server处理produce请求
1,概述
在 Producer Client 端,Producer 会维护一个 ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches 的变量,然后会根据 topic-partition 的 leader 信息,将 leader 在同一台机器上的 batch 放在一个 request 中,发送到 server,这样可以节省很多网络开销,提高发送效率。
2,service处理过程
2.1 发送请求
Producer Client 发送请求的方法实现如下:
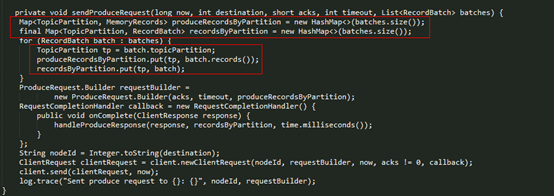
kafka接收到producer请求后,通过其网络模型,最终会交给KafkaApis组件处理
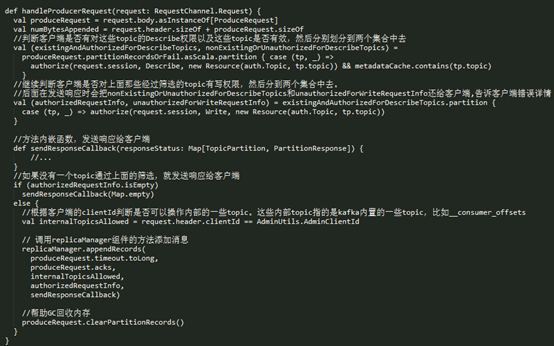
- l 查看 topic 是否存在,以及 client 是否有相应的 Desribe 权限;
- l 对于已经有 Describe 权限的 topic 查看是否有 Write 权限;
- l 调用 replicaManager.appendRecords() 方法向有 Write 权限的 topic-partition 追加相应的 record。
2.2 ReplicaManager
ReplicaManager,副本管理器,作用是管理这台 broker 上的所有副本(replica)。在 Kafka 中,每个副本(replica)都会跟日志实例(Log 对象)一一对应,一个副本会对应一个 Log 对象。
ReplicaManager 的并不负责具体的日志创建,它只是管理 Broker 上的所有分区。在创建 Partition 对象时, Partition 会通过logManager 对象为每个 replica 创建对应的日志。
ReplicaManager拿到请求内容后,主要做了如下事情:
- l 首先判断 acks 设置是否有效(-1,0,1三个值有效),无效的话直接返回异常,不再处理;
- l acks 设置有效的话,调用 appendToLocalLog() 方法将 records 追加到本地对应的 log 对象中;
- l appendToLocalLog() 处理完后,如果发现 clients 设置的 acks=-1,即需要 isr 的其他的副本同步完成才能返回 response,那么就会创建一个 DelayedProduce 对象,等待 isr 的其他副本进行同步,否则的话直接返回追加的结果。
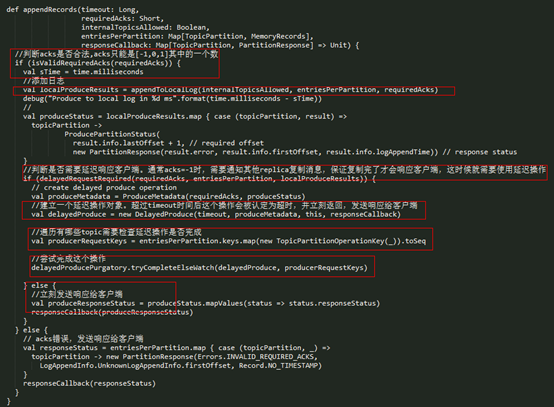
