合并多个csv文件,网上一搜大体会看到这个程序:
csv_list = glob.glob('*.csv') #查看同文件夹下的csv文件数
print(u'共发现%s个CSV文件'% len(csv_list))
print(u'正在处理............')
for i in csv_list: #循环读取同文件夹下的csv文件
fr = open(i,'rb').read()
with open('result.csv','ab') as f: #将结果保存为result.csv
f.write(fr)
print(u'合并完毕!')
这个是不完全对的,为什么呢?因为列名重复写了好几遍
可以看到其是一个一个文件读取,在每个文件中是一行一行读取,然后写入到最终的文件中,这样的话
当合并的csv中全是数据的话这是没有问题的,然而有的时候我们的csv是有列名的,这样合并就会发生错误:
假如我目前有两个待合并的csv文件如下:test1,test2


(这里列名的顺序有点问题,按习惯来说id 应该在第一列)
按上面合并的话结果是什么呢?如下:result

看到了吧,这就是问题
其实我们还可以使用pandas 的文件读取,写入的API:
inputfile = str(os.path.dirname(os.getcwd()))+"/Data/*.csv"
outputfile = str(os.path.dirname(os.getcwd()))+"/Data/result.csv"
csv_list = glob.glob(inputfile)
filepath = csv_list[0]
df = pd.read_csv(filepath)
df = df.to_csv(outputfile,index=False)
for i in range(1,len(csv_list)):
filepath = csv_list[i]
df = pd.read_csv(filepath)
df = df.to_csv(outputfile,index=False,mode='a+')结果也是一样:

那么有什么办法可以实现我们的目的吗?
首先我们明白就是除了保留第一个文件的列名外,后续文件的列名我们是不需要的,于是我们可以这样:
import glob
import os
import pandas as pd
inputfile = str(os.path.dirname(os.getcwd()))+"/Data/*.csv"
outputfile = str(os.path.dirname(os.getcwd()))+"/Data/result.csv"
csv_list = glob.glob(inputfile)
filepath = csv_list [0]
df = pd.read_csv(filepath)
df = df.to_csv(outputfile,index=False)
for i in range(1,len(csv_list)):
filepath = csv_list [i]
df = pd.read_csv(filepath)
df = df.to_csv(outputfile,index=False, header=False,mode='a+')结果:是正确的
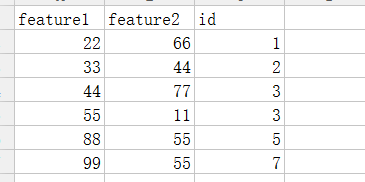
可以看到唯一不同的就是:
header=False即后续csv文件是不保存列名的