一、BIO时代
BIO1.0版本
在jdk1.4之前,java网络编程都是采用的BIO模式,BIO全称是Blocking IO,也就是阻塞式IO 接下来就以拨打10086客服电话为例,介绍下BIO是如何通信的。(10086客服是服务端,移动用户是客户端,10086是端口号) BIO1.0版本 客服等待用户拨打电话10086,此时是阻塞的,因为客服不能干别的事,只能等待客户拨打电话。当用户拨打10086之后和客服接通电话,客户和客服之间进行交流。直到交流结束,客户挂电话,然后客服继续等下一个电话。
问题:当第一个客户接通10086电话之后,正在交流的时候,第二个客户如果也拨了10086,则会被提示正在占线中,直到第一个客户挂断了电话之后才可以接通。
BIO2.0版本
主客服等待用户拨打10086,用户1拨打了电话之后,客服将用户1转接给了专门处理客户诉求的客服A(新建线程处理客户端请求),此时用户2拨打10086是可以打通的,然后主客服将用户2转接给了客服B,用户3转接给了客服C,这样就可以使得10086不会被占线。
问题:当高并发情况下,同一时间有10000个用户都拨打了10086,那么就需要安排10000个客服来处理用户的诉求,而且是没有上限,很容易就导致客服资源不够用。
BIO3.0版本
移动公司成立客服部,设定客服人员上限为100个(创建线程池,上限是100个线程),那么当有用户拨打10086时,主客服还是安排客服A、客服B、客服C来处理用户诉求,当100个客服都在处理用户诉求时,第101个用户拨打10086,主客服就会通知,客服正忙,请稍等。。。当100个正忙的客服中有某一个客服处理完之前的事之后变得空闲之后,立马再来处理第101个用户的诉求。这样就避免了客服不够用的情况(线程数得到控制)
问题:在高并发情况下,避免了资源不够用的问题,但是没有从根本上解决用户过多而需要等待的问题
总结:BIO的最主要特点就是一个用户需要使用一个客服来处理,也就是一个客户端需要分配一个线程来处理,也就是客户端和线程数量之间的比例永远是1:1关系。如果用户并发数量过大,或者客服处理速度慢,就会导致其他客户端一直处于等待。
BIO时代结束
二、NIO时代
随着用户数量越来越多,移动公司感受到了采用BIO的工作模式无法即使解决用户的需求,于是开始进行改革,分别从以下几个问题来进行改革。 问题一: BIO时代,用户拨打10086之后,主客服就会把用户转接给处理事务的客服(分配了一个线程来处理客户端请求),但是有可能这个用户拨通了电话之后就一直将电话放着而不进行通话,不好听的比喻就是占着茅坑不拉屎,这样的用户如果分配客服来处理,显然是浪费了客服资源。
改革一: 针对上面的问题,移动出台规定,只有当用户抛出了确定的诉求之后,才分配客服来处理(当客户端和服务端之间有确定的IO操作时才新建线程来处理)。这样的做法就可以筛选出哪些是真正有诉求的用户,哪些是无效的用户。而要实现这样的措施,就需要从主客服那里处理,这是主客服拿出了一个小本本,上面记录了哪些用户是有效用户,哪些是无效用户。(采用map记录,key是客户端,value是当前的状态,而这个小本本就是NIO中的Selector)
问题二: 当用户发送了诉求,客服在进行处理的时候,用户和客服都是阻塞的,因为他们都不能干别的事,客服需要等待用户说完诉求,用户需要等待客服处理完得到结果。如果用户是个口吃或者是个树懒(客户端网络延迟)又或者用户的诉求太多(发送给服务器的数据较多),那么此时客服就必须一直等待着;同理,如果客服处理业务的能力比较慢(CPU性能较差)或者是处理的业务比较复杂(服务端的业务逻辑较复杂),那么此时用户也必须一直等待着。按周星驰《少林足球》中的一句经典台词来说:“我一秒钟几十万上下呢”,显然目前的工作方式时间成本会比较大。
