MySQL是一种关系型数据库管理系统
数据库操作
创建数据库:create database 数据库名;
显示已经存在的数据库:show databases;
删除数据库:drop database 数据库名;
(删除数据库会删除数据库中所有的表和表中所有的数据)
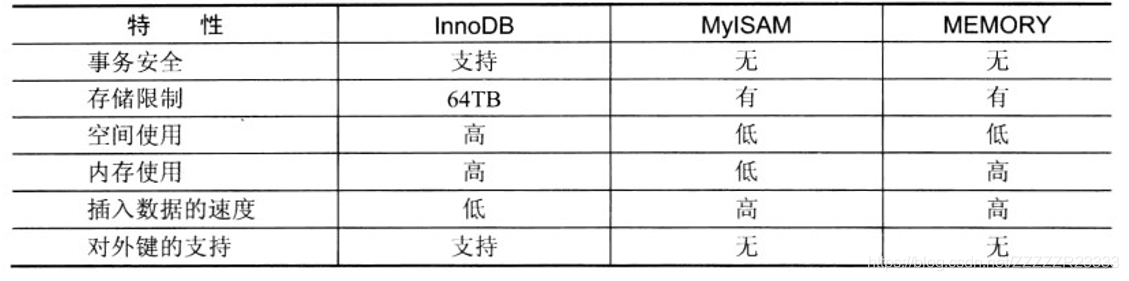
(数据库引擎)
查看数据库支持的引擎:
1.show engines;
2.show variables like ‘have%’;
查看数据库默认引擎:show variables like ‘storage_engine’;
如果想要更改默认引擎,可以在my.ini中更改。
表操作
创建表:

查看表的结构: describe 表名; desc 表名;
查看表详细结构语句: show create table 表名 \G;
(加上\G,显示结果更加美观,尤其适用于内容比较长的记录)
修改表名:alter table 旧表名 rename [to] 新表名;
修改字段的数据类型:alter table 表名 modify 属性名 数据类型;
修改字段名:alter table 表名 change 旧表名 新属性名 新数据类型;
增加字段:alter table 表名 add 属性名1 数据类型 [完整性约束] [first | after 属性名2];
删除字段:alter table 表名 drop 属性名;
删除表的外键约束:alter table 表名 drop foreign key 外键别名;
删除表:drop table 表名;
(如果有此表为父表,需要先删除外键约束)
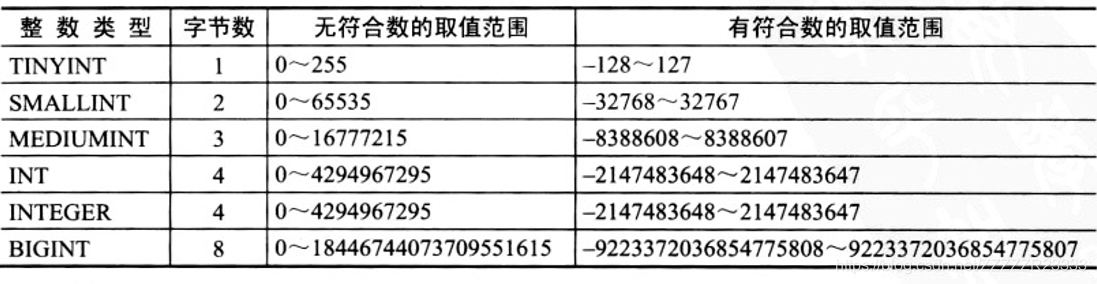
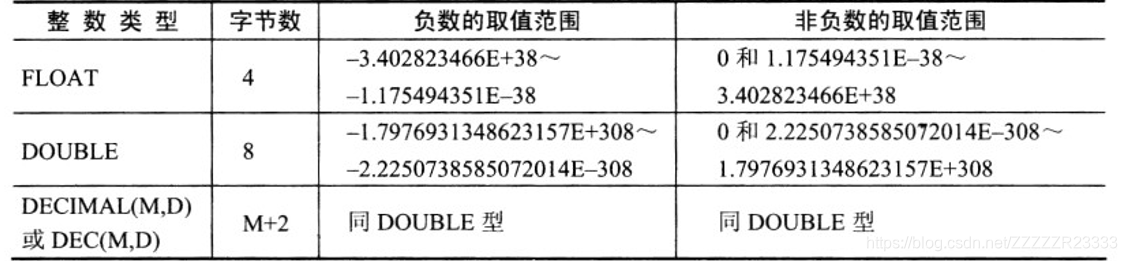
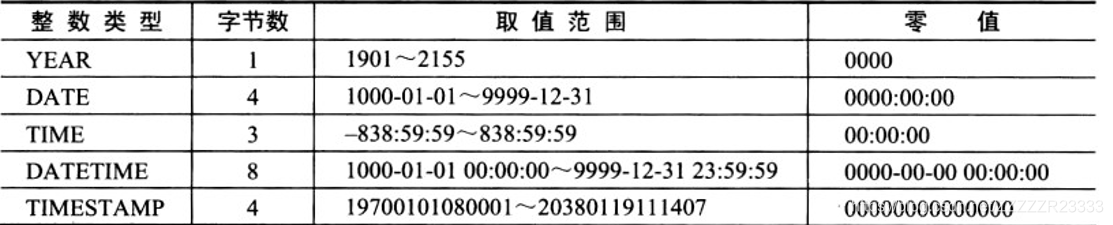
*完整性约束和数据类型

