1. 聚合函数
聚合函数是用来做纵向运算的函数
- count():统计指定列不为null的记录行数
- max():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算
- min():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算
- sum():计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0。求和的时候忽略null,如果都是null,则算出来的结果为null。
- avg():计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0.

2. 排序

3. 删除
- delete,删除部分数据,注意带上where子句,回滚段要足够大;
*drop-删除表; - truncate-保留表而将所有数据删除,如果和事务无关
- delete:和事务有关,或者想触发trigger
- 如果是整理表内部的碎片,可以用truncate跟上reuse stroage,再重新导入/插入数据。
4. sql 注入
通过在 Web 表单中输入(恶意)SQL 语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行 SQL 语句。
- 举例:当执行的 sql 为 select * from user where username = “admin”or “a”=“a”时,sql 语句恒成立,参数 admin 毫无意义。
- 防止 sql 注入的方式:
- 预编译语句:如,select * from user where username = ?,sql 语句语义不会发生改变,sql 语句中变量用?表示,即使传递参数时为“admin or ‘a’= ‘a’”,也会把这整体当做一个字符创去查询。
- Mybatis 框架中的 mapper 方式中的 # 也能很大程度的防止 sql 注入($无法防止 sql 注入)。
5. Mysql 性能优化
- 只要一行数据时使用 limit 1
如已知会得到一条数据,这种情况下加上 limit 1会增加性能。因mysql 数据库引擎会在找到一条结果停止搜索,而不是继续查询下一条是否符合标准直到所有记录查询完毕。 - 选择正确的数据库引擎
Mysql 中有两个引擎 MyISAM 和 InnoDB,每个引擎有利有弊。
- MyISAM 适用于一些大量查询的应用,但对于有大量写功能的应用不是很好。甚至你只需要update 一个字段整个表都会被锁起来。而别的进程就算是读操作也不行要等到当前 update 操作完