改革二: 针对上面的问题,移动出台规定,设置微信公众号来处理用户诉求,用户在微信公众号的投诉问题处用语音(将问题存在语音中)描述自己需要处理的问题,问题上报之后就可以去干别的事去了(非阻塞),而不需要等待客服处理问题;而客服通过微信公众号后台获取到用户的诉求之后,就可以处理用户诉求,处理完了之后,将处理结果再通过微信公众号发送给用户,然后客服就可以干别的事去了(非阻塞),而用户啥时空闲了就可以查看微信公众号上面的处理结果。(NIO就将语音封装成了缓冲区Buffer,将微信公众号封装成了Channel) BIO时代,移动公司是通过电话和客户进行交流,NIO时代是通过微信公众号发送接收语音和客户交流。 BIO时代,服务器和客户端是面向流来交互;NIO时代是通过channel发送和接收buffer和客户端交互。
以上就是从BIO到NIO的大致演变过程 那么再总结下几个概念: 同步IO:当客户端发起IO操作,如果服务端没有执行完成,那么客户端需要一直等待着,直到得到结果 异步IO:当客户端发起IO操作,立马可以去干别的事,当服务端执行完成之后,会来通知客户端获取结果 阻塞IO:当进行IO操作时,如果IO的读写没有完成,那么不会返回结果,而是阻塞当前线程或进程后面的操作 非阻塞IO:当进行IO操作时,如果IO的读写没有完成也立即返回结果不需要等待,有IO的读写时才进行IO操作 IO多路复用:IO就是网络IO,多路指多个TCP连接或多个channel,复用是指一个或少数线程来处理这些TCP连接或channel,也就是多个网络IO复用一个或少量线程来处理
BIO是同步阻塞IO,因为客户端需要等待服务端结果,所以是同步的;服务端在没有处理完IO操作时,不会立即返回结果,而是阻塞的 NIO是同步非阻塞IO,因为客户端还是需要等待服务端结果,所以同步的;而服务端处理IO的时候是通过buffer来处理的,数据的发送和接收都是通过buffer来进行的,而不是一直等待IO流的读写,所以是非阻塞的
而在NIO之后又出现了NIO2.0版本也就是AIO,AIO是异步非阻塞IO,服务端的实现模式是一个有效请求分配一个线程。客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
三、AIO时代
AIO是NIO的2.0版本,实现的是异步非阻塞IO
四、操作系统的IO多路复用实现
目前支持I/O多路复用的操作系统采用select、poll或epoll的方式来实现,相当于一个进程监视多个FD(socket描述符),一旦某个FD就绪(可读或可写),能够通知程序进行对应操作。
select方式
1.select是单进程监视文件描述符,文件描述符数量有限制,在FD_SETSIZE中设置,一般是1024或2048个
2.select对socket进行扫描对时候是线性全盘扫描,采用轮询方式,效率较低
3.需要维护一个存放大量FD对数据结构,需要从用户空间和内核空间在传递该数据结构时复制开销大
poll方式
1.poll方式采用链表方式存储FD,没有FD数量限制,其他和select几乎差不多
epoll方式
1.epoll方式没有FD数量限制
2.epoll使用一个文件描述符管理多个描述符。
3.采用事件通知方式,通过epoll_ctl注册fd,一旦fd就绪,内核就会采用类似callback的回调来激活该fd,epoll_wait就可以得到通知
4.如果socket全部是活跃的,那么epoll性能一般,实际情况是管理的描述符数量较多,而活跃的较少。
五、NIO的实现原理
NIO的三大核心分别是channel、selector和buffer,那么先回顾下NIO的工作流程:
服务端:
1、创建一个ServerSocketChannel,是所以客户端通道的父通道,用于监听客户端的连接
2、绑定服务端端口,设置模式为非阻塞模式
3、创建多路复用通道管理器Selector(只需要一个或少数几个Selector就可以处理高并发的channel)
4、将ServerSocketChannel注册到Selector上,并监听ACCEPT事件(客户端连接事件)
5、Selector通过死循环查找注册过的所有channel有没有触发对应的事件
