Log管理机制
Kafka的消息在broker上都是以log的形式进行储存管理的,本篇主要介绍log的管理,包括log结构、创建、读写、分段、清理等。
1 前言
Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个partition存储一部分Message。引用官方的一张图,可以直观地看到topic和partition的关系。
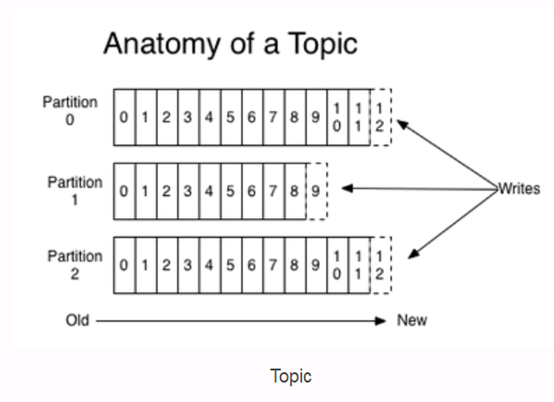
2 Kakfa的日志格式
2.1Partition的数据文件
Partition中的每条Message由offset来表示它在这个partition中的偏移量,这个offset不是该Message在partition数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了partition中的一条Message。因此,可以认为offset是partition中Message的id。partition中的每条Message包含了以下三个属性:
- l offset
- l MessageSize
- l Record
- l 其中offset为long型,MessageSize为int32,表示Record中data
有多大,data为message的具体内容。
在v0版本中,kafka的消息格式如下图所示:

在V1版本中,kakfa的消息格式如下图所示:
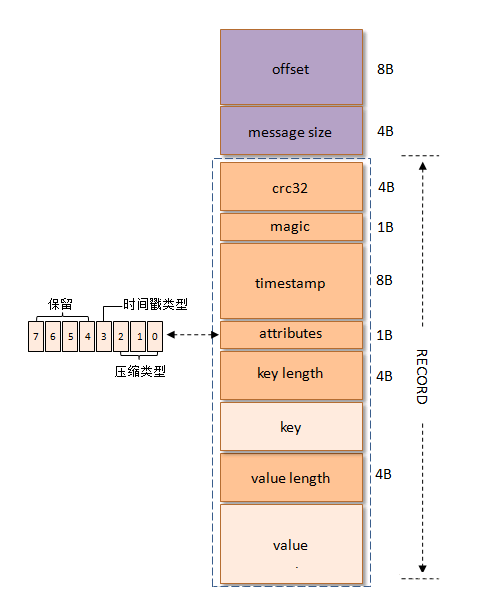
V2版本

具体可以参考下文
http://www.uml.org.cn/bigdata/2018051731.asp
2.2 Log的分段和索引
数据文件的分段
Kafka解决查询效率的手段之一是将数据文件分段,比如有100条Message,它们的offset是从0到99。假设将数据文件分成5段,第一段为0-19,第二段为20-39,以此类推,每段放在一个单独的数据文件里面,数据文件以该段中最小的offset命名。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。
为数据文件建索引
数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引。索引包含两个部分(均为4个字节的数字),分别为相对offset和position。
相对offset:因为数据文件分段以后,每个数据文件的起始offset不为0,相对offset表示这条Message相对于其所属数据文件中最小的offset的大小。举例,分段后的一个数据文件的offset是从20开始,那么offset为25的Message在index文件中的相对offset就是25-20 = 5。存储相对offset可以减小索引文件占用的空间。
position,表示该条Message在数据文件中的绝对位置。只要打开文件并移动文件指针到这个position就可以读取对应的Message了。
index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
2.3 log的逻辑结构
- l 一个Partition Log由多个LogSegment组成
- l 一个LogSegment代表了整个Partition Log中的某一段,它是由一个FileMessageSet和一个OffsetIndex组成
- l FileMessageSet:顾名思义,它代表了一个基于文件的消息集合。内部采用channel方式访问物理文件。
- l OffsetIndex:可以将其看做一个index table, 每一项代表了一个offset 与 物理文件(.log 文件)position的映射。此外它会与实际的物理文件(.index) 之间是建立的 mmap。
- l 每一个Partition Log有一个nextOffsetMetadata 记录,用于记录下一个要添加的messageset的offset
- l 每一个Log都有一个recoverypoint,用于记录真正flush到磁盘的消息的最后一个offset
2.4 log的物理结构
下面是一个kafka log dir下的文件分布:
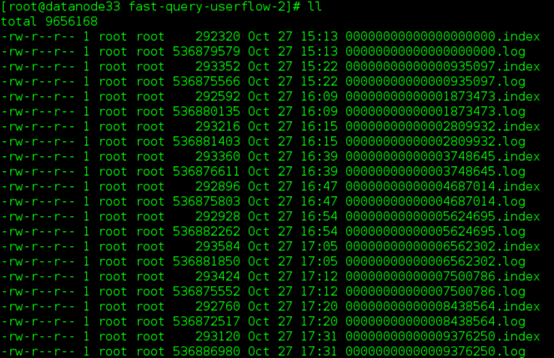
1)一个Partition Log 对应于一个kafka broker 的log dir下面的一个分区目录。
2)一个LogSegment对应了partition log directoy下的两个文件:一个.log文件,一个.index文件。