appendToLocalLog() 的实现
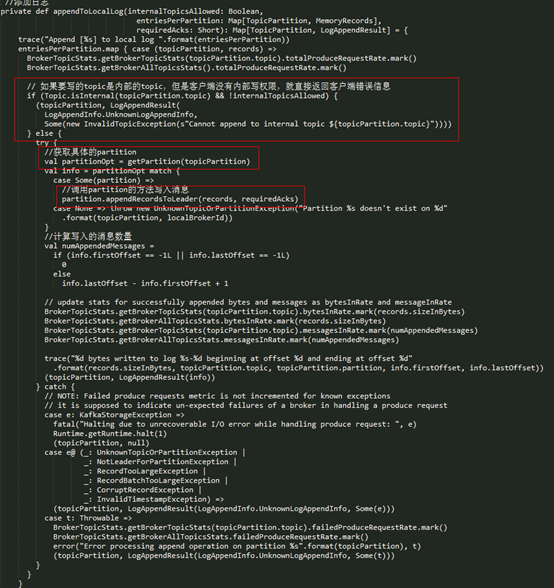
从上面可以看到 appendToLocalLog() 的实现如下:
- l 首先判断要写的 topic 是不是 Kafka 内置的 topic,内置的 topic 是不允许 Producer 写入的;
- l 先查找 topic-partition 对应的 Partition 对象,如果在 allPartitions 中查找到了对应的 partition,那么直接调用 partition.appendRecordsToLeader() 方法追加相应的 records,否则会向 client 抛出异常。
ReplicaManager 在追加 records 时,调用的是 Partition 的 appendRecordsToLeader() 方法,partiton组件是topic在某个broker上一个副本的抽象。每个partition对象都会维护一个Replica对象,Replica对象中又维护Log对象,也就是数据目录的抽象,具体的实现如下:
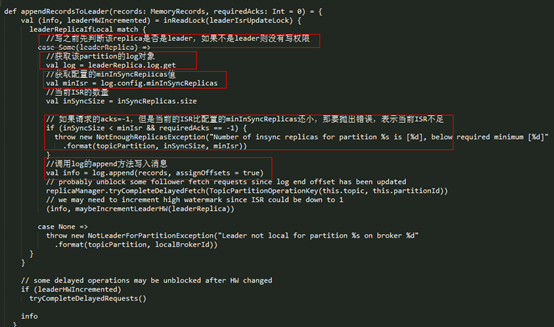
parititon组件从replicaManager拿到消息后
- l 先判断自己是否是leader,只有leader才可以接收producer请求然后写数据
- l 判断当前的当前的ISR数量是否比minInSyncReplicas还小,如果ISR数量小于minInSyncReplicas就抛出异常
- l 把消息交给自己管理的Log组件处理
2.3 Log
Log对象是对partition数据目录的抽象。管理着某个topic在某个broker的一个partition,它可能是一个leader,也可能是replica。同时,Log对象还同时管理着多个LogSegment,也就是日志的分段。
在 Log 对象的初始化时,有三个变量是比较重要的:
- l nextOffsetMetadata:可以叫做下一个偏移量元数据,它包括 activeSegment 的下一条消息的偏移量,该 activeSegment 的基准偏移量及日志分段的大小;
- l activeSegment:指的是该 Log 管理的 segments 中那个最新的 segment(这里叫做活跃的 segment),一个 Log 中只会有一个活跃的 segment,其他的 segment 都已经被持久化到磁盘了;
- l logEndOffset:表示下一条消息的 offset,它取自 nextOffsetMetadata 的 offset,实际上就是活动日志分段的下一个偏移量。