成之后才能继续进行。另外,MyISAM 对于 select count(*)这类操作是超级快的。 - InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用会比 MyISAM 还慢,但是支持“行锁”,所以在写操作比较多的时候会比较优秀。并且,它支持很多的高级应用,例如:事物。
- MyISAM 适用于一些大量查询的应用,但对于有大量写功能的应用不是很好。甚至你只需要update 一个字段整个表都会被锁起来。而别的进程就算是读操作也不行要等到当前 update 操作完
- 用 not exists 代替 not in
Not exists 用到了连接能够发挥已经建立好的索引的作用,not in 不能使用索引。Not in 是最慢的方式要同每条记录比较,在数据量比较大的操作红不建议使用这种方式。 - 对操作符的优化,尽量不采用不利于索引的操作符
如:in not in is null is not null <> 等
某个字段总要拿来搜索,为其建立索引:Mysql 中可以利用 alter table 语句来为表中的字段添加索引,语法为:alter table 表明add index (字段名);
6. 分组查询
当需要分组查询时需要使用group by子句,例如查询每个部分的工资和,就需要使用部门来分组。

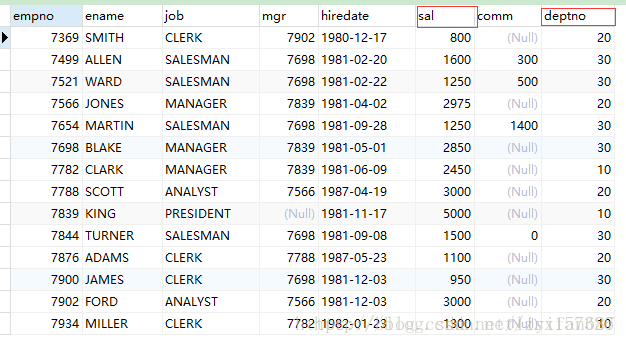
* 执行了select deptno,sum(sal) from emp group by deptno; 后
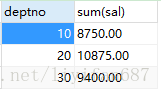
- 执行了select deptno,count(*) from emp where sal>1500 group by deptno;之后
这句话是先把sal>1500的都查出来,然后再从查出来的这里边查
having子句
where是在分组前对数据进行过滤,having是在分组后对数据进行过滤。
having后面可以使用聚合函数,where不可以使用聚合函数。
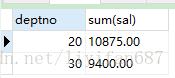
- select deptno,sum(sal) from emp group by deptno having sum(sal)>9000;
7. 分页limit


8. 数据的完整性
数据的完整性只对增删改有作用,对查询数据没有限制。
作用:保证用户输入的数据保存到数据库中是正确的确保数据的完整性=在创建表时给表中添加约束完整性的分类:
- 实体完整性
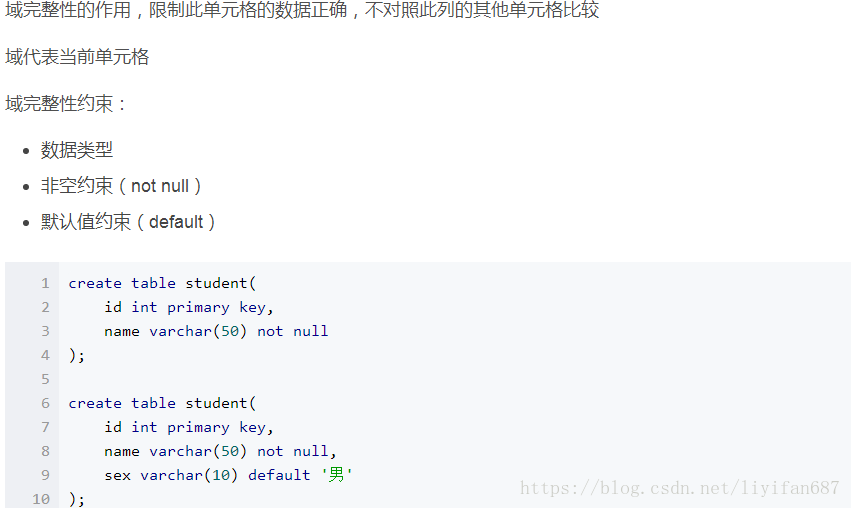
- 域完整性
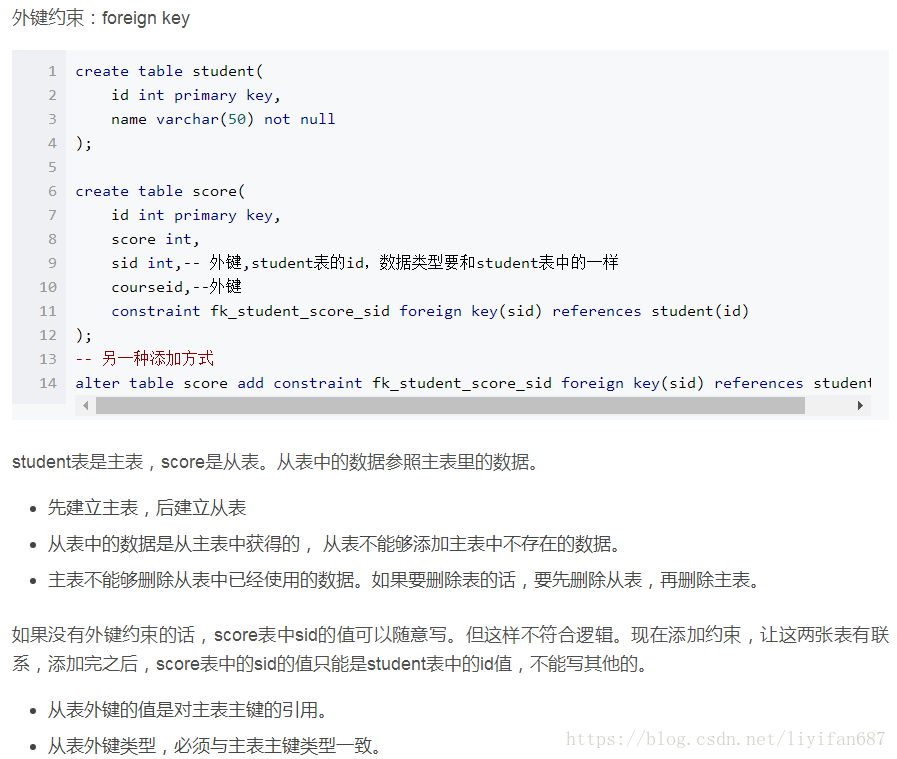
- 引用完整性
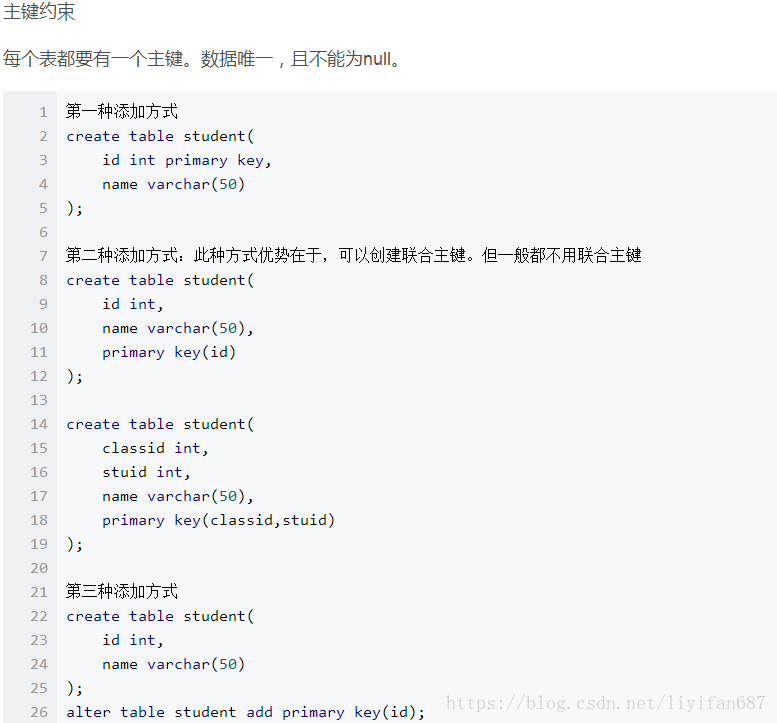
实体完整性
- 实体:即表中的一行(一条记录)代表一个实体
- 实体完整性的作用:标识每一行数据不重复
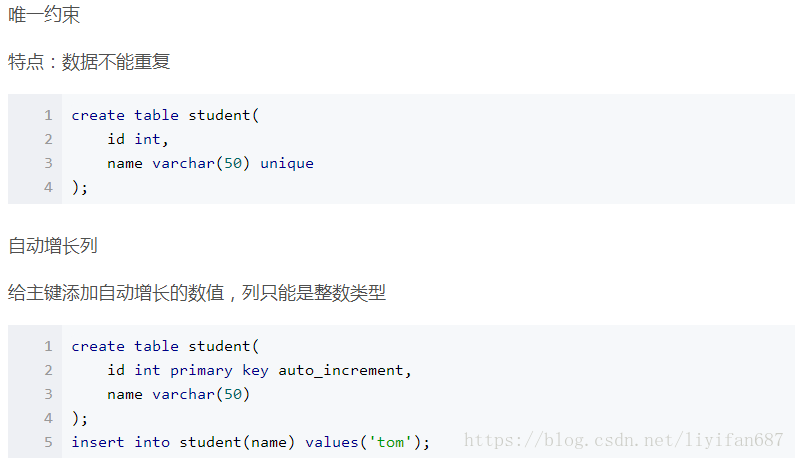
- 约束类型:主键约束(primary key) 唯一约束(unique) 自动增长列(auto_increment)
域完整性
引用完整性(参照完整性)
9.连接查询
1. 内联接(典型联接运算,使用= 或<>之类比较运算符)包括相等联接和自然联接.(使用关键字inner join – inner可省略)
内联接使用比较运算符根据每个表共有的列的值匹配两个表中的行。如,检索 students和courses表中学生标识号相同的所有行。
2. 外联接
外联接可以是左向外联接、右向外联接或完整外部联接。
- LEFT JOIN或LEFT OUTER JOIN
左向外联接的结果集包括LEFT OUTER子句中指定左表的所有行,不仅是联接列所匹配行。如左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。 - RIGHT JOIN 或 RIGHT OUTER JOIN
右向外联接是左向外联接的反向联接。将返回右表的所有行。如右表的某行在左表中没有匹配行,则将为左表返回空值。 - FULL JOIN 或 FULL OUTER JOIN
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
3. 交叉联接 (基本不使用-得到的是两个表的乘积)
交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
- FROM 子句中的表或视图可通过内联接或完整外部联接按任意顺序指定;但用左或右向外联接指定表或视图时,表或视图的顺序很重要。
- 语法:select * from A,B;
select * from category,product;
4. 例图

5. 自然连接
- 连接查询会产生无用笛卡尔积,常使用主外键关系等式来去除它。而自然连接无需给出主外键等式,会自动找到这一等式:
- 两张连接的表中名称和类型完全一致的列作为条件,例如emp和dept表都存在deptno列,并且类型一致,所以会被自然连接找到!