3 kafka 的日志管理
在一个broker上的log都是通过LogManger来管理的,Kafka 的日志管理(LogManager)主要的作用是负责日志的创建、检索、清理,日志相关的读写操作实际上是由日志实例对象(Log)来处理的。
3.1 LogManger启动过程
LogManager 线程是在节点的 Kafka 服务启动时启动的,相关代码如下:

初始化 LogManger 主要有两个步骤:
- 创建指定的数据目录,并做相应的检查:
- l 确保数据目录中没有重复的数据目录
- l 数据目录不存在的话就创建相应的目录;
- l 检查每个目录路径是否是可读的;
- 加载所有的日志分区,而每个日志也会加载该分区所有的 segment 文件,过程比较慢,所以 LogManager 使用线程池的方式,为每个日志的加载都会创建一个单独的线程。
虽然使用的是线程池提交任务,并发进行 load 分区日志,但这个任务本身是阻塞式的,只有当所有的分区日志加载完成,才能调用 startup() 启动 LogManager 线程。
KafkaServer 调用 startup() 方法启动 LogManager 线程,LogManager 启动后,后台会运行四个定时任务,代码实现如下:

四个后台定时线程的作用:
- l cleanupLogs:定时清理过期的日志 segment,并维护日志的大小(默认5min);
- l flushDirtyLogs:定时刷新将还没有写到磁盘上日志刷新到磁盘(默认 无限大);
- l checkpointRecoveryPointOffsets:定时将所有数据目录所有日志的检查点写到检查点文件中(默认 60s);
- l deleteLogs:定时删除标记为 delete 的日志文件(默认 30s)。
3.2 日志压缩
第一种:delete,即如果LogSegment到期了删除之,或者LogSegment+这次要添加的消息 > LogSegment的最大容量则删除最老的的LogSegment
第二种:compact,进行log压缩,也可以有效减少日志文件文件大小,缓解磁盘紧张情况。
在有些场景中,key和对应的value的值是不断变化的,就像数据库的记录一样,可以对同一条记录进行修改,在kafka中表现就是在某一时刻key=value1,可能在后续某一时刻,添加了一个key=value2的消息,如果消费者只关心最新的值,那么日志压缩就显得很有用,如下图所示:
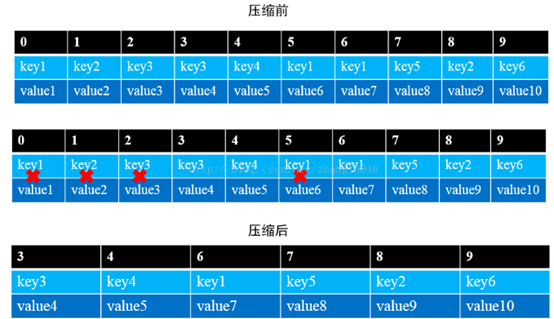
- l # 如果启用日志压缩,并不会针对active log segment,即active log segment不会参加日志压缩,只是针对只读的log segment,避免active log segment成为热点,既要读写还要压缩
- l # 日志压缩的过程是通过多个cleaner线程来完成的,所以我们可以通过调整cleaner线程数来并发压缩性能,减少对整个服务器端的影响
- l # 一般情况下,Log数据量很大,为了避免cleaner线程和其他业务线程长时间竞争CPU,并不会将active log segment之外的其他可读LogSegment在一次压缩中全部处理掉,而是将这些LogSegment分批处理
- l 每一个log都会被cleanercheckpoint分成clean和dirty2部分,如下图所示:
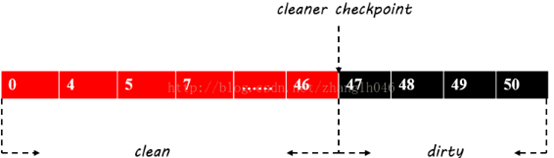
clean: 表示已经压缩的部分,压缩之后,offset是断断续续的,不是增量递增的
dirty: 表示未压缩部分,offset依然是连续递增的
- l # 每一个clean线程根据日志文件cleanableRatio值来优先压缩该值较效的log,也就说dirty占整个日志的比率越大优先级越高。
- l # clean线程在选定需要清理的log后,首先为dirty部分消息建立一个<key,key对应的last offset>的映射关系,该映射通过SkimpyOffsetMap维护,然后重新复制LogSegment,只保留SkimpyOffsetMap中记录的消息,抛弃掉其他消息
- l # 经过日志压缩后,日志文件和索引文件会不断减小,cleaner线程还会对相邻的LogSegmeng进行合并,避免出现过小的日志和索引文件
参考资料:
https://www.codetd.com/article/1652292
https://segmentfault.com/a/1190000005312891
https://blog.csdn.net/zhanglh046/article/details/72821483
https://blog.csdn.net/wl044090432/article/details/51008093
https://blog.csdn.net/jewes/article/details/42970799
http://www.uml.org.cn/bigdata/2018051731.asp
https://www.cnblogs.com/devos/p/5100611.html
---------------------
作者:happy19870612
来源:CSDN
原文:https://blog.csdn.net/zhanglh046/article/details/72821483
版权声明:本文为博主原创文章,转载请附上博文链接!