Hadoop部署一主一从(2)
1.关闭防火墙和Linux守护进程
执行命令:
iptables -F
setenforce 02.对Hadoop集群进行初始化,在namenode(主机)上执行命令
hdfs namenode -format
3.启动Hadoop,在namenode(主机)上执行如下命令
start-all.sh
4.主机和从机执行命令jps,检查集群是否正常启动,结果如图
主机:
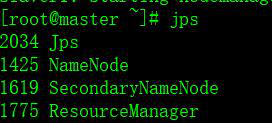
从机:

5.对Hadoop进行一些简单的操作处理:
在hdfs上创建一个bigdata目录,并向目录中上传一个wordcount_test文件
hadoop fs -mkdir /bigdata
hadoop fs -put /root/wordcount_test /bigdata6.利用Hadoop的shell接口执行Wordcount
hadoop jar /root/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /bigdata/wordcount_test /output备注:1 /output这个文件输出目录一定不能提前创建,否则会报错
2 执行wordcount要分配足够内存,不然会卡死(我分配了4G),这个在yarn-site.xml这个文件中配置,否则会卡死,如下所示:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>7.查看是否执行成功
执行命令hadoop fs -ls /output

8.查看执行结果
执行命令hadoop fs -cat /output/part-r-00000

至此,Hadoop搭建已全部完成,而且利用Hadoop完成了一个简单的Wordcount小程序。
总结:
防火墙一定要提前关闭,不然向hdfs上传文件会报错。
一定要分配足够的内存,否则执行MapReduce会卡死。