数据类型:包括整数类型,浮点数类型,定点数类型,日期和时间类型,字符串类型和二进制类型。
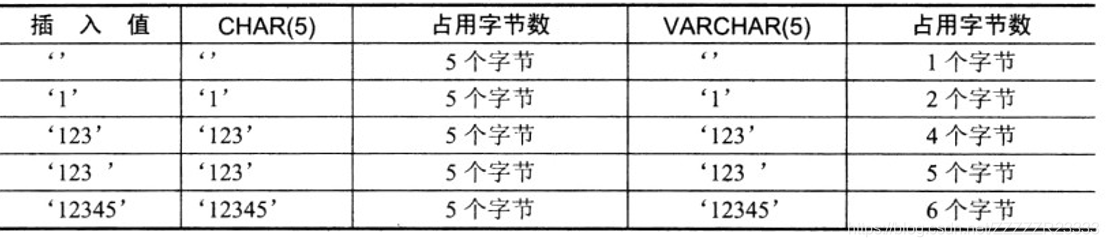
字符串类型是在数据库中存储字符串的数据类型。包括:char,varchar,blob,text,enum和set。
enum类型又称枚举类型,在创建表时,取值范围就以列表的形式指定了。
属性名 enum(‘值1’,‘值2’,…,‘值n’)
数据查询

select * from 表名; “*”表示所有的字段;
where表示查询指定记录,后面加上条件表达式,即可筛选;
#带in关键字的查询
[not] in (元素1,元素2,…,元素n)
in关键字可以判断某个字段的值是否在指定的集合里;
#带between and的范围查询
[not] between 取值1 and 取值2
#带like 的字符串匹配查询
[not] like ‘字符串’
like关键字可以匹配字符串是否相等。
(带有通配符%和_的)
like 'AB%'表示查询以AB开头的记录;
like 'Ar_c’表示查询_为一个字符的且其他与单引号内容一致的记录,如Aric,Arqc…
查询空值
is [not] null 可以用来判断字段的值是否为空值;
多条件查询;
and关键字表示需满足所列条件,or关键字表示满足其一即可;
查询结果不重复: select distinct 属性名;
排序查询结果: order by 属性名 [asc|desc] asc升序 desc降序
分组查询:group by关键字可以将查询结果按某个字段或多个字段进行分组;
group by 属性名 [having 条件表达式] [with rollup]
[with rollup]表示在所有记录最后加上一条所有记录总和的记录
限制查询结果的数量:limit 初始位置,记录数
使用集合函数查询:
count(),sum(),avg(),max(),min()
分别表示统计记录条数,求和函数,求平均值函数,求最 大值函数和求最小值函数。
连接查询:
内连接查询:通过表中相同意义字段来连接表
比如where 表1.属性1=表2.属性1;
外连接查询:

左连接查询和右连接查询

 复合条件查询; 使用多个同时限制查询结果
复合条件查询; 使用多个同时限制查询结果
子查询;
(可带有in,
比较运算符(=,!=,<,>,<>,>=,<=等),
带exists关键字(表示存在),
带any关键字(表示满足其一条件即可),
带all关键字(表示满足所有条件))

合并查询

为表和字段起别名
表名 表的别名
属性名 [as] 别名
插入,更新,删除数据
插入:insert into 表名 values(值1,值2,…,值n);
值按顺序对应表中字段,且数据类型一致;
如果只是指定部分字段,需要在表名后加上(属性1,属性2,…),且值和指定属性顺序数据类型一致;
如果需要插入多条记录,只需将上述对应部分改为values(取值列表1),(取值列表2),…,(取值列表n);
将查询结果插入到表中:

更新数据:


删除数据:

范式
范式:
分类:第一范式,第二范式,第三范式,BC范式,第四范式
主键:能够唯一标识表中的每条数据
多字段主键:因为一个属性无法退出后面非主键属性的值;
应用数据库范式可以带来许多好处,但是最重要的好处归结为三点:
1)减少数据冗余(这是最主要的好处,其他好处都是由此而附带的)
2)消除异常(插入异常,更新异常,删除异常)
3)让数据组织的更加和谐…
!但是数据库范式绝对不是越高越好,范式越高,意味着表越多,多表联合查询的几率就越大,SQL的效率就变低。
注意:一般关系型数据库满足第三范式就可以了!
第一范式:(1NF)
每一列保持原子特性
列都是基本数据项,不能够再进行分割,否则设计成一对多的实体关系。
第二范式:(2NF)
非主属性完全依赖于主键(主要针对联合主键->消除部分依赖)
符合第一范式的基础上,非主属性完全依赖于主关键字,如果不是完全依赖主键,应该拆分成新的实体,设计成一对多的实体关系。
第三范式:(3NF) 属性不依赖于其它非主属性(消除依赖传递)
基于第二范式的基础,非主属性只依赖于主属性
要求一个数据库表中不包含已在其它表中已包含的非主关键字信息
BC范式:(BCNF)
每个表中只有一个候选键,不重复的属性称为候选键
简单的说,BC范式是在第三范式的基础上的一种特殊情况,即每个表中只有一个候选键(在一个数据库中每行的值都不相同,则可称为候选键)
