分布式流处理平台,是一个分布式消息中间件系统。
一、jms
1、什么是jms
java message service(java 消息服务):java程序需要异步发送消息的时候使用的服务。
用于异构系统之间的通信。
middleware,中间件,提供消息服务,部件之间的交互通过中间件完成,部件之间互为生产者和消费者,
3、什么时候可以用到java消息机制?
答:(1)异构系统集成,整合现有资源,提高资源的利用率
(2)异步请求处理,减轻或消除系统瓶颈,提高用户生产率和系统的整体可伸缩性
(3)组件解偶,增加系统的灵活性
4、消息传送的两种模型
不同的消息系统提供不同的消息路由模式,通用的目的地有两个:队列和主题
点对点模型(point-2-pint<P2P>)
这个模式中涉及到的角色:发送者、接收者、消息队列(远程队列)
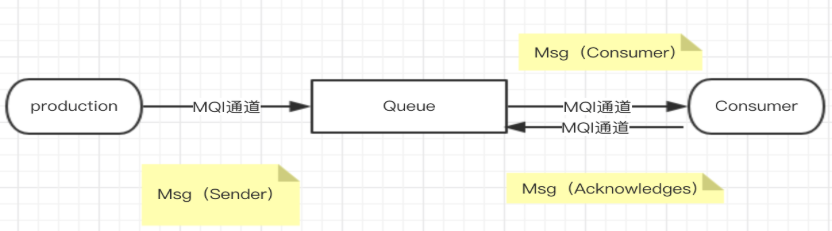
客户端通过队列(queue)这个虚拟通道来同步和异步发送、接收消息,发送到队列的消息只能被一个接收者所接收,即使有多个消费者时也只能有一个消费者处理消息。生产者和消费者之间没有依赖,生产者只需要把消息丢到远程队列;消费者从队列获取消息,即队列中的消息只有在被消费或者超时时才会被销毁。
发布/订阅模型(publish/Subsrcibe<pub/sub>)
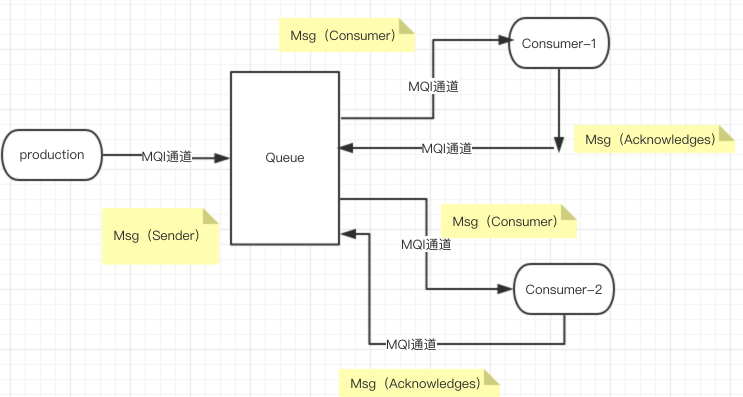
这个模式中涉及到的角色:发布者、订阅者、主题Topic(模板队列+动态队列)
客户端发送消息到一个名为主题(topic)的虚拟通道中,每个订阅该主题的消费者都会接收到每条消息的一个副本。
一个生产者对应多个消费者,即一条消息可以被多次消费;
默认情况下,生产者生产消息时,消费者必须在线消费,即发布主题时,订阅者必须在线监听;
为了接触订阅模式中消费者与主题的时间耦合,jms提供持久化订阅,针对某些特定的订阅者,topic会缓存消息至订阅者消费或消息超时。
queue: 只能有一个消费者,p2p模式(点对点),一个消息进来只能有一个消费者
topic:发布订阅模式(pub-sub,主题模式),消息发送给主题,一个消息多个消费者
二、kafaka
2-1几个概念
consumer //消息消费者
consumer group //消费者组
broker kafka server,kafka服务器
topic //主题,副本数,分区
partitions //一个主题可以划分多个 分区.