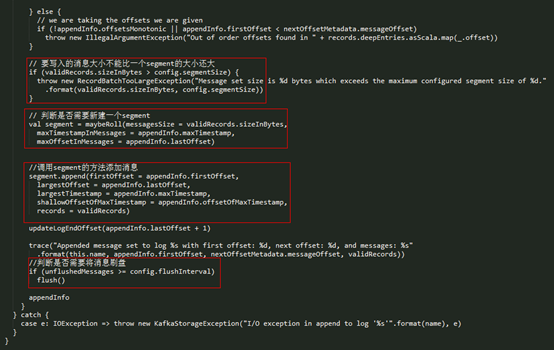
Server 将每个分区的消息追加到日志中时,是以 segment 为单位的,当 segment 的大小到达阈值大小之后,会滚动新建一个日志分段(segment)保存新的消息,而分区的消息总是追加到最新的日志分段(也就是 activeSegment)中。每个日志分段都会有一个基准偏移量(segmentBaseOffset,或者叫做 baseOffset),这个基准偏移量就是分区级别的绝对偏移量,而且这个值在日志分段是固定的。有了这个基准偏移量,就可以计算出来每条消息在分区中的绝对偏移量,最后把数据以及对应的绝对偏移量写到日志文件中。append() 方法的过程可以总结如下:
- l analyzeAndValidateRecords():对这批要写入的消息进行检测,主要是检查消息的大小及 crc 校验;
- l trimInvalidBytes():会将这批消息中无效的消息删除,返回一个都是有效消息的 MemoryRecords;
- l LogValidator.validateMessagesAndAssignOffsets():为每条消息设置相应的 offset(绝对偏移量) 和 timestrap;
- l maybeRoll():判断是否需要新建一个 segment 的,如果当前的 segment 放不下这批消息的话,需要新建一个 segment;
- l segment.append():向 segment 中添加消息;
- l 更新 logEndOffset 和判断是否需要刷新磁盘(如果需要的话,调用 flush() 方法刷到磁盘)。
- 关于 timestrap 的设置,这里也顺便介绍一下,在新版的 Kafka 中,每条 msg 都会有一个对应的时间戳记录,producer 端可以设置这个字段 message.timestamp.type 来选择 timestrap 的类型,默认是按照创建时间,只能选择从下面的选择中二选一:
- l CreateTime,默认值;
- l LogAppendTime。
在 Log 的 append() 方法中,会调用 maybeRoll() 方法来判断是否需要进行相应日志分段操作,其具体实现如下:
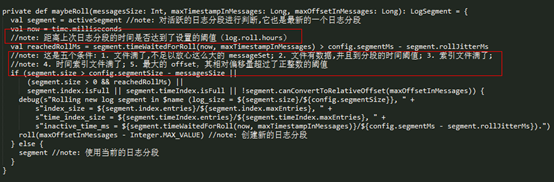
从 maybeRoll() 的实现可以看到,是否需要创建新的日志分段,有下面几种情况:
- l 当前日志分段的大小加上消息的大小超过了日志分段的阈值(log.segment.bytes);
