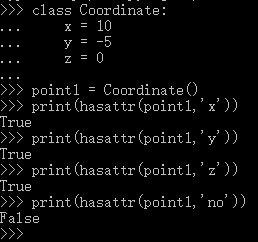
hasattr()函数(内置函数)
转载自:https://blog.csdn.net/chituozha5528/article/details/78023463
hasattr(object, name)
判断一个对象里面是否有name属性或者name方法,返回BOOL值,有name特性返回True, 否则返回False。
需要注意的是name要用括号括起来
class test():
name='xiaoming'
def run(self):
return 'Hello World!'
t=test()
print hasattr(t,"name")#输出True
print hasattr(t,"run")#输出True实例:
range()
转载自:https://blog.csdn.net/sinat_33588424/article/details/80206971
python range() 函数可创建一个整数列表,一般用在 for 循环中。
语法:range(start, stop[, step])
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
>>>range(10) # 从 0 开始到 10
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1, 11) # 从 1 开始到 11
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> range(0, 30, 5) # 步长为 5
[0, 5, 10, 15, 20, 25]
>>> range(0, 10, 3) # 步长为 3
[0, 3, 6, 9]
>>> range(0, -10, -1) # 负数
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> range(0)
[]
>>> range(1, 0)
[]以下是 range 在 for 中的使用,循环出runoob 的每个字母:
>>>x = 'runoob'
>>> for i in range(len(x)) :
... print(x[i])
...
r
u
n
o
o
b
>>>转载自:https://blog.csdn.net/littlehaes/article/details/82490884
python2中,range()返回的是list,可以将两个range()直接相加,如range(10)+range(15)
python3中,range()成了一个class,不可以直接将两个range()直接相加,需要先加个list,如list(range(10))+list(range(10))
因为python3中的range()为节省内存,仅仅存储了range()的start,stop,step这三个元素,其余值使用时一个一个的算,其实就是个迭代器,加上list()让range()把所有值算出来就可以相加了
len()
求字符串 x 的长度,Python 的写法是 len(x) ,而且这种写法对列表、元组和字典等对象也同样适用,只需要传入对应的参数即可。len() 函数是共用的。
Python 采用的是一种前缀表达式
set()
转载自:
https://blog.csdn.net/yushupan/article/details/82698223
set 是一个不允许内容重复的组合,而且set里的内容位置是随意的,所以不能用索引列出。可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
1、创建set集合
>>> set([1,2,3])
{1, 2, 3}
>>> set('123')
{'1', '2', '3'}
>>> set()
set() #创建一个空set
enumerate()
转载自:https://blog.csdn.net/qq_18941425/article/details/79737438
1.有一 list= [1, 2, 3, 4, 5, 6]
请打印输出:
0, 1
1, 2
2, 3
3, 4
4, 5
5, 6
list=[1,2,3,4,5,6]
for i ,j in enumerate(list)
print(i,j)在同时需要index和value值的时候可以使用 enumerate。
word_to_idx = {w:i for i, w in enumerate(unique_vocab)}
#给unique_vocab中的词加一个序号标签:
格式为w(词):i(序号)
进行循环将词和序号取出来:for i, w(enumerate中的两个变量) in enumerate()argparse中add_argument
转载自:https://blog.csdn.net/Samaritan_x/article/details/84146029
add_argument:运行程序时,给定参数,通过调用给定的参数执行程序
ArgumentParser.add_argument(name or flags…[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
name of flags 是必须的参数,该参数接受选项参数或者是位置参数。
parser.add_argument('--inner-batch', help='inner batch size', choices=[1,5,10], default=5, type=int)就比如上面的 '--inner-batch' ,例如在启动程序demo.py时,在终端中输入 ./demo.py --inner-batch 10 就会将inner-batch这个选项的参数设置为10,不给参数时使用default参数5。
参数数量nargs默认为1个,也可以自己设定多个。
当选项接受1个或者不需要参数时指定nargs=’?',当没有参数时,会从default中取值。对于选项参数有一个额外的情况,就是出现选项而后面没有跟具体参数,那么会从const中取值
type为参数类型,例如int。
choices用来选择输入参数的范围,例如上面choices=【1,5,10】表示输入参数只能为1或5或10
required用来设置在命令中显示参数,当required为True时,在输入命令时需要显示该参数
help用来描述这个选项的作用
action表示该选项要执行的操作
dest用来指定参数的位置
metavar用在help信息的输出中
lambda
转载自:https://blog.csdn.net/zjuxsl/article/details/79437563
格式:lambda argument_list: expression
argument_list是参数列表
expression是一个关于参数的表达式
用法:
lambda x, y: x*y;函数输入是x和y,输出是它们的积x*y
lambda:None;函数没有输入参数,输出是None
lambda *args: sum(args); 输入是任意个数的参数,输出是它们的和(隐性要求是输入参数必须能够进行加法运算)
lambda **kwargs: 1;输入是任意键值对参数,输出是1
sorted()
转载自:https://blog.csdn.net/ymaini/article/details/81633775
sorted方法用来进行排序操作,如数字,字符串组成的list,根据dict类型的key或者value排序,现将平时使用的sorted的方法和数据类型进行整理
sorted(iterable[, cmp[, key[, reverse]]])
"""
对一个iterable对象排序,返回一个排序之后的list
@param iterable 可迭代遍历对象
@param cmp 默认None, 自定义的比较函数,2个参数
@param key 默认None, 自定义的函数,1个参数,参数值来源与列表元素
@param reverse 默认False(正序)
@return 返回一个排序之后的list
"""
passmap()函数
转载自:https://blog.csdn.net/maoersong/article/details/21868037
通过Python中help可以查看map()的具体用法
>>> help(map)
Help on built-in function map in module __builtin__:
map(...)
