for t in range(100):
prediction = net(x)
loss = loss_func( prediction, y )
optimizer.zero_grad() #清空上一步的参数梯度值,否则应该会累加上去。
loss.backward() #反向传播,计算梯度值
optimizer.step() #调整参数值
循环100次呢,代表是要反向传播100次,来迭代得寻找最优的那组神经网络参数。
prediction = net(x),这显然是个典型的神经网络的前向传播过程,那么它肯定会调用net的forward函数,构建计算图节点
loss = loss_func(prediction,y)又构建了新的一个计算代价函数的节点。optimizer.zero_grad()是把优化器中记录的各个参数的梯度值置零,这步操作是在每次反向传播的之前进行的。之前看一个教程是每个梯度如果不清除的话,会叠加上去,而不是覆盖,可能这是需要这步操作的原因。
整个计算图的模型如下:
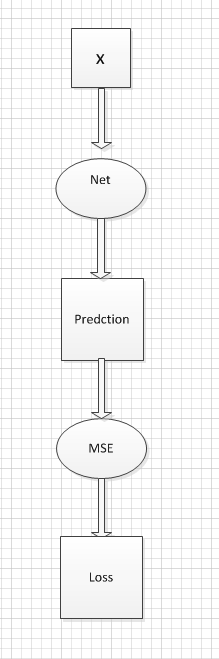
optimizer.step() 就是根据每次计算的参数的梯度值,来更新一次参数。
每次更新参数,都会让参数值向着使得LOSS函数最小的方向更新(当然单次来看,也许不一定,但是总的趋势肯定是),设置迭代次数为100次,反向传播100次,每次都会用参数的梯度值来更新一下参数值。最后拟合参数值,前向传播得到的预测值和样本值很相近了
第1次
最后一次