- 两张连接的表中名称和类型完全一致的列作为条件,例如emp和dept表都存在deptno列,并且类型一致,所以会被自然连接找到!

6. 子查询
将一个查询语句做为一个结果集供其他SQL语句使用,被当作结果集的查询语句被称为子查询。
若结果集为单行单列(标量子查询),则可放在select或where语句中
若结果集为多行单列,可放在where语句中,配合in使用
若结果集中有多行多列(就相当于一个表,派生表),一般作为数据源进行再一次检索。
查询与SCOTT同一个部门的员工
select * from emp where deptno=(select deptno from emp where ename=’SCOTT’);
查询工作和工资与MARTIN完全相同的员工信息
select * from emp where (job,sal) in (select job,sal from emp where ename=’MARTIN’);
查询有2个以上直接下属的员工信息
select * from emp where empno in (select mgr from emp group by mgr having count(mgr)>=2);
查询员工编号为7788的员工名称、员工工资、部门名称、部门地址
select e.ename,e.sal,d.dname,d.loc from emp e,(select dname,loc,deptno from dept) d where e.deptno=d.deptno and e.empno=7788;
7.Union
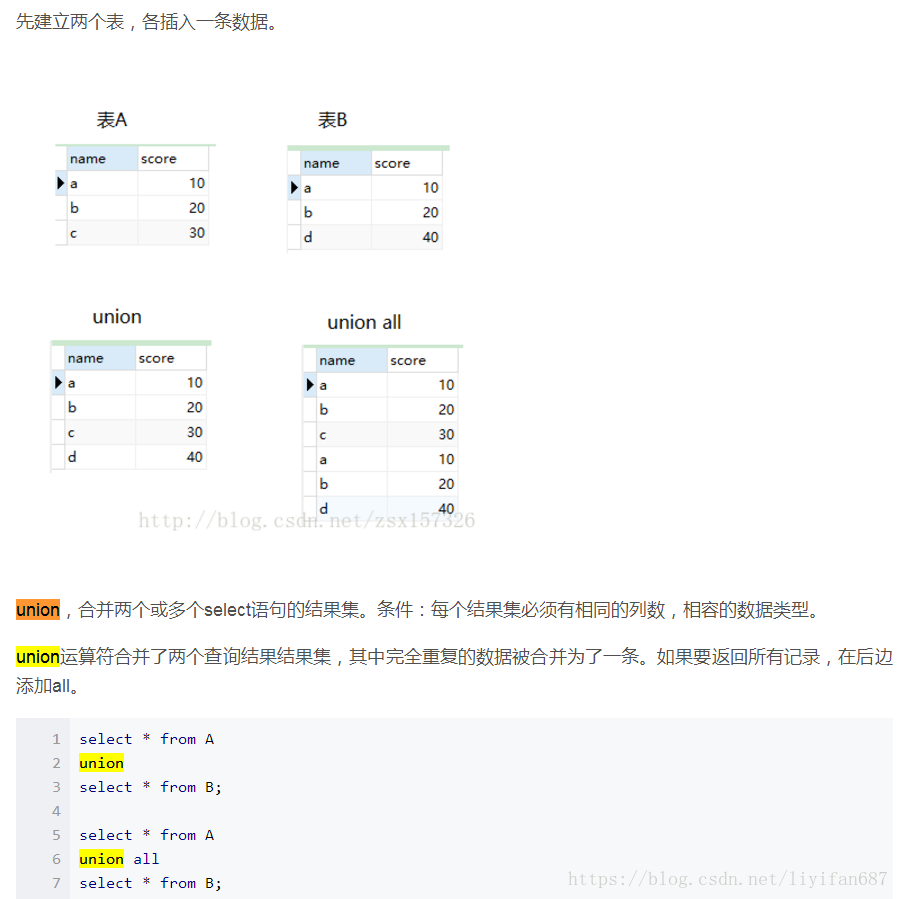
8. 事务的四大特征
数据库事务 transanction 正确执行的四个基本要素。
1. 原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执
行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
2. 一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
3. 隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两事务,运行在相同时间内,执行相同功能,隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为防止事务操作间的混淆, 须串行化或序列化请 求,使得在同一时间仅有一个请求用于同一数据。
