这是书籍《Pandas Cookbook》书籍第01章的代码复现,所有代码运行在Jupyter Notebook上,原讲解地址是:
https://www.jianshu.com/p/5809f6cf78ca
我上传代码的github地址是:
https://github.com/Asunqingwen/PandasCookbook.git
github上有该书中用到的data,里面代码会不定期更新(因为工作原因,时间不定),直到本书学习完成!
相比原讲解,会穿插一些自己的理解,水平有限,请各路大神指正。
文章目录
1.DataFrame的结构体
import pandas as pd
import numpy as np
#设定最大列数和最大行数
pd.set_option('max_columns',8,'max_rows',10)
#用read_csv()方法读取csv文件
movie = pd.read_csv('data/movie.csv')
movie.head()
head(n)函数是显示前n行,默认显示前5行

2.访问DataFrame的组件
#提取列索引
columns = movie.columns
#提取行索引
index = movie.index
#提取数据
data = movie.values
columns
index
data
显示列索引,就是列名

显示行索引,默认的行索引是数据从上到下的排列顺序,这里一共4916个数据
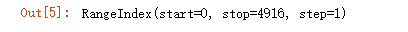
这是所有数据的展示

输出各个变量的数据类型

issubclass(a,b)这个函数是判断a是否是b的子类型
#判断是不是子类型
issubclass(pd.RangeIndex,pd.Index)
用变量的values属性获取变量具体的值

3.理解数据类型
#各列的类型
movie.dtypes
#显示各类型的数量
movie.get_dtype_counts()


4.选择一列数据,作为Series
这里先解释下什么Series,Pandas库中的基本数据结构是Series,而Series类似于一维数组,不过它有index这个属性,而将多个Series按列合并就组成了Pandas类似于二维数组的结构——DataFrame,这也是最常用的,上面的movie就是一个DataFrame
这里分别通过索引和属性的方式,选取了column name为director_name的那一列

同样用索引和属性两种方式查看movie中一列的数据类型,可以看到是Series,最后是将一列转为DataFrame,然后取前面5行

5.调用Series方法
查看所有不重复的指令,其实就是用到了set中元素不重复的特性,dir()是Python的内置函数,可以list出对象的所有属性和方法
#查看Series所有不重复的指令
s_attr_methods = set(dir(pd.Series))
len(s_attr_methods)
#查看DataFrame所有不重复的指令
df_attr_methods = set(dir(pd.DataFrame))
len(df_attr_methods)
#这两个集合中有多少共有的指令
len(s_attr_methods & df_attr_methods)
下面是Series调用head()方法,前面是DataFrame在调用

下面的code主要是计算Series的size,shape,len等,这些方法和numpy库以及list内置方法很类似
#分别计数,最多显示10行
pd.set_option('max_rows',10)
director.value_counts()
actor_1_fb_likes.value_counts()
director.size
director.shape
len(director)
#director有多少非空值
director.count()

下面的code主要是计算pandas中数据的基本统计特征值,比如min,max,avg,std等,注意quantile(n)这个函数,如果n=0.5,那它返回的就是中位数
#actor_1_fb_likes的中位分位数
actor_1_fb_likes.quantile()
#求最小值、最大值、平均值、中位数、标准差、总和
actor_1_fb_likes.min(),actor_1_fb_likes.max(),\
actor_1_fb_likes.mean(),actor_1_fb_likes.median(),\
actor_1_fb_likes.std(),actor_1_fb_likes.sum()
#打印描述信息
actor_1_fb_likes.describe()
director.describe()
actor_1_fb_likes.quantile(.25)
#各个十分之一分位数
actor_1_fb_likes.quantile([.1,.2,.3,.4,.5,.6,.7,.8,.9])

下面的code主要是判断数据里是否有缺失值,对缺失值的处理是补充还是删掉,同时计算某列各个值出现的频率,即value_counts(normalize=True),如果这里不设置normalize这个参数,那么value_counts这个函数只有计数的功能
#非空值
director.isnull()
#填充缺失值
actor_1_fb_likes_filled = actor_1_fb_likes.fillna(0)
actor_1_fb_likes_filled.count()
#删除缺失值
actor_1_fb_likes_dropped = actor_1_fb_likes.dropna()
actor_1_fb_likes_dropped.size
#value_counts(normalize=True) 可以返回频率
director.value_counts(normalize=True)
#判断是否有缺失值
director.hasnans
#判断是否是非缺失值,注意区别上面用到的isnull()函数
director.notnull()


6.在Series上使用运算符
在Series上进行数学运算,主要是一般的数学运算符——+,-,*,/等,或者用对应的函数替代——add,mul,floordiv等


7.串联Series方法
不知道简书那个讲解者,为啥翻译成串联。这段code其实主要还是缺失值的处理,数据中数值类型的转换,比如float64转为int

8.使索引有意义
pandas中数据结构的默认行索引数据的顺序值,类似于数组的下标,改变索引的一种方式是下面,通过set_index()函数,函数的参数是具体的列名

改变索引的第二种方式就是在导入数据的csv文件时,用参数index_col来指定,值也是相应的列名,如果需要将索引还原为默认的,则用reset_index()

9.重命名行名和列名
通过rename()函数,可以将索引和列名重新命名

10.创建或删除列
像dict那样定义新的key一样,可以用同样的方法定义新的一列

可以用all()函数判断所以的bool值是否都为True,因为有些情况对两个数据结构进行数学运算后,返回的就是bool变量,通过验证bool值是否都为True,来决定下一步的操作

也可以通过insert()函数来进行新一列的插入