kafka的集群通过zk协调,zookeeper //hadoop namenoade + RM HA | hbase | kafka
(1)
Broker:消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群;
(2) Topic:主题是对一组消息的抽象分类,比如例如page view日志、click日志等都可以以topic的形式进行抽象划分类别。在物理上,不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可使得数据的生产者或消费者不必关心数据存于何处;
(3) Partition:每个主题又被分成一个或者若干个分区(Partition)。每个分区在本地磁盘上对应一个文件夹,分区命名规则为主题名称后接“—”连接符,之后再接分区编号,分区编号从0开始至分区总数减-1;
(4) LogSegment:每个分区又被划分为多个日志分段(LogSegment)组成,日志段是Kafka日志对象分片的最小单位;LogSegment算是一个逻辑概念,对应一个具体的日志文件(“.log”的数据文件)和两个索引文件(“.index”和“.timeindex”,分别表示偏移量索引文件和消息时间戳索引文件)组成;
(5) Offset:每个partition中都由一系列有序的、不可变的消息组成,这些消息被顺序地追加到partition中。每个消息都有一个连续的序列号称之为offset—偏移量,用于在partition内唯一标识消息(并不表示消息在磁盘上的物理位置);
(6) Message:消息是Kafka中存储的最小最基本的单位,即为一个commit log,由一个固定长度的消息头和一个可变长度的消息体组成;
-----参考------
(2) Topic:主题是对一组消息的抽象分类,比如例如page view日志、click日志等都可以以topic的形式进行抽象划分类别。在物理上,不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可使得数据的生产者或消费者不必关心数据存于何处;
(3) Partition:每个主题又被分成一个或者若干个分区(Partition)。每个分区在本地磁盘上对应一个文件夹,分区命名规则为主题名称后接“—”连接符,之后再接分区编号,分区编号从0开始至分区总数减-1;
(4) LogSegment:每个分区又被划分为多个日志分段(LogSegment)组成,日志段是Kafka日志对象分片的最小单位;LogSegment算是一个逻辑概念,对应一个具体的日志文件(“.log”的数据文件)和两个索引文件(“.index”和“.timeindex”,分别表示偏移量索引文件和消息时间戳索引文件)组成;
(5) Offset:每个partition中都由一系列有序的、不可变的消息组成,这些消息被顺序地追加到partition中。每个消息都有一个连续的序列号称之为offset—偏移量,用于在partition内唯一标识消息(并不表示消息在磁盘上的物理位置);
(6) Message:消息是Kafka中存储的最小最基本的单位,即为一个commit log,由一个固定长度的消息头和一个可变长度的消息体组成;
来源:简书
作者:癫狂侠
链接:https://www.jianshu.com/p/3e54a5a39683
链接:https://www.jianshu.com/p/3e54a5a39683
2-2 Kafka的使用场景:
两个需要通信的系统中,如果数据生产者和消费者之间的速度差异大,可以通过kafka作为中间件,削峰。
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
三、部署及使用
3-1下载,解压,放到集群所有机器上。
3-2配置$kafka_home/config/server.properties:
修改其中broker.id log.dir zookeeper.connect等。<参考:
https://blog.csdn.net/lizhitao/article/details/25667831>
3-3 启动kafka
进入kafka目录,敲入命令
创建主题:
./kafka-topics.sh --create --zookeeper localhost:2181,localhost:2182,localhost:2183 --replication-factor 1 --partitions 1 --topic test1
查看主题:
./kafka-topics.sh --list --zookeeper localhost:2181,localhost:2182,localhost:2183
四、Java API
https://www.cnblogs.com/zhangchao0515/p/9502843.html
4-1 生产者
4-2 消费者
消息消费者 -------------------- /** * 消费者 */ @Test public void testConumser(){ // Properties props = new Properties(); props.put("zookeeper.connect", "s202:2181"); props.put("group.id", "g3"); props.put("zookeeper.session.timeout.ms", "500"); props.put("zookeeper.sync.time.ms", "250"); props.put("auto.commit.interval.ms", "1000"); props.put("auto.offset.reset", "smallest"); //创建消费者配置对象 ConsumerConfig config = new ConsumerConfig(props); // Map<String, Integer> map = new HashMap<String, Integer>(); map.put("test3", new Integer(1)); Map<String, List<KafkaStream<byte[], byte[]>>> msgs = Consumer.createJavaConsumerConnector(new ConsumerConfig(props)).createMessageStreams(map); List<KafkaStream<byte[], byte[]>> msgList = msgs.get("test3"); for(KafkaStream<byte[],byte[]> stream : msgList){ ConsumerIterator<byte[],byte[]> it = stream.iterator(); while(it.hasNext()){ byte[] message = it.next().message(); System.out.println(new String(message)); } } }
消息消费者
--------------------
/**
* 消费者
*/
@Test
public void testConumser(){
//
Properties props = new Properties();
props.put("zookeeper.connect", "s202:2181");
props.put("group.id", "g3");
props.put("zookeeper.session.timeout.ms", "500");
props.put("zookeeper.sync.time.ms", "250");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
//创建消费者配置对象
ConsumerConfig config = new ConsumerConfig(props);
//
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("test3", new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> msgs = Consumer.createJavaConsumerConnector(new ConsumerConfig(props)).createMessageStreams(map);
List<KafkaStream<byte[], byte[]>> msgList = msgs.get("test3");
for(KafkaStream<byte[],byte[]> stream : msgList){
ConsumerIterator<byte[],byte[]> it = stream.iterator();
while(it.hasNext()){
byte[] message = it.next().message();
System.out.println(new String(message));
}
}
}