4. 持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
8.1. Mysql 中四种隔离级别分别
隔离级别 脏读 不可重复读 幻读
1. Read uncommitted(读未提交) 是 是 是
2. Read committed(读已提交) 否 是 是
3. Repeatable read(可重复读) 否 否 是
4. Serializable(串行读) 否 否 否
- 读未提交(READ UNCOMMITTED):未提交读隔离级别也叫读脏,就是事务可以读取其它事务未提交的数据。
- 读已提交(READ COMMITTED):在其它数据库系统比如 SQL Server 默认的隔离级别就是提交读,已提交读
- 隔离级别就是在事务未提交之前所做的修改其它事务是不可见的。
- 可重复读(REPEATABLE READ):保证同一个事务中的多次相同的查询的结果是一致的,比如一个事务一开始
查询了一条记录然后过了几秒钟又执行了相同的查询,保证两次查询的结果是相同的,可重复读也是 mysql 的默认隔
离级别。 - 可串行化(SERIALIZABLE):可串行化就是保证读取的范围内没有新的数据插入,比如事务第一次查询得到某个
范围的数据,第二次查询也同样得到了相同范围的数据,中间没有新的数据插入到该范围中。
9. 索引
主键索引
ALTER TABLE ‘table_name’ ADD PRIMARY KEY ‘index_name’ (‘column’);
唯一索引
ALTER TABLE ‘table_name’ ADD UNIQUE ‘index_name’ (‘column’);
普通索引
ALTER TABLE ‘table_name’ ADD INDEX ‘index_name’ (‘column’);
全文索引
ALTER TABLE ‘table_name’ ADD FULLTEXT ‘index_name’ (‘column’);
组合索引
ALTER TABLE ‘table_name’ ADD INDEX ‘index_name’ (‘column1’, ‘column2’, …);
10
- 检索出员工工资最高的员工姓名和工资
select * from user where employee_salary= (select max(employee_salary) from user) - 检索出部门中员工最多的部门号和此部门员工数量
select dept_id,count(*) cno from user GROUP BY dept_id desc limit 1