- l 距离上次创建日志分段的时间达到了一定的阈值(log.roll.hours),并且数据文件有数据;
- l 索引文件满了;
- l 时间索引文件满了;
- l 最大的 offset,其相对偏移量超过了正整数的阈值。
创建一个 segment 对象,真正的实现是在 Log 的 roll() 方法中,创建 segment 对象,主要包括三部分:数据文件、offset 索引文件和 time 索引文件。
2.4 offset索引文件
这里顺便讲述一下 offset 索引文件,Kafka 的索引文件有下面几个特点:
- l 采用 绝对偏移量+相对偏移量 的方式进行存储的,每个 segment 最开始绝对偏移量也是其基准偏移量;
- l 数据文件每隔一定的大小创建一个索引条目,而不是每条消息会创建索引条目,通过
index.interval.bytes来配置,默认是 4096,也就是4KB; - 这样做的好处也非常明显:
- l 因为不是每条消息都创建相应的索引条目,所以索引条目是稀疏的;
- l 索引的相对偏移量占据4个字节,而绝对偏移量占据8个字节,加上物理位置的4个字节,使用相对索引可以将每条索引条目的大小从12字节减少到8个字节;
- l 因为偏移量有序的,再读取数据时,可以按照二分查找的方式去快速定位偏移量的位置;
- l 这样的稀疏索引是可以完全放到内存中,加快偏移量的查找。
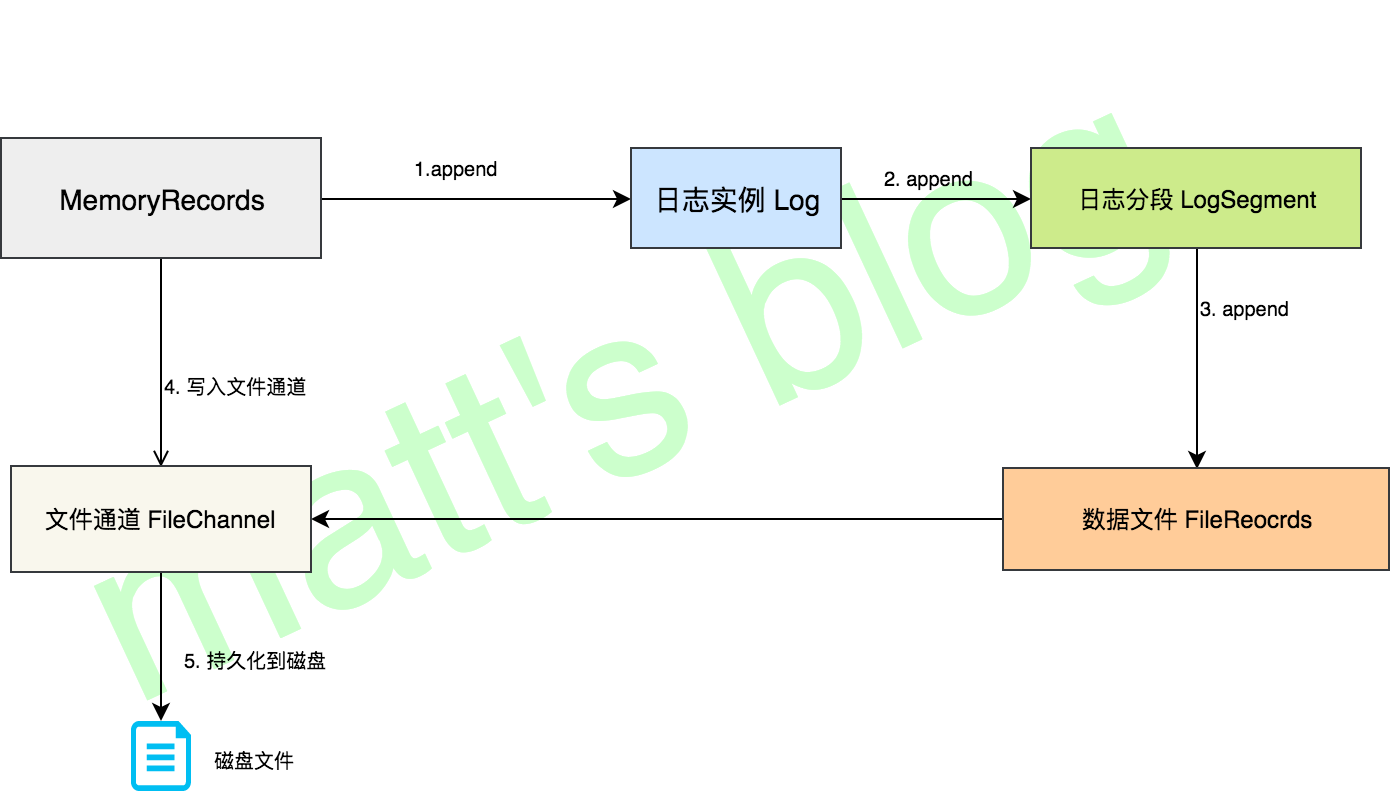
2.5LogSegment写入
真正的日志写入,还是在 LogSegment 的 append() 方法中完成的,LogSegment 会跟 Kafka 最底层的文件通道、mmap 打交道。
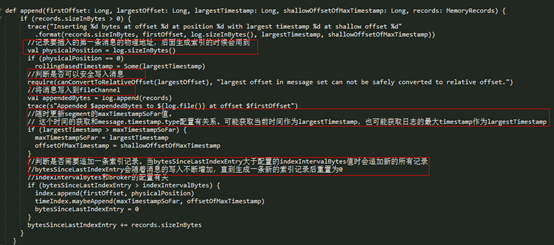
- l logSegment底层使用了fileChannel写日志,写完之后还会判断是否要更新当前logSegment的最大时间戳
- l 每当写入消息的大小积累到一定程度时,会新插入一条索引记录。这个积累的大小和配置index.interval.bytes有关系
kafka底层的写数据是根据fileChannel来写的,它写的时候不会立刻刷盘,而是开启了一个定时任务根据策略去刷盘。但是在默认情况下,这个定时任务又是不刷盘的(刷盘策略都不满足),kafka把刷盘的时机交给操作系统来掌控。
{kind=link}

3参考资料:
https://blog.csdn.net/u013332124/article/details/82778419
http://matt33.com/2018/03/18/kafka-server-handle-produce-request/