6、当监听到客户端连接的事件,那么创建SocketChannel,和客户端进行TCP连接,并设置为非阻塞模式
7、将和客户端之间的SocketChannel注册到Selector上,并监听OP_READ事件(channel可读事件,客户端写入数据,服务器就可以读取数据)
8、创建一定大小的缓存区,将channel中客户端发送来的缓冲区数据,并进行解析
9、将读取到的数据放入业务系统进行处理
10、回写数据存入buffer中,并调用channel的write方法 (不需要关闭channel,channel是客户端断开了连接之后,服务端会接收到ON_READ事件,然后报错就知道channel断开了)
NIO和BIO最大到区别就是引入了channel、selecotr和buffer到概念,这三大组件到原理又是怎么样到呢?下面来慢慢看。
buffer(缓冲区):
缓存区到作用是缓存读和写到所有数据,缓冲区的实现方式的数组加标记位置 数组是存放数据的,如字节数据则用byte数组,字符则用char数组等等 标记位置的变量有多个,分别是capacity、position、limit和mark
capacity表示数组的容量,大小固定不变,初始化时设置
position表示当前的位置,初始值为0 当向buffer中写数据时,每写一位数据,位置就往后移一位,取值范围为0~capation-1, 当buffer从写模式切换到读模式,position重新置为0 当从buffer中读数据时,每读一位数据,位置就往后移一位
limit表示当前可以读或写多少数据,在写模式下,默认值为capation,当position值置为0后,limit值为position
mark表示一个备忘位置,相当于一个标记。调用mark方法来设定mark=position,调用reset设定position=mark
四个属性之间的关系为 0<=mark<=position<=limit<=capacity
下面就图解buffer数组的读写数据
首先,初始化初始化一个容量为10的数组,此时capacity=10,position=0,limit=10,mark未初始化
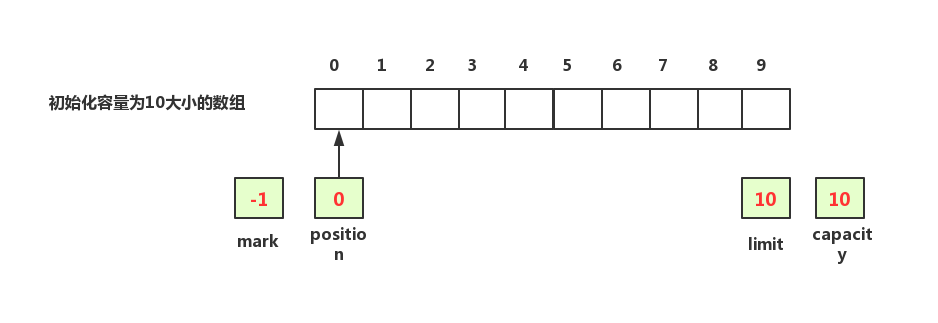
现在从buffer数组中写入数据,调用put()方法,假设写入大小为5的数据,写入之后capacity、limit以及mark值不变,position变成了5,表示数组下标为5的位置可以写入新数据,如下图示
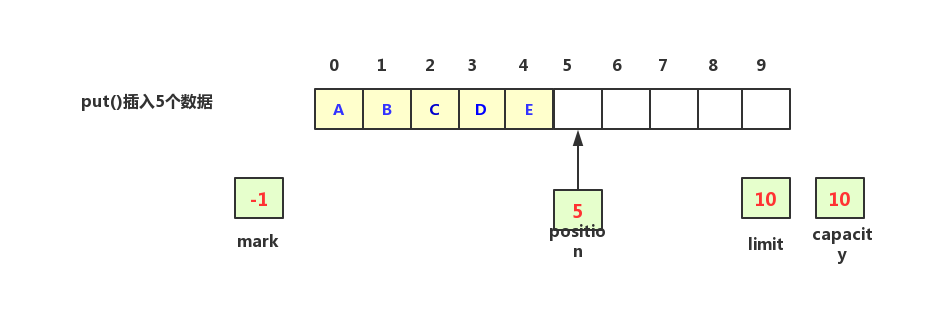
当缓冲区需要被读出数据的时候,调用flip()方法,表示将当前缓冲区从写模式切换成读模式,此时position重置为0表示从0的位置开始读,将limit改为5表示刚刚写入到5的位置,mark和capacity值不变,如下图示
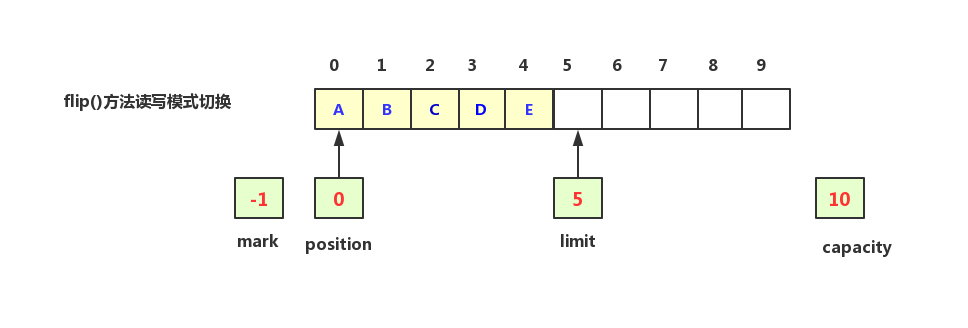
每读一个数据,position会随着数据的读取进行挪动,但是如果数据读取到一半发现有问题需要重新从头再读一次,此时就需要调用rewind()方法将position进行重置为0,其他三个值不变
另一种情况,假设读取了一部分数据之后就不再读了,而是再切换会写模式,此时如果之间从5到位置开始写,显然已经被读到空间就无法再写入数据了,会造成空间的浪费,此时就可以调用compact()进行压缩处理
compact方法的逻辑是将当前剩下的未读数据复制到0的位置,limit重新设置为最大值,position设置为下一个可写到地址,如上例,如果读出了“AB”两个数据,还剩下“CDE”未读,那么执行compact方法之后的结果如下图示:
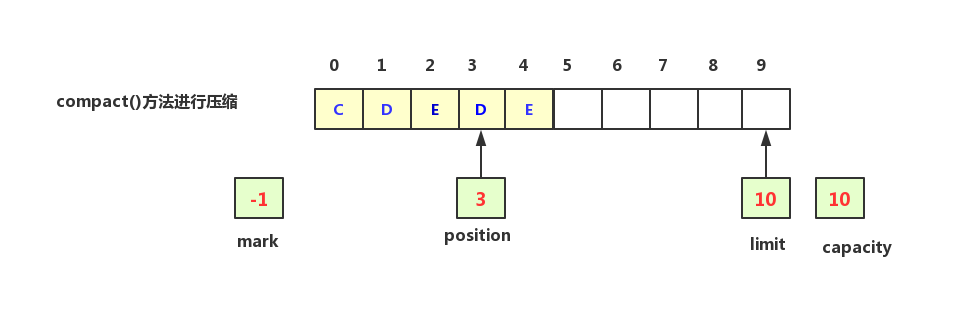
上图中可以看出“DE”两个数据会重复,但是再下一次执行put读时候会被新数据所覆盖,position指向了下一个可以写到位置