map(function, sequence[, sequence, ...]) -> list
Return a list of the results of applying the function to the items of
the argument sequence(s). If more than one sequence is given, the
function is called with an argument list consisting of the corresponding
item of each sequence, substituting None for missing values when not all
sequences have the same length. If the function is None, return a list of
the items of the sequence (or a list of tuples if more than one sequence).
map接收一个函数和一个可迭代对象(如列表)作为参数,用函数处理每个元素,然后返回新的列表。
例1:
>>> list1 = [1,2,3,4,5]
>>> map(float,list1)
[1.0, 2.0, 3.0, 4.0, 5.0]
>>> map(str,list1)
['1', '2', '3', '4', '5']
等价于
>>> list1
[1, 2, 3, 4, 5]
>>> for k in list1:
float(list1[k])
2.0
3.0
4.0
5.0
lower()
转载自:https://blog.csdn.net/qq_40678222/article/details/83033422
描述:将字符串中的所有大写字母转换为小写字母。
语法:str.lower() -> str 返回字符串
str1 = "I Love Python"
str2 = "Groß - α" #德语 大写α
print(str1.casefold())
print(str1.lower())
print(str2.casefold())
print(str2.lower())结果:
i love python
i love python
gross - α
groß - α注意 lower()函数和casefold()函数的区别:
lower() 方法只对ASCII编码,即‘A-Z’有效,对于其它语言中把大写转换为小写的情况无效,只能用 casefold() 函数。
super()
转载自:https://blog.csdn.net/qq_14935437/article/details/81458506
如果在子类中也定义了_init_()函数,那么该如何调用基类的_init_()函数:
方法一、明确指定 :
class C(P):
def __init__(self):
P.__init__(self)
print 'calling Cs construtor'方法二、使用super()方法 :
class C(P):
def __init__(self):
super(C,self).__init__()
print 'calling Cs construtor'
c=C()Python中的super()方法设计目的是用来解决多重继承时父类的查找问题,所以在单重继承中用不用 super 都没关系;但是,使用 super() 是一个好的习惯。一般我们在子类中需要调用父类的方法时才会这么用。
super()的好处就是可以避免直接使用父类的名字.主要用于多重继承,如下:
class A:
def m(self):
print('A')
class B:
def m(self):
print('B')
class C(A):
def m(self):
print('C')
super().m()
C().m()这样做的好处就是:如果你要改变子类继承的父类(由A改为B),你只需要修改一行代码(class C(A): -> class C(B))即可,而不需要在class C的大量代码中去查找、修改基类名,另外一方面代码的可移植性和重用性也更高。
另外:避免使用 super(self.__class__, self),一般情况下是没问题的,就是怕极端的情况:
class Foo(object):
def x(self):
print 'Foo'
class Foo2(Foo):
def x(self):
print 'Foo2'
super(self.__class__, self).x() # wrong
class Foo3(Foo2):
def x(self):
print 'Foo3'
super(Foo3, self).x()
f = Foo3()
f.x()在 Foo2 中的 super(self.__class__, self) 导致了死循环,super 永远去找 Foo3 的 MRO 中的下一个类,super 的第一个参数应该总是当前的类,Python 没有规定代码必须怎样去写,但是养成一些好的习惯是很重要,会避免很多你不了解的问题发生。